最近使用Python遇到两个非常不好定位的问题,表现都是Python主进程hang住。最终定位出一个是subprocess模块的问题,一个是threading.Timer线程的问题。
subprocess模块不当使用的问题
Python的subprocess比较强大,基本上能替换os.system、os.popen、commands.getstatusoutput的功能,但是在使用的过程中需要注意参数stdin/stdout/stderr使用subprocess.PIPE的情况,因为管道通常会有默认的buffer size(Linux x86_64下实测是64K,这里有个疑问io.DEFAULT_BUFFER_SIZE是8K,而ulimit -a的pipe size为512 * 8 = 4K?),父进程如果不使用communicate消耗掉子进程write pipe(stdout/stderr)中的数据,直接进入wait,此时子进程可能阻塞在了pipe的写上,从而导致父子进程都hang住。下面是测试代码。
# main.py
#!/usr/bin/env python
# encoding: utf-8
import subprocess
import os
import tempfile
import sys
import traceback
import commands
# both parent and child process will hang
# if run.py stdout/stderr exceed 64K, since
# parent process is waiting child process exit
# but child process is blocked by writing pipe
def testSubprocessCallPipe():
# call: just Popen().wait()
p = subprocess.Popen(["python", "run.py"],
stdin=subprocess.PIPE,
stdout=subprocess.PIPE,
stderr=subprocess.PIPE)
ret = p.wait()
print ret
# will not hang since the parent process which
# call communicate will poll or thread to comsume
# the pipe buffer, so the child process can write
# all it's data to stdout or stderr pipe and it will
# not be blocked.
def testSubprocessCommunicate():
p = subprocess.Popen(["python", "run.py"],
stdin=subprocess.PIPE,
stdout=subprocess.PIPE,
stderr=subprocess.PIPE)
print p.communicate()[0]
# will not hang since sys.stdout and sys.stderr
# don't have 64K default buffer limitation, child
# process can write all it's data to stdout or
# stderr fd and exit
def testSubprocessCallStdout():
# call: just Popen().wait()
p = subprocess.Popen(["python", "run.py"],
stdin=sys.stdin,
stdout=sys.stdout,
stderr=sys.stderr)
ret = p.wait()
print ret
# will not hang since file has no limitation of 64K
def testSubprocessCallFile():
stdout = tempfile.mktemp()
stderr = tempfile.mktemp()
print "stdout file %s" % (stdout,), "stderr file %s" % (stderr,)
stdout = open(stdout, "w")
stderr = open(stderr, "w")
p = subprocess.Popen(["python", "run.py"],
stdin=None,
stdout=stdout,
stderr=stderr)
ret = p.wait()
print ret
print os.getpid()
# not hang
print "use file"
testSubprocessCallFile()
# not hang
print "use sys.stdout and sys.stderr"
testSubprocessCallStdout()
# not hang
print "use pipe and communicate"
testSubprocessCommunicate()
# hang
print "use pipe and call directly"
testSubprocessCallPipe()# run.py
import os
print os.getpid()
string = ""
# > 64k will hang
for i in range(1024 * 64 - 4):
string = string + "c"
# flush to my stdout which might
# be sys.stdout/pipe/fd...
print string另外,在subprocess模块源码中还注释说明了另外一种由于fork -> 子进程gc -> exec导致的进程hang住,详细信息可以阅读subprocess模块源码。
threading.Timer的使用不当的问题
定位步骤:
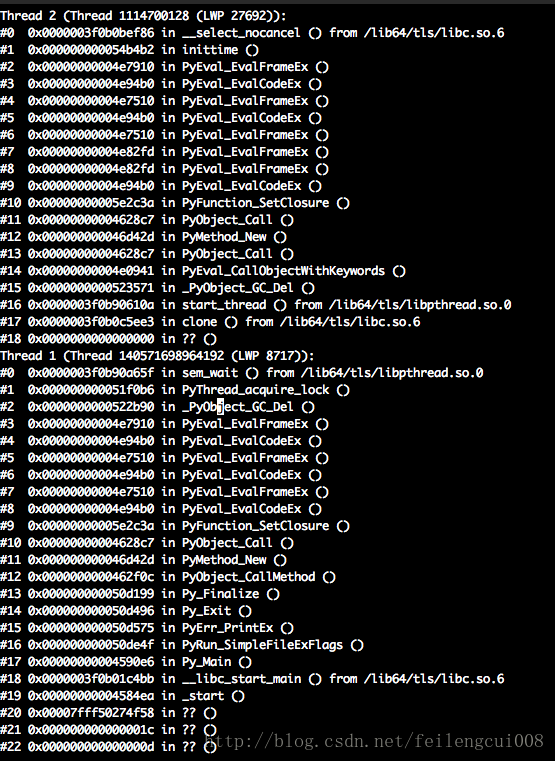
pstack 主进程,查看python语言源码的c调用栈,追踪主线程(图中线程1)的各个函数调用栈的python源码,猜测是阻塞在threading._shutdown方法上,修改threading模块源码,并添加日志,定位确实阻塞在_exitFunc的循环join thread上。
线程2的表现是不断创建不断退出,为threading.start入口添加打印traceback,最终定位在一个模块的心跳计时器。调大心跳周期,观察步骤1中的线程id,确定是心跳计时器线程。注: approach 2中可用ctrl-c构造异常,构造hang住的情况。
重现poc
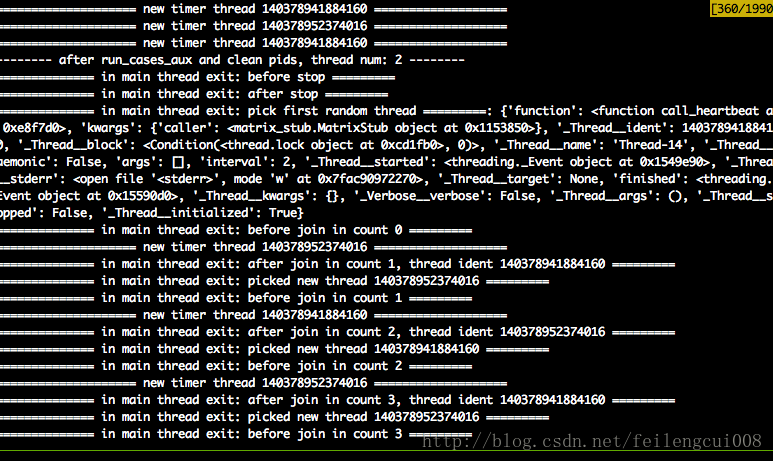
import threading
import time
import sys
# approach 1
class TestClassA(object):
timer = None
count = 0
def __del__(self):
print "called del"
if self.timer is not None:
self.timer.cancel()
def new_timer(self):
# current reference 3 + getrefcount 1 = 4
print "in new_timer: %d" % (sys.getrefcount(self))
print "ffff"
self.count += 1
# my father timer thread exit, ref count -1, but start
# a new thread will make it still 3
self.timer = threading.Timer(1, self.new_timer)
self.timer.start()
def start_timer(self):
self.timer = threading.Timer(1, self.new_timer)
self.timer.start()
def test():
t = TestClassA()
print "enter test: %d" % (sys.getrefcount(t),) # 2
t.start_timer() # pass ref to a new timer thread through self.new_timer: 3
print "before out test: %d" % (sys.getrefcount(t),) # 3
# approach 2
class TestClassB(object):
timer = None
count = 0
def __del__(self):
print "called del"
def func(*ins):
print "fffff"
ins[0].count += 1
ins[0].timer = threading.Timer(1, func, ins) # will increase reference count of ins
ins[0].timer.start()
def test_in_scope():
t = TestClassB()
print "enter test_in_scope: %d" % (sys.getrefcount(t))
t.timer = threading.Timer(1, func, (t,))
t.timer.start()
while t.count < 4:
time.sleep(1)
#try:
# while t.count < 4:
# time.sleep(1)
#except:
# pass
# if we interrupt or raise some other exceptions and not catch that,
# will hang
t.timer.cancel()
print "before exit test_in_scope: %d" % (sys.getrefcount(t))
# approachh 3
def test_closure():
t = TestClassA()
print "enter test_closure: %d" % (sys.getrefcount(t),)
def func_inner():
print "ffffffff"
t.timer = threading.Timer(1, func_inner) # will increase reference count
t.count += 1
t.timer.start()
print "in func: %d" % (sys.getrefcount(t))
t.timer = threading.Timer(1, func_inner)
t.timer.start()
print "before out test_closure: %d" % (sys.getrefcount(t),)
#print "================= test approach 1 ==============="
#print "before test"
#test()
#print "after test"
print "================= test approach 2 ==============="
print "before test_in_scope"
test_in_scope()
print "after test_in_scope"
#print "================= test approach 3 ================"
#print "before test_closure"
#test_closure()
#print "after test_closure"
print "before exit main thread, it will wait and join all other threads"
sys.exit()