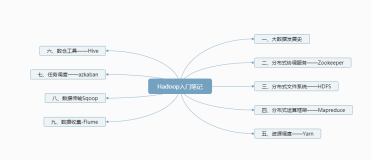
一、HDFS
1、概述
2、Hadoop文件系统

3、特性
4、局限性
5、体系结构
5.1 块
5.2 NameNode和DataNode
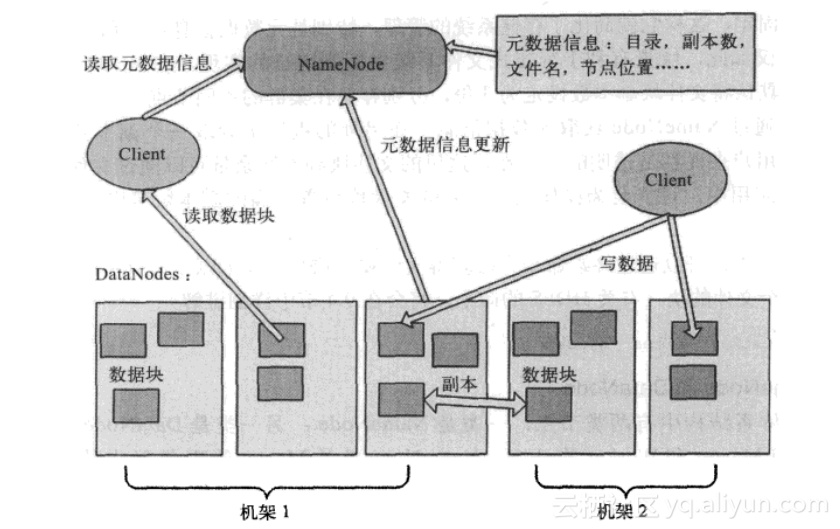
5.3 副本的存放与读取策略
5.4 安全模式
5.5 文件安全(保障NameNode)
5.6 HDFS HA(NameNode可高可用)
6、HDFS中的读写数据流
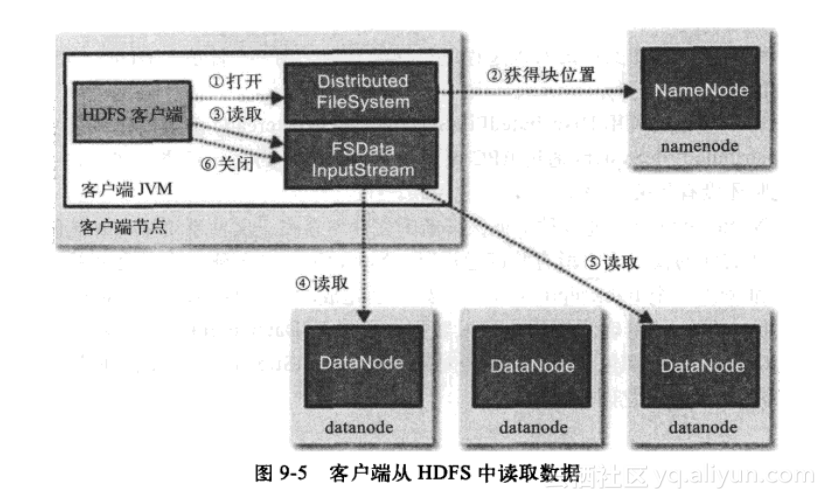
6.1 读取流程
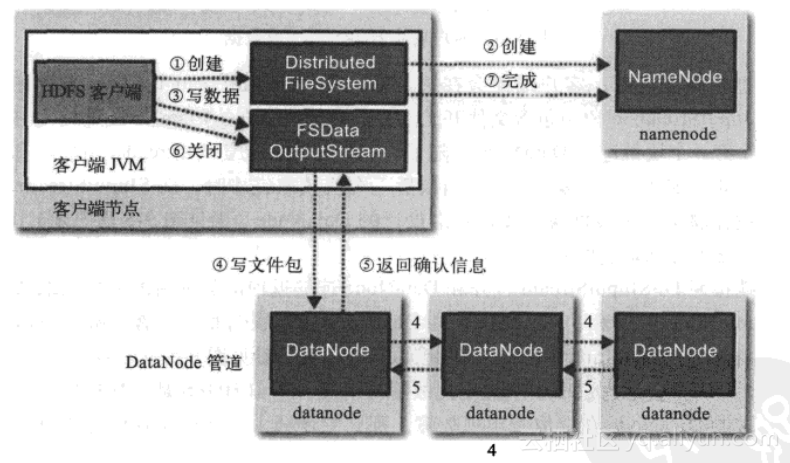
6.2 写入流程
6.3 一致性模型
7、I/O操作中的数据检查
8、HDFS文件结构
8.1 NameNode
${dfs.name.dir}/current/VERSION
/edits
/fsimage
/fstime(1)VERSION
#Wed Mar 23 16:03:27 CST 2011
namespaceID=123456789 //文件系统唯一标识符,DataNode要保持一致
cTime=0 //标记NameNode存储空间创建的时间
storageType=NAME_NODE //指出此存储目录包含一个NameNode的数据结构
layoutVersion=-18 //定义了HDFS持久化数据结构的版本(2)edits(编辑日志)
fsimage文件没有记录块存储在哪个数据节点,而是将这种映射保存在内存中,由DataNode来给NameNode汇报自身包含的块列表。
(4)fstime(存储检查点更新时间)
存储检查点更新时间。检查点可以看作是某一个时间点的fsimage。第二名称节点负责维护更新名称节点中的edits和fsimage文件。第二名称节点从名称节点取得edits和fsimage文件,并合并生成新的fsimage文件再发给名称节点,名称节点并启用新的edits文件。
8.2 Secondary NameNode
${fs.checkpoint.dir}/current/VERSION
/edits
/fsimage
/fstime
/previous.checkpoint/VERSION
/edits
/fsimage
/fstimeprevious.checkpoint目录存储上一次生成的检查点,此目录为备份目录,它的目录布局与名称节点的布局完全一样。
8.3 DataNode数据节点
关键的文件和目录如下:
${dfs.data.dir}/current/VERSION
/blk_<id_1>
/blk_<id_1>.meta
/blk_<id_2>(块本身,块数据)
/blk_<id_2>.meta(块的元数据)
......
/blk_<id_64>
/blk_<id_64>.meta
/subdir0/(当块太多时,新建一个子目录,默认块数达到64时)
/subdir1/
....
/subdir63/数据节点的VERSION文件跟名称节点的VERSION文件十分类似:
#Tue Mar 10 21:32:21 GMT 2009
namespaceID=123456789
storageID=DS-547717739-172.16.85.1-50010-1236720751627
cTime=0
storageType=DATA_NODE
layoutVersion=-189、SequenceFile和MapFile
9.1 SequenceFile
SequenceFile可通过如下API来完成新记录的添加操作:
fileWriter.append(key,value);可以看到,每条记录以键值对的方式进行组织,但前提是Key和Value需具备序列化和反序列化的功能
Hadoop预定义了一些Key Class和Value Class,他们直接或间接实现了Writable接口,满足了该功能,包括:
| Text | 等同于java中的String |
| IntWritable | 等同于Java中的Int |
| BooleanWritable |
等同于Java中的Boolean |
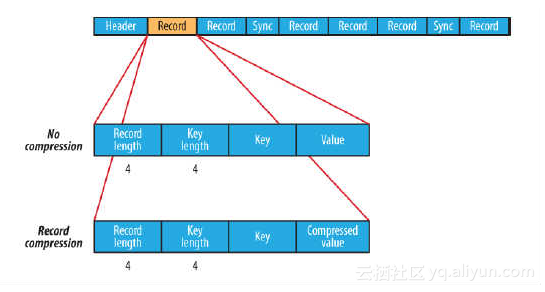
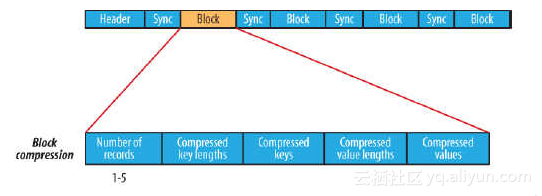
9.2 MapFile
(2)index作为文件的数据索引,主要记录了每个Record的key值,以及该Record在文件中的偏移位置。在MapFile被访问的时候,索引文件会被加载到内存,通过索引映射关系可迅速定位到指定Record所在文件位置,因此,相对SequenceFile而言,MapFile的检索效率是高效的,缺点是会消耗一部分内存来存储index数据。
(3)MapFile并不会把所有Record都记录到index中去,默认情况下每隔128条记录存储一个索引映射。当然,记录间隔可人为修改,通过MapFIle.Writer的setIndexInterval()方法,或修改io.map.index.interval属性;
(4)与SequenceFile不同的是,MapFile的KeyClass一定要实现WritableComparable接口,即Key值是可比较的。
注意:使用MapFile或SequenceFile虽然可以解决HDFS中小文件的存储问题,但也有一定局限性,如:
a、文件不支持复写操作,不能向已存在的SequenceFile(MapFile)追加存储记录
b、当write流不关闭的时候,没有办法构造read流。也就是在执行文件写操作的时候,该文件是不可读取的
二、YARN
1、MapReduce局限性
2、YARN的架构
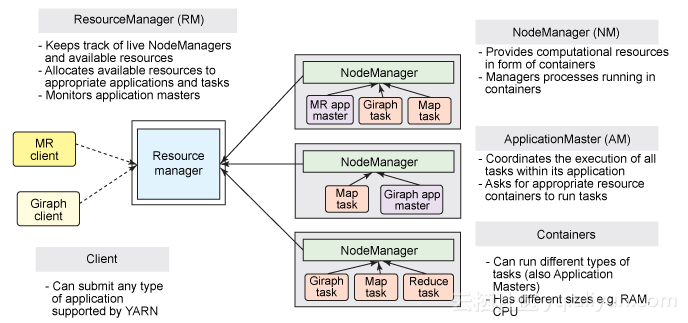
在 YARN 架构中,一个全局 ResourceManager 以主要后台进程的形式运行,它通常在专用机器上运行,在各种竞争的应用程序之间仲裁可用的集群资源。ResourceManager 会追踪集群中有多少可用的活动节点和资源,协调用户提交的哪些应用程序应该在何时获取这些资源。ResourceManager 是惟一拥有此信息的进程,所以它可通过某种共享的、安全的、多租户的方式制定分配(或者调度)决策(例如,依据应用程序优先级、队列容量、ACLs、数据位置等)。
在用户提交一个应用程序时,一个称为 ApplicationMaster 的轻量型进程实例会启动来协调应用程序内的所有任务的执行。这包括监视任务,重新启动失败的任务,推测性地运行缓慢的任务,以及计算应用程序计数器值的总和。这些职责以前分配给所有作业的单个 JobTracker。ApplicationMaster 和属于它的应用程序的任务,在受 NodeManager 控制的资源容器中运行。
NodeManager 是 TaskTracker 的一种更加普通和高效的版本。没有固定数量的 map 和 reduce slots,NodeManager 拥有许多动态创建的资源容器。容器的大小取决于它所包含的资源量,比如内存、CPU、磁盘和网络 IO。目前,仅支持内存和 CPU (YARN-3)。未来可使用 cgroups 来控制磁盘和网络 IO。一个节点上的容器数量,由配置参数与专用于从属后台进程和操作系统的资源以外的节点资源总量(比如总 CPU 数和总内存)共同决定。
有趣的是,ApplicationMaster 可在容器内运行任何类型的任务。例如,MapReduce ApplicationMaster 请求一个容器来启动 map 或 reduce 任务,而 Giraph ApplicationMaster 请求一个容器来运行 Giraph 任务。您还可以实现一个自定义的 ApplicationMaster 来运行特定的任务,进而发明出一种全新的分布式应用程序框架,改变大数据世界的格局。您可以查阅 Apache Twill,它旨在简化 YARN 之上的分布式应用程序的编写。
在 YARN 中,MapReduce 降级为一个分布式应用程序的一个角色(但仍是一个非常流行且有用的角色),现在称为 MRv2。MRv2 是经典 MapReduce 引擎(现在称为 MRv1)的重现,运行在 YARN 之上。
3、使用YARN的好处
在 MR1 中,job 的复杂的状态的改变都发生在 jobtracker 中的内存中,一旦 jobtracker 坏了,就很难再恢复。
而在 YARN 里,jobtracker 的职责分给了 resource manager 和 application master。这样可以为两个组件分别提供高可用。对每个组件发生的错误分别处理,互相不影响。
(3)资源利用率高
在 MR1 中, 每一个 tasktracker 在配置阶段会固定的为 map 或者 reduce task 静态的分配资源,也就是 “槽”。因为每个应用程序所需要的资源并不是完全一样,这样有时会造成资源分配过大,资源浪费,资源分配过小,会导致任务失败。
在 YARN 中,资源由 resource manager 管理,应用程序会请求他所需要的资源。
(4)多应用
YARN 中最大的好处就是可以在其上开启除 Mapreduce 之外的分布式应用程序,比如 Spark。
也可能为用户在一个 YARN 上运行不同版本的 MapReduce。
4、YARN 与 MapReduce 1 对应组件

5、调度器