提示:在阅读本文前,最好先阅读《Spark2.1.0之初识Spark》、《Spark2.1.0之基础知识》及《Spark2.1.0之模块设计》
Spark编程模型
正如Hadoop在介绍MapReduce编程模型时选择word count的例子,并且使用图形来说明一样,笔者对于Spark编程模型也选择用图形展现。
Spark 应用程序从编写到提交、执行、输出的整个过程如图2-5所示。
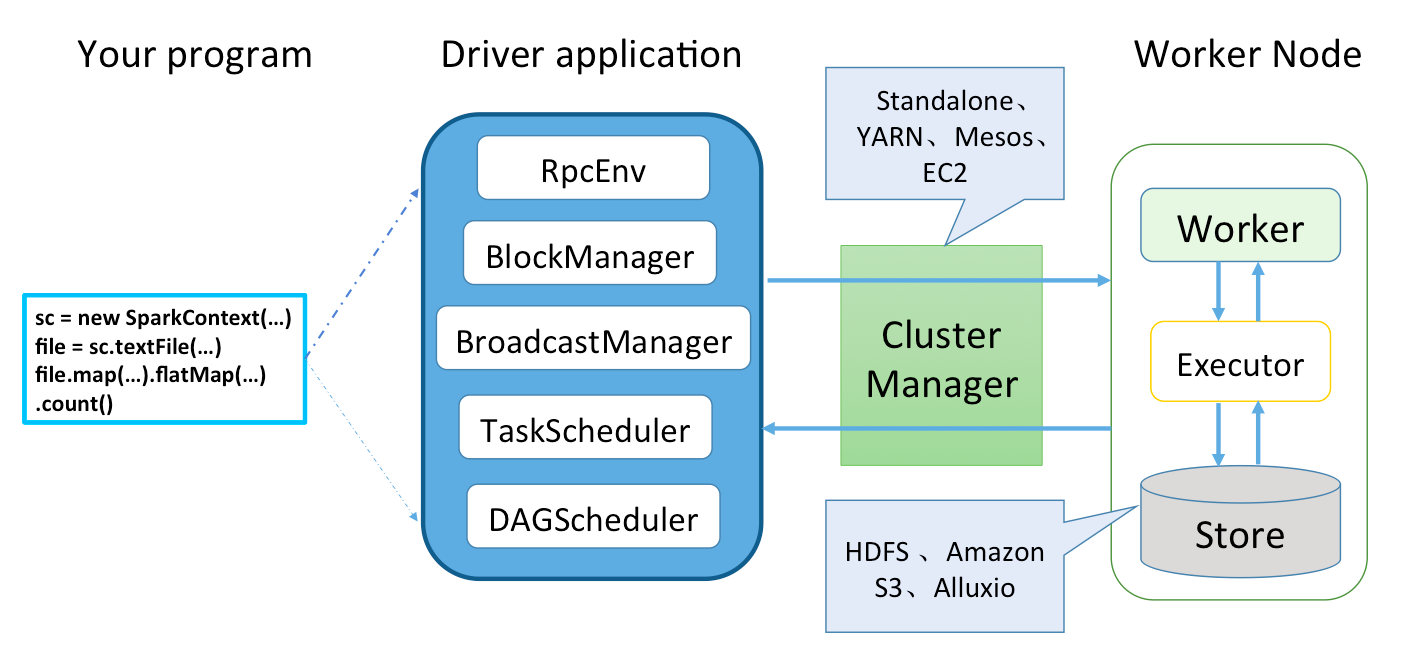
图2-5 代码执行过程
图2-5中描述了Spark编程模型的关键环节的步骤如下:
- 用户使用SparkContext提供的API(常用的有textFile、sequenceFile、runJob、stop等)编写Driverapplication程序。此外,SparkSession、DataFrame、SQLContext、HiveContext及StreamingContext都对SparkContext进行了封装,并提供了DataFrame、SQL、Hive及流式计算相关的API。
- 使用SparkContext提交的用户应用程序,首先会通过RpcEnv向集群管理器(ClusterManager)注册应用(Application)并且告知集群管理器需要的资源数量。集群管理器根据Application的需求,给Application分配Executor资源,并在Worker上启动CoarseGrainedExecutorBackend进程(CoarseGrainedExecutorBackend进程内部将创建Executor)。Executor所在的CoarseGrainedExecutorBackend进程在启动的过程中将通过RpcEnv直接向Driver注册Executor的资源信息,TaskScheduler将保存已经分配给应用的Executor资源的地址、大小等相关信息。然后,SparkContext根据各种转换API,构建RDD之间的血缘关系(lineage)和DAG,RDD构成的DAG将最终提交给DAGScheduler。DAGScheduler给提交的DAG创建Job并根据RDD的依赖性质将DAG划分为不同的Stage。DAGScheduler根据Stage内RDD的Partition数量创建多个Task并批量提交给TaskScheduler。TaskScheduler对批量的Task按照FIFO或FAIR调度算法进行调度,然后给Task分配Executor资源,最后将Task发送给Executor由Executor执行。此外,SparkContext还会在RDD转换开始之前使用BlockManager和BroadcastManager将任务的Hadoop配置进行广播。
- 集群管理器(ClusterManager)会根据应用的需求,给应用分配资源,即将具体任务分配到不同Worker节点上的多个Executor来处理任务的运行。Standalone、YARN、Mesos、EC2等都可以作为Spark的集群管理器。
- Task在运行的过程中需要对一些数据(例如中间结果、检查点等)进行持久化,Spark支持选择HDFS 、Amazon S3、Alluxio(原名叫Tachyon)等作为存储。
RDD计算模型
RDD可以看做是对各种数据计算模型的统一抽象,Spark的计算过程主要是RDD的迭代计算过程,如图2-6所示。RDD的迭代计算过程非常类似于管道。分区数量取决于Partition数量的设定,每个分区的数据只会在一个Task中计算。所有分区可以在多个机器节点的Executor上并行执行。
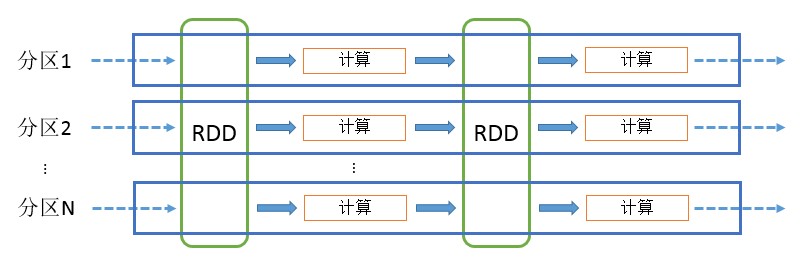
图2-6 RDD计算模型
图2-6只是简单的从分区的角度将RDD的计算看作是管道,如果从RDD的血缘关系、Stage划分的角度来看,由RDD构成的DAG经过DAGScheduler调度后,将变成图2-7所示的样子。
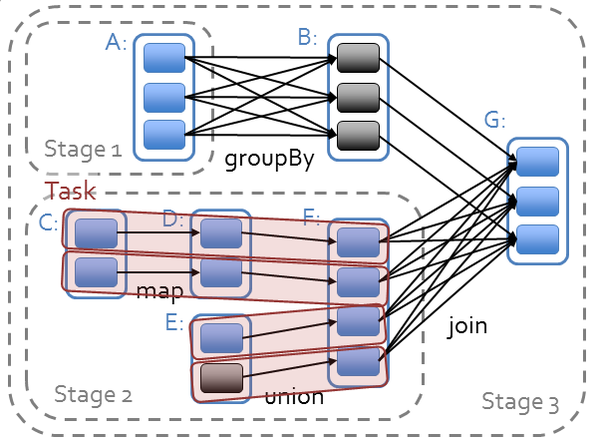
图2-7 DAGScheduler对由RDD构成的DAG进行调度
图2-7中共展示了A、B、C、D、E、F、G一共七个RDD。每个RDD中的小方块代表一个分区,将会有一个Task处理此分区的数据。RDD A经过groupByKey转换后得到RDD B。RDD C经过map转换后得到RDD D。RDD D和RDD E经过union转换后得到RDD F。RDD B和RDD F经过join转换后得到RDD G。从图中可以看到map和union生成的RDD与其上游RDD之间的依赖是NarrowDependency,而groupByKey和join生成的RDD与其上游的RDD之间的依赖是ShuffleDependency。由于DAGScheduler按照ShuffleDependency作为Stage的划分的依据,因此A被划入了ShuffleMapStage 1;C、D、E、F被划入了ShuffleMapStage 2;B和G被划入了ResultStage 3。
Spark基本架构
从集群部署的角度来看,Spark集群由以下部分组成:
- Cluster Manager:Spark的集群管理器,主要负责资源的分配与管理。Cluster Manager在Yarn部署模式下为ResourceManager;在Mesos部署模式下为Mesos master;在Standalone部署模式下为Master。ResourceManager分配的资源属于一级分配,它将各个Worker上的内存、CPU等资源分配给应用程序,但是并不负责对Executor的资源分配。Standalone部署模式下为Master会直接给应用程序分配内存、CPU以及Executor等资源。目前,Standalone、YARN、Mesos、EC2等都可以作为Spark的集群管理器。
- Worker:Spark的工作节点。在Yarn部署模式下实际由NodeManager替代。Worker节点主要负责以下工作:创建Executor,将资源和任务进一步分配给Executor,同步资源信息给Cluster Manager。在Standalone部署模式下,Master将Worker上的内存、CPU以及Executor等资源分配给应用程序后,将命令Worker启动CoarseGrainedExecutorBackend进程(此进程会创建Executor实例)。
- Executor:执行计算任务的一线组件。主要负责任务的执行以及与Worker、Driver的信息同步。
- Driver App:客户端驱动程序,也可以理解为客户端应用程序,用于将任务程序转换为RDD和DAG,并与Cluster Manager进行通信与调度。Driver可以运行在客户端,也可以由客户端提交给Cluster Manager并由ClusterManager安排Worker运行。
这些组成部分之间的整体关系如图2-8所示。
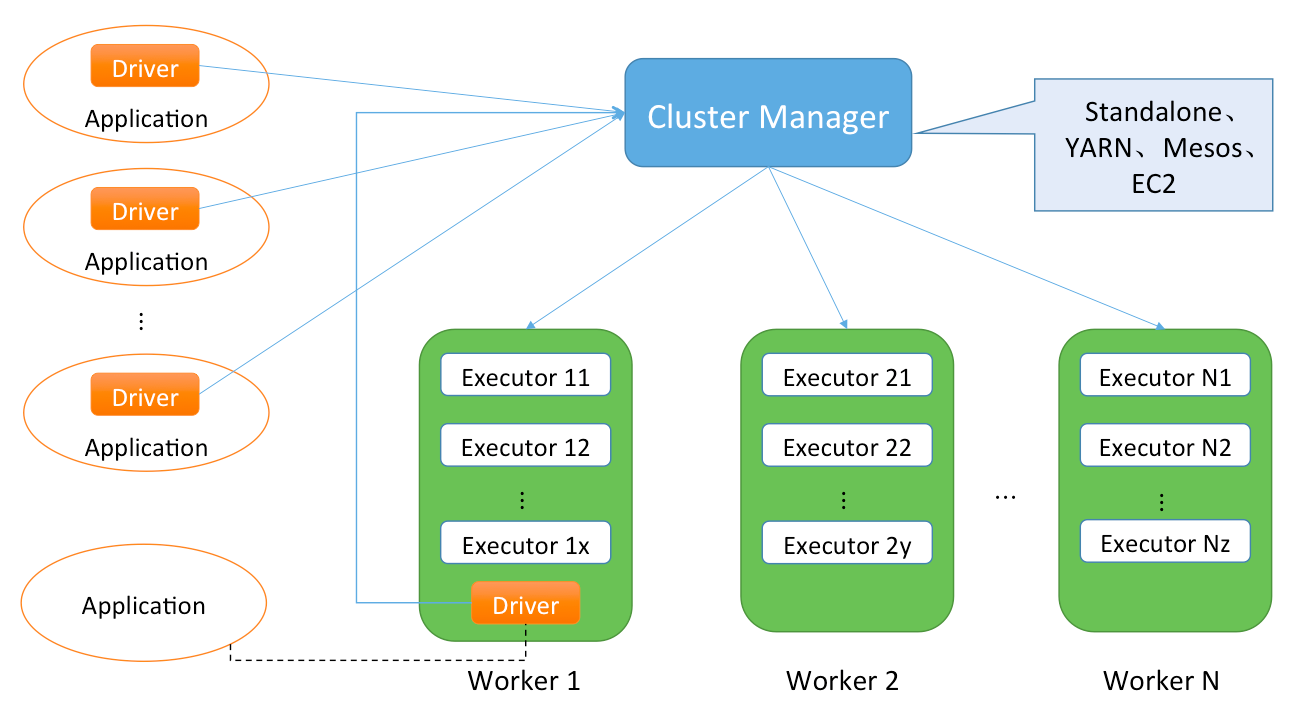
图2-8 Spark基本架构图
每项技术的诞生都会由某种社会需求所驱动,Spark正是在实时计算的大量需求下诞生的。Spark借助其优秀的处理能力,可用性高,丰富的数据源支持等特点,在当前大数据领域变得火热,参与的开发者也越来越多。Spark经过几年的迭代发展,如今已经提供了丰富的功能。笔者相信,Spark在未来必将产生更耀眼的火花。
关于《Spark内核设计的艺术 架构设计与实现》
经过近一年的准备,基于Spark2.1.0版本的《 Spark内核设计的艺术 架构设计与实现》一书现已出版发行,图书如图:



