本系列博文主要侧重于分析Netfilter的实现机制、原理和设计思想层面的东西,同时包括从用户态的iptables到内核态的Netfilter的交互过程和通信手段等。至于iptables的入门用法方面的东西,网上随便一搜罗就有一大堆,我这里不浪费笔墨了。
很多人在接触iptables之后就会这么一种感觉:我通过iptables命令配置的每一条规则,到底是如何生效的呢?内核又是怎么去执行这些规则匹配呢?如果iptables不能满足我当下的需求,那么我是否可以去对其进行扩展呢?这些问题,都是我在接下来的博文中一一和大家分享的话题。这里需要指出:因为Netfilter与IP协议栈是无缝契合的,所以如果你要是有协议栈方面的基础,在阅读本文时一定会感觉轻车熟路。当然,如果没有也没关系,因为我会在关键点就协议栈的入门知识给大家做个普及。只是普及哦,不会详细深入下去的,因为涉及的东西太多了,目前我还正在研究摸索当中呢。好了,废话不多说,进入正题。
备注:本人研究的内核版本是2.6.21,iptables的版本是1.4.0。
什么是Netfilter?
为了说明这个问题,我们首先看一个网络通信的基本模型:
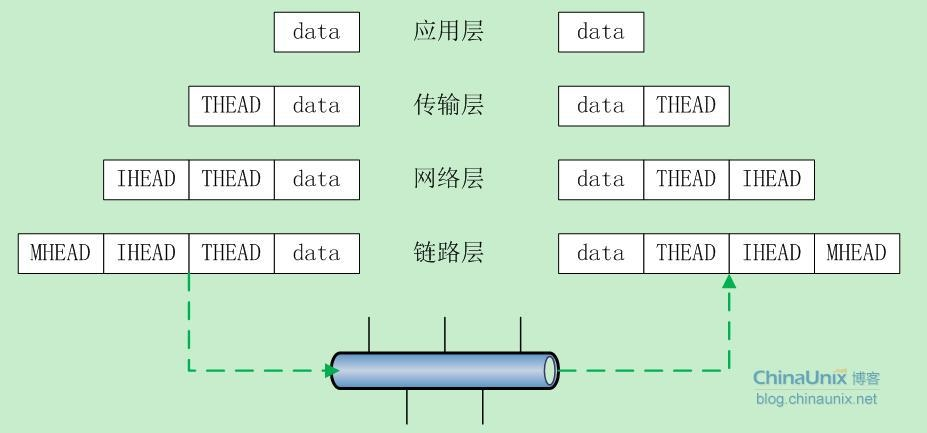
在数据的发送过程中,从上至下依次是“加头”的过程,每到达一层,数据就会被加上该层的头部信息。与此同时,接收数据方就是个“剥头”的过程,当从网卡接收到数据包之后,在往协议栈的上层传递过程中依次剥去每层的头部,最终到达用户那儿的就是裸数据了。
那么,对于IPv4协议栈,其“栈”模式底层机制基本就是像下面这个样子:
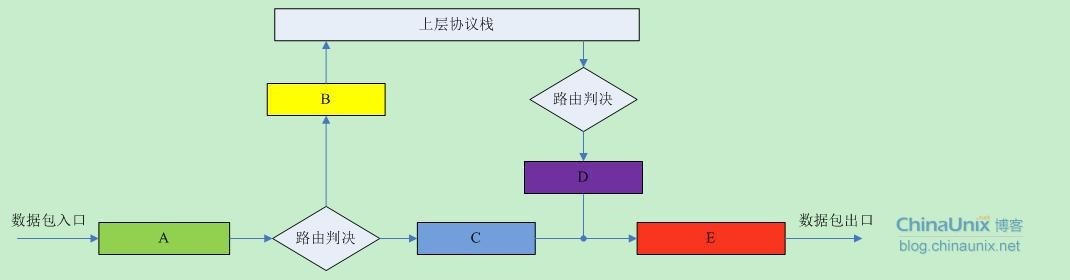
对于接收到的每个数据包,都从“A”点进来,经过路由判决,如果是发送给本地主机的就经过“B”点,然后往协议栈的上层继续传递;否则,如果该数据包的目的主机不是本机,那么就经过“C”点,然后顺着“E”点将该数据包发送出去。
对于欲发送的每个数据包,首先也有一个路由判决,以确定该数据包从哪个接口出去,然后经过“D”点,最后也是顺着“E”点将该数据包发送出去。
协议栈中的那五个关键点A、B、C、D和E就是我们Netfilter大展拳脚的地方了。
Netfilter是Linux 2.4.x引入的一个子系统,它作为一个通用的、抽象的框架,提供了一整套的hook函数的管理机制,使得诸如数据包过滤、网络地址转换(NAT)和基于协议类型的连接跟踪成为了可能。Netfilter在内核中的位置如下图所示:
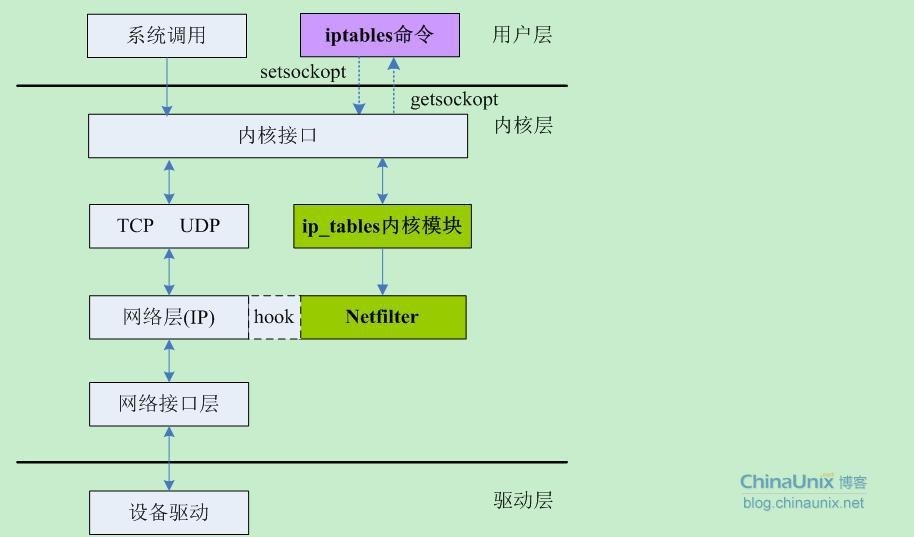
上面这幅图,很直观地反映了用户空间的iptables和内核空间的基于Netfilter的ip_tables模块之间的关系和其通讯方式,以及Netfilter在这其中所扮演的角色。
回到前面讨论的关于协议栈的那五个关键点“ABCDE”上来。Netfilter在netfilter_ipv4.h中将这五个点重新命了名,如下图所示,意思我就不再解释了,猫叫喵喵而已:
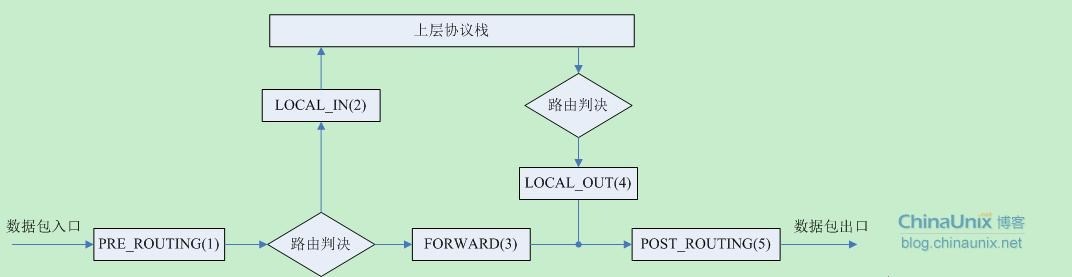
/* IP Hooks */
/* After promisc drops, checksum checks. */
#define NF_IP_PRE_ROUTING 0
/* If the packet is destined for this box. */
#define NF_IP_LOCAL_IN 1
/* If the packet is destined for another interface. */
#define NF_IP_FORWARD 2
/* Packets coming from a local process. */
#define NF_IP_LOCAL_OUT 3
/* Packets about to hit the wire. */
#define NF_IP_POST_ROUTING 4在每个关键点上,有很多已经按照优先级预先注册了的回调函数(后面再说这些函数是什么以及干什么用的)。有些人也喜欢把这些函数称为“钩子函数(Hooks)”,说的是同一个东西。这些函数被埋伏在这些关键点,形成了一条链。对于每个到来的或发出的数据包会依次被这些回调函数“调戏”一番后再视情况是将其放行,丢弃还是怎么滴。但是,无论如何,这些回调函数最后必须向Netfilter报告一下该数据包的死活情况,因为毕竟每个数据包都是Netfilter从别人协议栈那儿借调过来给兄弟们Happy的,别个再怎么滴也总得“活要见人,死要见尸”吧。每个钩子函数最后必须向Netfilter框架返回下列几个值之一:
- NF_ACCEPT 继续正常传输数据包。该返回值告诉Netfilter:到目前为止,该数据包还是被接受的,并且该数据包应当被递交给网络协议栈的下一个阶段;
- NF_DROP 丢弃该数据包,不再传输;
- NF_STOLEN 模块接管该数据包,告诉Netfilter”忘掉“该数据包,也就是说本模块”偷(stolen)“了这个数据包。该回调函数将从此开始对数据包进行处理,并且Netfilter应当放弃对该数据包做任何的处理。但是,这并不意味着该数据包的资源已经被释放。这个数据包以及它独自的sk_buff数据结构仍然有效,只是回调函数从Netfilter获取了该数据包的所有权。
- NF_QUEUE 对该数据包进行排队(通常用于将数据包传递给用户空间的进程进行处理);
- NF_REPEAT 再次调用该回调函数,应当谨慎使用该值,以免造成死循环。
/* Responses from hook functions. */
#define NF_DROP 0
#define NF_ACCEPT 1
#define NF_STOLEN 2
#define NF_QUEUE 3
#define NF_REPEAT 4
#define NF_MAX_VERDICT NF_REPEAT为了让我们显得更专业点,我们开始做些约定:上面提到的五个关键点后面我们就叫它们为hook点,每个hook点所注册的那些回调函数都将其称为hook函数。
Linux 2.6版内核的Netfilter目前支持IPv4、IPv6以及DECnet等协议栈,这里我们主要研究IPv4协议。关于协议类型、hook点、hook函数以及优先级,我们通过下图给大家做个详细展示:
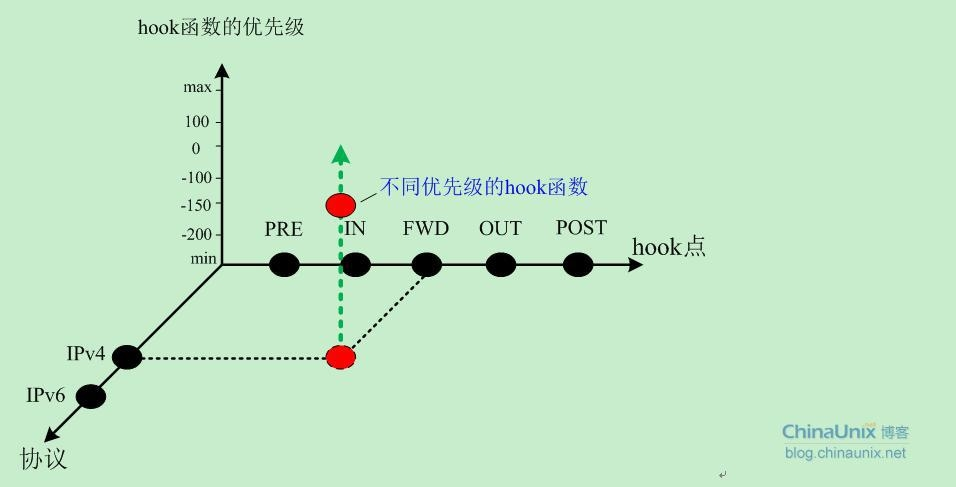
对于每种类型的协议,数据包都会依次按照hook点的方向进行传输,每个hook点上Netfilter又按照优先级挂载了很多hook函数。这些hook函数就是用来处理数据包的。
Netfilter使用NF_HOOK(include/linux/netfilter.h)宏在协议栈内部切入到Netfilter框架中。2.6版本内核对于该宏的定义如下:
/* This is gross, but inline doesn't cut it for avoiding the function
call in fast path: gcc doesn't inline (needs value tracking?). --RR */
/* HX: It's slightly less gross now. */
#define NF_HOOK_THRESH(pf, hook, skb, indev, outdev, okfn, thresh) \
({int __ret; \
if ((__ret=nf_hook_thresh(pf, hook, &(skb), indev, outdev, okfn, thresh, 1)) == 1)\
__ret = (okfn)(skb); \
__ret;})
#define NF_HOOK_COND(pf, hook, skb, indev, outdev, okfn, cond) \
({int __ret; \
if ((__ret=nf_hook_thresh(pf, hook, &(skb), indev, outdev, okfn, INT_MIN, cond)) == 1)\
__ret = (okfn)(skb); \
__ret;})
#define NF_HOOK(pf, hook, skb, indev, outdev, okfn) \
NF_HOOK_THRESH(pf, hook, skb, indev, outdev, okfn, INT_MIN)关于宏NF_HOOK各个参数的说明如下:
1. pf:协议族名称,Netfilter架构同样可以用于IP层之外,因此,该变量还可以有诸如PF_INET6、PF_DECnet等名字。
2. hook:hook点的名字,对于IP层,其值即为前面的五个关键点值;
3. skb:不解释,sk_buff结构体变量,即数据包指针;
4. indev:数据包进入的设备,以struct net_device结构表示;
5. outdev:数据包出去的设备,以struct net_device结构表示;后面可以看到,以上五个参数将传递给nf_register_hook中注册的处理函数。
6. okfn:函数指针,当所有的该hook点的所有注册函数被调用完之后,转而执行此流程。
对于NF_HOOK_THRESH,其定义如上代码。
我们发现NF_HOOK_THRESH宏只增加了一个thresh参数,该参数就是用来执行该宏去遍历hook函数时的优先级,同时,该宏内部又调用了nf_hook_thresh函数。
/**
* nf_hook_thresh - call a netfilter hook
*
* Returns 1 if the hook has allowed the packet to pass. The function
* okfn must be invoked by the caller in this case. Any other return
* value indicates the packet has been consumed by the hook.
*/
static inline int nf_hook_thresh(int pf, unsigned int hook,
struct sk_buff **pskb,
struct net_device *indev,
struct net_device *outdev,
int (*okfn)(struct sk_buff *), int thresh,
int cond)
{
if (!cond)
return 1;
#ifndef CONFIG_NETFILTER_DEBUG
if (list_empty(&nf_hooks[pf][hook]))
return 1;
#endif
return nf_hook_slow(pf, hook, pskb, indev, outdev, okfn, thresh);
}该函数只增加了一个参数cond,该参数为0则放弃遍历,并且也不执行okfn函数;如果该参数为1,则进行下一步操作。对于下一步的调用,其是条件性的。如果没有设置CONFIG_NETFILTER_DEBUG环境变量,那么,下一步则直接执行nf_hook_slow函数。而如果设置了CONFIG_NETFILTER_DEBUG环境变量,那么,情况就有所不同了。内核需要首先检查对应协议族和对应hook点的注册钩子函数链是否为空,如果是的,则返回1,而NF_HOOK_THRESH宏的后续工作则为直接执行okfn函数指针对应的处理过程,反之,nf_hook_thresh就去执行nf_hook_slow函数。那么,nf_hook_slow函数到底干了什么事?见【R】处。
要清楚地说明这种特殊情况的行为,我们必须对list_empty(&nf_hooks[pf][hook])语句进行深入地分析。
在net/core/netfilter.c文件中,定义了一个二维的结构体数组,用来存储不同协议栈hook点的回调处理函数。
struct list_head nf_hooks[NPROTO][NF_MAX_HOOKS];
其中,行数NPROTO为32,即目前内核所支持的最大协议族数;列数NF_MAX_HOOKS为hook点的个数,目前在2.6内核中该值为8。因此,nf_hooks数组的最终结构如下图所示:
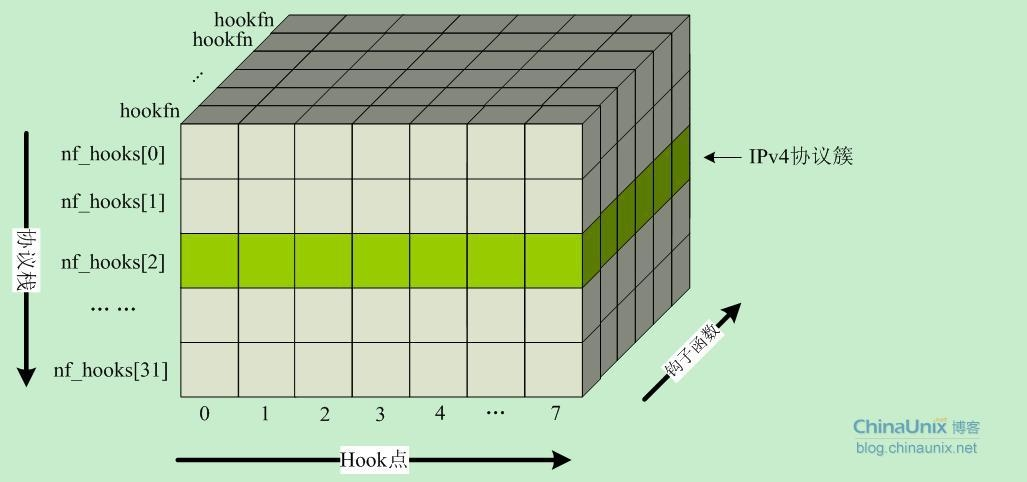
在include/linux/socket.h中IP协议AF_INET(PF_INET)的序号为2,因此我们就可以得到TCP/IP协议族的钩子函数挂载点为:
- PRE_ROUTING: nf_hooks[2][0]
- LOCAL_IN: nf_hooks[2][1]
- FORWARD: nf_hooks[2][2]
- LOCAL_OUT: nf_hooks[2][3]
- POST_ROUTING: nf_hooks[2][4]
同时我们看到,在2.6内核的IP协议栈中,从协议栈正常的流程切入到Netfilter框架中,然后顺序地依次地调用每个hook点所有的钩子函数的相关操作有如下几处:
1.net/ipv4/ip_input.c中的ip_rcv函数。该函数主要用来处理网络层的IP报文的入口函数,它到Netfilter框架的切入点为:
NF_HOOK(PF_INET, NF_IP_PRE_ROUTING, skb, dev, NULL, ip_rcv_finish);
根据前面的理解,这句代码意义已经很直观明确了。那就是:如果协议栈当前接收到了一个IP报文(PF_INET),那么就把这个报文传到NF_IP_PRE_ROUTING过滤点,去检查【R】在那个过滤点(nf_hooks[2][0])是否有人注册了相关的用于处理数据包的钩子函数。如果有,则依次遍历链表nf_hooks[2][0]去需找匹配的match和相应的target,根据返回到Netfilter框架中的值来进一步决定该如何处理该数据包(由钩子模块处理还是交由ip_rcv_finish函数继续处理)。
【R】:刚才说到的所谓”检查“。其核心就是nf_hook_slow函数。该函数本质上做的事很简单,其根据优先级查找双向链表nf_hooks[][],找到对应的回调函数来处理数据包,详细代码如下:
int nf_hook_slow(int pf, unsigned int hook, struct sk_buff *skb,
struct net_device *indev,
struct net_device *outdev,
int (*okfn)(struct sk_buff *),
int hook_thresh)
{
struct list_head *elem;
unsigned int verdict;
int ret = 0;
/* We may already have this, but read-locks nest anyway */
rcu_read_lock();
#ifdef CONFIG_NETFILTER_DEBUG
if (skb->nf_debug & (1 << hook)) {
printk("nf_hook: hook %i already set.\n", hook);
nf_dump_skb(pf, skb);
}
skb->nf_debug |= (1 << hook);
#endif
elem = &nf_hooks[pf][hook];
next_hook:
verdict = nf_iterate(&nf_hooks[pf][hook], &skb, hook, indev,
outdev, &elem, okfn, hook_thresh);
if (verdict == NF_QUEUE) {
NFDEBUG("nf_hook: Verdict = QUEUE.\n");
if (!nf_queue(skb, elem, pf, hook, indev, outdev, okfn))
goto next_hook;
}
switch (verdict) {
case NF_ACCEPT:
ret = okfn(skb);
break;
case NF_DROP:
kfree_skb(skb);
ret = -EPERM;
break;
}
rcu_read_unlock();
return ret;
}
static unsigned int nf_iterate(struct list_head *head,
struct sk_buff **skb,
int hook,
const struct net_device *indev,
const struct net_device *outdev,
struct list_head **i,
int (*okfn)(struct sk_buff *),
int hook_thresh)
{
/*
* The caller must not block between calls to this
* function because of risk of continuing from deleted element.
*/
list_for_each_continue_rcu(*i, head) {
struct nf_hook_ops *elem = (struct nf_hook_ops *)*i;
if (hook_thresh > elem->priority)
continue;
/* Optimization: we don't need to hold module
reference here, since function can't sleep. --RR */
switch (elem->hook(hook, skb, indev, outdev, okfn)) {
case NF_QUEUE:
return NF_QUEUE;
case NF_STOLEN:
return NF_STOLEN;
case NF_DROP:
return NF_DROP;
case NF_REPEAT:
*i = (*i)->prev;
break;
#ifdef CONFIG_NETFILTER_DEBUG
case NF_ACCEPT:
break;
default:
NFDEBUG("Evil return from %p(%u).\n",
elem->hook, hook);
#endif
}
}
return NF_ACCEPT;
}2.net/ipv4/ip_forward.c中的ip_forward函数,它的切入点为:
NF_HOOK(PF_INET, NF_IP_FORWARD, skb, skb->dev, rt->u.dst.dev, ip_forward_finish);
在经过路由抉择后,所有需要本机转发的报文都会交由ip_forward函数进行处理。这里,该函数由NF_IP_FORWARD过滤点切入到Netfilter框架,在nf_hooks[2][2]过滤点执行匹配查找。最后根据返回值来确定ip_forward_finish函数的执行情况。
int ip_forward(struct sk_buff *skb)
{
struct iphdr *iph; /* Our header */
struct rtable *rt; /* Route we use */
struct ip_options * opt = &(IPCB(skb)->opt);
if (!xfrm4_policy_check(NULL, XFRM_POLICY_FWD, skb))
goto drop;
if (IPCB(skb)->opt.router_alert && ip_call_ra_chain(skb))
return NET_RX_SUCCESS;
if (skb->pkt_type != PACKET_HOST)
goto drop;
skb->ip_summed = CHECKSUM_NONE;
/*
* According to the RFC, we must first decrease the TTL field. If
* that reaches zero, we must reply an ICMP control message telling
* that the packet's lifetime expired.
*/
iph = skb->nh.iph;
if (iph->ttl <= 1)
goto too_many_hops;
if (!xfrm4_route_forward(skb))
goto drop;
iph = skb->nh.iph;
rt = (struct rtable*)skb->dst;
if (opt->is_strictroute && rt->rt_dst != rt->rt_gateway)
goto sr_failed;
/* We are about to mangle packet. Copy it! */
if (skb_cow(skb, LL_RESERVED_SPACE(rt->u.dst.dev)+rt->u.dst.header_len))
goto drop;
iph = skb->nh.iph;
/* Decrease ttl after skb cow done */
ip_decrease_ttl(iph);
/*
* We now generate an ICMP HOST REDIRECT giving the route
* we calculated.
*/
if (rt->rt_flags&RTCF_DOREDIRECT && !opt->srr)
ip_rt_send_redirect(skb);
skb->priority = rt_tos2priority(iph->tos);
return NF_HOOK(PF_INET, NF_IP_FORWARD, skb, skb->dev, rt->u.dst.dev,
ip_forward_finish);
sr_failed:
/*
* Strict routing permits no gatewaying
*/
icmp_send(skb, ICMP_DEST_UNREACH, ICMP_SR_FAILED, 0);
goto drop;
too_many_hops:
/* Tell the sender its packet died... */
icmp_send(skb, ICMP_TIME_EXCEEDED, ICMP_EXC_TTL, 0);
drop:
kfree_skb(skb);
return NET_RX_DROP;
}3.net/ipv4/ip_output.c中的ip_output函数,它的切入点为:
NF_HOOK_COND(PF_INET, NF_IP_POST_ROUTING, skb, NULL, dev, ip_finish_output, !(IPCB(skb)->flags & IPSKB_REROUTED));
这里,我们看到切入点从无条件宏NF_HOOK改成了有条件宏NF_HOOK_COND,调用该宏的条件是:如果协议栈当前所处理的数据包中没有重新路由的标记,数据包才会进入Netfilter框架。否则,直接调用ip_finish_output函数走协议栈去处理。除此之外,有条件宏和无条件宏再无其他任何差异。
如果需要陷入Netfilter框架,则数据包会在nf_hooks[2][4]过滤点去进行匹配查找。
4.net/ipv4/ip_input.c中的ip_local_deliver函数。干函数处理所有目的地址是本机的数据包,其切入点为:
NF_HOOK(PF_INET, NF_IP_LOCAL_IN, skb, skb->dev, NULL,ip_local_deliver_finish);
发往本机的数据包,首先会全部去往nf_hooks[2][1]过滤点上检测是否有相关数据包的回调处理函数,如果有则执行匹配动作,最后根据返回值执行ip_local_deliver_finish函数。
/*
* Deliver IP Packets to the higher protocol layers.
*/
int ip_local_deliver(struct sk_buff *skb)
{
/*
* Reassemble IP fragments.
*/
if (skb->nh.iph->frag_off & htons(IP_MF|IP_OFFSET)) {
skb = ip_defrag(skb, IP_DEFRAG_LOCAL_DELIVER);
if (!skb)
return 0;
}
return NF_HOOK(PF_INET, NF_IP_LOCAL_IN, skb, skb->dev, NULL,
ip_local_deliver_finish);
}5.net/ipv4/ip_output.c中的ip_push_pending_frame函数。该函数将IP分片重组成完整的IP报文,然后发送出去。进入Netfilter框架的切入点为:
NF_HOOK(PF_INET, NF_IP_LOCAL_OUT, skb, NULL, skb->dst->dev, dst_output);
对于所有从本机发出去的报文都会首先去Netfilter的nf_hooks[2][3]过滤点去过滤。一般情况下来来说,不管是路由器还是PC中端,很少有人限制自己机器发出去的报文。因为这样做的潜在风险也是显而易见的,往往会因为一些不恰当的设置导致某些服务失效,所以在这个过滤点上拦截数据包的情况非常少。当然也不排除真的有特殊需求的情况。
/*
* Combined all pending IP fragments on the socket as one IP datagram
* and push them out.
*/
int ip_push_pending_frames(struct sock *sk)
{
struct sk_buff *skb, *tmp_skb;
struct sk_buff **tail_skb;
struct inet_sock *inet = inet_sk(sk);
struct ip_options *opt = NULL;
struct rtable *rt = inet->cork.rt;
struct iphdr *iph;
int df = 0;
__u8 ttl;
int err = 0;
if ((skb = __skb_dequeue(&sk->sk_write_queue)) == NULL)
goto out;
tail_skb = &(skb_shinfo(skb)->frag_list);
/* move skb->data to ip header from ext header */
if (skb->data < skb->nh.raw)
__skb_pull(skb, skb->nh.raw - skb->data);
while ((tmp_skb = __skb_dequeue(&sk->sk_write_queue)) != NULL) {
__skb_pull(tmp_skb, skb->h.raw - skb->nh.raw);
*tail_skb = tmp_skb;
tail_skb = &(tmp_skb->next);
skb->len += tmp_skb->len;
skb->data_len += tmp_skb->len;
skb->truesize += tmp_skb->truesize;
__sock_put(tmp_skb->sk);
tmp_skb->destructor = NULL;
tmp_skb->sk = NULL;
}
/* Unless user demanded real pmtu discovery (IP_PMTUDISC_DO), we allow
* to fragment the frame generated here. No matter, what transforms
* how transforms change size of the packet, it will come out.
*/
if (inet->pmtudisc != IP_PMTUDISC_DO)
skb->local_df = 1;
/* DF bit is set when we want to see DF on outgoing frames.
* If local_df is set too, we still allow to fragment this frame
* locally. */
if (inet->pmtudisc == IP_PMTUDISC_DO ||
(!skb_shinfo(skb)->frag_list && ip_dont_fragment(sk, &rt->u.dst)))
df = htons(IP_DF);
if (inet->cork.flags & IPCORK_OPT)
opt = inet->cork.opt;
if (rt->rt_type == RTN_MULTICAST)
ttl = inet->mc_ttl;
else
ttl = ip_select_ttl(inet, &rt->u.dst);
iph = (struct iphdr *)skb->data;
iph->version = 4;
iph->ihl = 5;
if (opt) {
iph->ihl += opt->optlen>>2;
ip_options_build(skb, opt, inet->cork.addr, rt, 0);
}
iph->tos = inet->tos;
iph->tot_len = htons(skb->len);
iph->frag_off = df;
if (!df) {
__ip_select_ident(iph, &rt->u.dst, 0);
} else {
iph->id = htons(inet->id++);
}
iph->ttl = ttl;
iph->protocol = sk->sk_protocol;
iph->saddr = rt->rt_src;
iph->daddr = rt->rt_dst;
ip_send_check(iph);
skb->priority = sk->sk_priority;
skb->dst = dst_clone(&rt->u.dst);
/* Netfilter gets whole the not fragmented skb. */
err = NF_HOOK(PF_INET, NF_IP_LOCAL_OUT, skb, NULL,
skb->dst->dev, dst_output);
if (err) {
if (err > 0)
err = inet->recverr ? net_xmit_errno(err) : 0;
if (err)
goto error;
}
out:
inet->cork.flags &= ~IPCORK_OPT;
if (inet->cork.opt) {
kfree(inet->cork.opt);
inet->cork.opt = NULL;
}
if (inet->cork.rt) {
ip_rt_put(inet->cork.rt);
inet->cork.rt = NULL;
}
return err;
error:
IP_INC_STATS(IPSTATS_MIB_OUTDISCARDS);
goto out;
}小结
整个Linux内核中Netfilter框架的HOOK机制可以概括如下:
在数据包流经内核协议栈的整个过程中,在一些已预定义的关键点上PRE_ROUTING、LOCAL_IN、FORWARD、LOCAL_OUT和POST_ROUTING,内核会根据数据包的协议族PF_INET去往这些hook点上去查找是否注册有钩子函数。如果没有,则直接返回okfn函数指针所指向的函数继续走协议栈;如果有,则调用nf_hook_slow函数,从而进入到Netfilter框架中进一步调用已注册在该过滤点下的钩子函数,再根据其返回值来确定是否继续执行由函数指针okfn所指向的函数。




