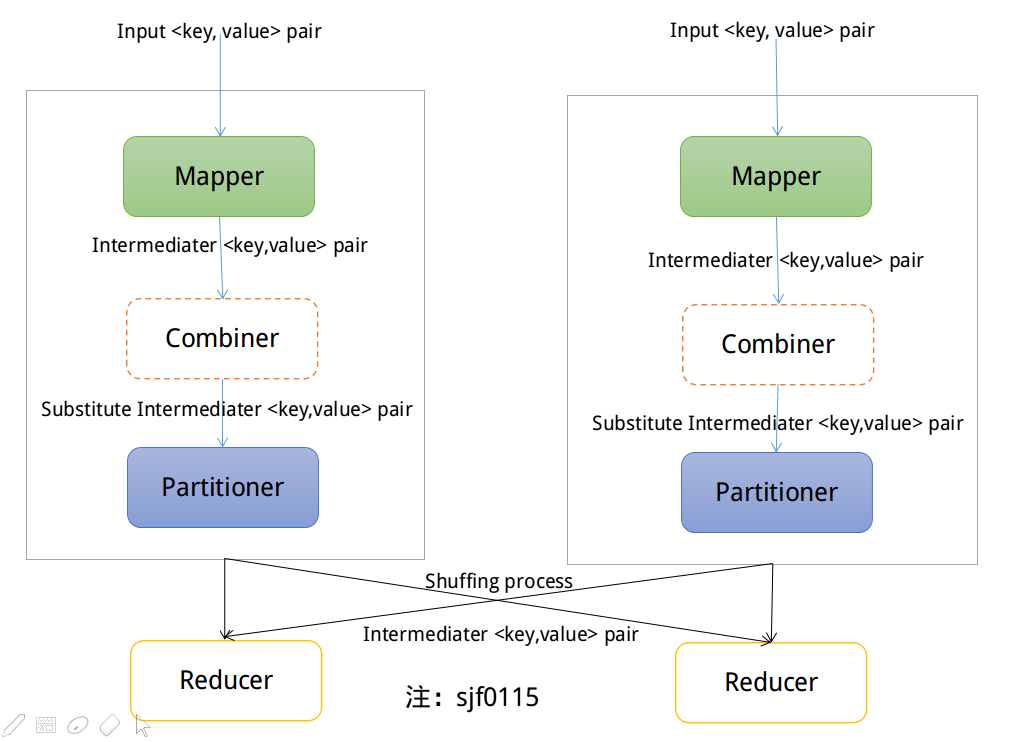
Partitioners负责划分Maper输出的中间键值对的key,分配中间键值对到不同的Reducer。Maper输出的中间结果交给指定的Partitioner,确保中间结果分发到指定的Reduce任务。在每个Reducer中,键按排序顺序处理(Within each reducer, keys are processed in sorted order)。Combiners是MapReduce中的一个优化,允许在shuffle和排序阶段之前在本地进行聚合。Combiners的首要目标是通过最小化键值对的数量来节省尽可能多的带宽,键值对将通过网络在mappers和reducers之间进行shuffle操作(The primary goal of combiners is to save as much bandwidth as possible by minimizing the number of key/value pairs that will be shuffled across the network between mappers and reducers)。我们可以把Combiners理解为发生在shuffle和sort阶段之前,对Mapper输出进行操作的"mini-reducers"。每个Combiner单独操作于一个Mapper,因此不能访问其他Mapper输出的中间结果。
1. Partitioner
第一次使用MapReduce程序的一个常见误解就是认为程序只使用一个reducer。毕竟,单个reducer在处理之前对所有数据进行排序,并将输出数据存储在单独一个输出文件中---谁不喜欢排序数据?(After all, a single reducer sorts all of your data before processing and would have stored output data in one single output file— and who doesn't like sorted data?)我们很容易理解这样的约束是毫无意义的,在大部分时间使用多个reducer是必需的,否则map / reduce理念将不在有用(It is easy to understand that such a constraint is a nonsense and that using more than one reducer is most of the time necessary, else the map/reduce concept would not be very useful)。
在使用多个Reducer的情况下,我们需要一些方法来决定Mapper输出的键值对发送到正确的Reducer中。默认情况是对key使用hash函数,来确定Reducer。分区(partition)阶段发生在Map阶段之后,Reduce阶段之前。分区的数量等于Reducer的个数(The number of partitions is equal to the number of reducers)。根据分区函数,数据都会得到正确的分区,传递到Reducer中。这种方法提供了整体性能,允许mapper能够独立完成操作(allows mappers to operate completely independently)。对于所有输出的键值对,由每个mapper决定哪个reducer来接收它们。由于所有的Mapper都使用相同的分区函数,所以无论是由哪个Mapper产生,对相同的key来说,生成的目标分区都是一样的。
单个分区是指传递到单个reduce任务的所有键值对(A single partition refers to all key/value pairs that will be sent to a single reduce task)。可以通过设置job.setNumReduceTasks,来配置多个Reducer。Hadoop的附带了一个默认的分区实现,即HashPartitioner,对记录的key进行hash,来确定记录在所属的分区。每个分区由一个reduce任务处理,因此分区数等于作业的reduce任务数(Each partition is processed by a reduce task, so the number of partitions is equal to the number of reduce tasks for the job)。
当map函数开始产生输出时,并不总是简单的写到磁盘上。每个Map任务都有一个环形内存缓冲区,用户存储Map函数的输出。当缓冲区的内容达到一定的阈值大小时,后台线程将开始将内容溢出到磁盘。在溢写磁盘的过程中,map函数的输出会继续被写到缓冲区,但如果在此期间缓冲区被填满,map会阻塞直到写磁盘过程完成。在写磁盘之前,线程会根据数据最终要传入到的Reducer,把缓冲区的数据划分成(默认是按照键)分区(Before it writes to disk, the thread first divides the data into partitions corresponding to the reducers that they will ultimately be sent to)。在每个分区中,后台线程按照键进行内存排序,此时如果有一个Combiner,它会在排序后的输出上运行(Within each partition, the background thread performs an in-memory sort by key, and if there is a combiner function, it is run on the output of the sort)。
2. Combiner
Combiners:MapReduce作业受到集群可用带宽的限制,因此它可以最大限度地减少map和reduce任务之间传输的数据。Hadoop允许用户在Mapper输出上运行Combiner - Combiner函数的输出格式与reduce函数的输入一致。Combiner是可选的,是MapReduce的一个优化技巧,因此对于一个特定Mapper输出记录,Hadoop也不会知道Combiner会运行几次。换句话说,Combiner运行0次,一次或者多次,reducer都会产生相同的输出结果。Combiner多次运行,并不影响输出结果,运行Combiner的意义在于使map输出的中间结果更紧凑,使得写到本地磁盘和传给Reducer的数据更少。我们可以把Combiners理解为发生在shuffle和sort阶段之前,对Mapper输出进行操作的"mini-reducers"。每个Combiner单独操作于一个Mapper,因此不能访问其他Mapper输出的中间结果。Combiner提供与每个键相关联的键和值(与Mapper输出键和值相同的类型)(The combiner is provided keys and values associated with each key (the same types as the mapper output keys and values))。关键的是,我们不能假设一个Combiner将有机会处理与同一个键相关联的所有值(Critically, one cannot assume that a combiner will have the opportunity to process all values associated with the same key),一个Combiner只能访问一个Mapper的中间输出结果,对于其他Mapper的中间输出结果无权访问。Combiner可以输出任意数量的键值对,但是键和值必须与Mapper输出具有相同的类型(与Reducer输入相同)。当一个操作满足结合律和交换律(例如,加法或乘法)的情况下,Reducer可以直接用作Combiner。然而,一般来说,Reducer和Combiner是不可互换的。
3. 区别
Partitioner与Combiner之间的区别在于,Partitioner根据Reducer的数量来划分数据,使得单个分区中的所有数据由单个Reducer执行。然而,Combiner功能类似于Reducer,处理每个分区中的数据。Combiner是Reducer的一种优化。根据key或者value的一些其他函数划分数据可能是有用处的,但是Combiner不一定会提供性能。你应该监视作业的行为,以查看Combiner输出的记录数是否明显小于记录数。你可以通过JobTracker Web UI轻松检查。