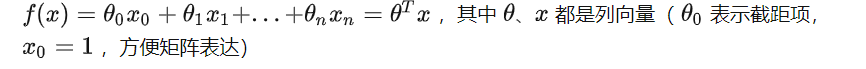版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/sinat_32502811/article/details/81058295
前面,对于线性可分的数据,我们采用硬间隔最大化的策略,来训练线性可分支持向量机。回忆一下,之前的最优化问题的表示为:
minω,b12∥ω∥2s.t.yi(ω⋅xi+b)−1≥0,i=1,2,⋯,Nminω,b12‖ω‖2s.t.yi(ω⋅xi+b)−1≥0,i=1,2,⋯,N
我们可以将其称为原始问题。通过拉格朗日对偶性,通过求解对偶问题(dual problem)来得到原始问题(primal problem)的最优解。这就是线性可分支持向量机的对偶算法。
引入对偶问题的主要目的就是让问题更容易求解。还有一点就是自然引入核函数,从而将SVM推广到非线性分类问题中。
拉格朗日函数
原始问题
我们说利用拉格朗日对偶性去简化问题,那拉格朗日对偶性是啥呢?(大学微积分里好像学过···) 接下来进行简单介绍。
首先,拉格朗日对偶性主要是用来求解约束最优化问题的。那问题的表现形式是什么呢?也就是原始问题:假设f(x),ci(x),hj(x)f(x),ci(x),hj(x)是定义在RnRn上的连续可微函数,考虑约束最优化问题:
minx∈Rnf(x)⋯⋯(1)minx∈Rnf(x)⋯⋯(1)
s.t.ci(x)≤0,hj(x)=0⋯⋯(2)s.t.ci(x)≤0,hj(x)=0⋯⋯(2)
那么拉格朗日对偶性怎么用到这个问题上呢?
首先,我们引入拉格朗日函数
L(x,α,β)=f(x)+∑i=1kαici(x)+∑j=1lβjhj(x)L(x,α,β)=f(x)+∑i=1kαici(x)+∑j=1lβjhj(x)
这里
αi,βjαi,βj就是拉格朗日乘子,
αi≥0αi≥0.
由上面的(2)式,我们知道
hj(x)hj(x)是都为0的,所以和也应该是0的;
ci(x)≤0ci(x)≤0,而它的拉格朗日系数
αiαi优势大于等于0的,所以二者的乘积和是小于等于0的。我们的优化目的是使
f(x)f(x)最小,那么三者相加,也就是我们的拉格朗日函数L = 待求最小+非正数+0,如果f(x)最小的话,那么就需要拉格朗日函数
L(x,α,β)L(x,α,β)最大,并且最大为f(x)。也就是,我们的原始问题可以变成以下的描述形式:
θp(x)=maxα,β;αi≥0L(x,α,β)θp(x)=maxα,β;αi≥0L(x,α,β)
这里的下标p表示primal,原始问题。
我们假设,给定某个x违反了原始问题的约束条件,那么
θp(x)=maxα,β;αi≥0[f(x)+∑ki=1αici(x)+∑lj=1βjhj(x)]=+∞θp(x)=maxα,β;αi≥0[f(x)+∑i=1kαici(x)+∑j=1lβjhj(x)]=+∞,相反的,如果x满足条件,就会像刚才我们分析的那样,
θp(x)=f(x)θp(x)=f(x).所以,
θp(x)={f(x),+∞,x满足原始问题约束othersθp(x)={f(x),x满足原始问题约束+∞,others
所以,为了让经过拉格朗日函数变换的问题和原始问题等价,我们还得对
θp(x)θp(x)取极小。也就是说:
minxθp(x)=minxmaxα,β;αi≥0L(x,α,β)minxθp(x)=minxmaxα,β;αi≥0L(x,α,β)
这个是与原始问题等价的。而上式就被称为
广义拉格朗日函数的极小极大问题。因此,也就是说原始的约束最优化问题可以转化成广义拉格朗日函数的极小极大问题。
我们定义原始问题的最优值为
p∗=minxθp(x)p∗=minxθp(x)为原始问题的值。
对偶问题
原始问题为广义拉格朗日函数的极小极大问题,那么他的对偶问题为拉格朗日函数的极大极小问题。即:
maxα,β;αi≥0θD(α,β)=maxα,β;αi≥0minxL(x,α,β)maxα,β;αi≥0θD(α,β)=maxα,β;αi≥0minxL(x,α,β)
s.t.αi≥0,i=1,2,⋯,Ns.t.αi≥0,i=1,2,⋯,N
定义对偶问题的最优值
d∗=maxα,β;αi≥0θD(α,β)d∗=maxα,β;αi≥0θD(α,β)为对偶问题的值。
原始问题和对偶问题的关系
有了原始问题的描述形式及最优值得表示和其对偶问题得描述形式和最优值表示,二者是什么关系呢?
若原始问题和对偶问题都有最优值,二者得关系为:
d∗=maxα,β;αi≥0minxL(x,α,β)≤minxmaxα,β;αi≥0L(x,α,β)=p∗d∗=maxα,β;αi≥0minxL(x,α,β)≤minxmaxα,β;αi≥0L(x,α,β)=p∗
很好证明,连接桥梁为L(x,θ,β)L(x,θ,β),一个是最小值,一个是最大值,所以θD(α,β)θD(α,β)肯定小于等于θp(x)θp(x),那θDθD得最大值肯定也小于等于θpθp得最小值,所以得证。
其他
- 如果上面得等号成立,即d∗=p∗d∗=p∗,那么此时得α∗,β∗,x∗α∗,β∗,x∗分别是原始问题和对偶问题得最优解。
- KKT条件(非常重要)
- 对原始问题和对偶问题,假设函数f(x),ci(x)f(x),ci(x)是凸函数,hj(x)hj(x)是仿射函数(仿射函数,即最高次数为1的多项式函数。常数项为零的仿射函数称为线性函数),并且不等式约束ci(x)ci(x)严格可行,则α∗,β∗和x∗α∗,β∗和x∗分别是对偶问题和原始问题的解的充要条件是α∗,β∗和x∗α∗,β∗和x∗满足下面的KKT条件:
▽xL(x∗,α∗,β∗)=0α∗ici(x∗)=0,i=1,2,⋯,kci(x∗)≤0,i=1,2,⋯,kα∗i≥0,i=1,2,⋯,khj(x∗)=0,j=1,2,⋯,l▽xL(x∗,α∗,β∗)=0αi∗ci(x∗)=0,i=1,2,⋯,kci(x∗)≤0,i=1,2,⋯,kαi∗≥0,i=1,2,⋯,khj(x∗)=0,j=1,2,⋯,l
2. 特别指出,第四个公式称为KKT的对偶互补条件。由此条件可知,若α∗i>0αi∗>0,则ci(x∗)=0.ci(x∗)=0.
学习的对偶算法
讲完了拉格朗日函数以及KKT条件,接下来可以讲SVM是如何利用拉格朗日函数求解原始问题的。我们再回忆一下原始问题长什么样:
minω,b12∥ω∥2s.t.yi(ω⋅xi+b)−1≥0,i=1,2,⋯,Nminω,b12‖ω‖2s.t.yi(ω⋅xi+b)−1≥0,i=1,2,⋯,N
按照拉格朗日法构建拉格朗日函数,里面的f(x)是
12∥ω∥212‖ω‖2,
ci(x)ci(x)就是
yi(ω⋅xi+b)−1≥0,i=1,2,⋯,Nyi(ω⋅xi+b)−1≥0,i=1,2,⋯,N,但是要注意的是,
ci(x)≤0ci(x)≤0,而我们的式子是大于等于0的,所以要变换过来,也就是
−yi(ω⋅xi+b)+1≤0,i=1,2,⋯,N−yi(ω⋅xi+b)+1≤0,i=1,2,⋯,N.好了,现在可以写出我们的拉格朗日函数了:
L(ω,b,α)=12∥ω∥2+∑i=1Nαi(−yi(ω⋅xi+b)+1)=12∥ω∥2−∑i=1Nαi(yi(ω⋅xi+b))+∑i=1Nαi其中,αi≥0,i=1,2,⋯,N(拉格朗日乘子)L(ω,b,α)=12‖ω‖2+∑i=1Nαi(−yi(ω⋅xi+b)+1)=12‖ω‖2−∑i=1Nαi(yi(ω⋅xi+b))+∑i=1Nαi其中,αi≥0,i=1,2,⋯,N(拉格朗日乘子)
根据拉格朗日对偶性,原始问题是极小极大问题,它的对偶问题是极大极小问题,即
maxαminω,bL(ω,b,α)maxαminω,bL(ω,b,α)
所以,为了求对偶问题的解,需要先求L对
ω,bω,b的极小,再求对
αα的极大。所以问题就分为了两步:
1. 求
minω,bL(ω,b,α)minω,bL(ω,b,α)
L对
ω,bω,b分别求偏导,并令导数为0.即:
▽ωL(ω,b,α)=ω−∑i=1Nαiyixi=0▽bL(ω,b,α)=−∑i=1Nαiyi=0▽ωL(ω,b,α)=ω−∑i=1Nαiyixi=0▽bL(ω,b,α)=−∑i=1Nαiyi=0
于是,我们得到
ω=∑i=1Nαiyixi∑i=1Nαiyi=0ω=∑i=1Nαiyixi∑i=1Nαiyi=0
讲
ωω回代到拉格朗日函数
L(ω,b,α)L(ω,b,α)中,并利用
∑Ni=1αiyi=0∑i=1Nαiyi=0,L函数就变成了如下:
L(ω,b,α)−b∑i=1Nαiyi+∑i=1Nαi=12∑i=1N∑j=1Nαiαjyiyj(xi⋅xj)−∑i=1Nαiyi((∑j=1Nαjyjxj)⋅xi+b)+∑i=1Nαi=12∑i=1N∑j=1Nαiαjyiyj(xi⋅xj)−∑i=1Nαiyi((∑j=1Nαjyjxj)⋅xi)=−12∑i=1N∑j=1Nαiαjyiyj(xi⋅xj)+∑i=1NαiL(ω,b,α)=12∑i=1N∑j=1Nαiαjyiyj(xi⋅xj)−∑i=1Nαiyi((∑j=1Nαjyjxj)⋅xi+b)+∑i=1Nαi=12∑i=1N∑j=1Nαiαjyiyj(xi⋅xj)−∑i=1Nαiyi((∑j=1Nαjyjxj)⋅xi)−b∑i=1Nαiyi+∑i=1Nαi=−12∑i=1N∑j=1Nαiαjyiyj(xi⋅xj)+∑i=1Nαi
即
minω,bL(ω,b,α)=−12∑i=1N∑j=1Nαiαjyiyj(xi⋅xj)+∑i=1Nαiminω,bL(ω,b,α)=−12∑i=1N∑j=1Nαiαjyiyj(xi⋅xj)+∑i=1Nαi
2. 求
minω,bL(ω,b,α)minω,bL(ω,b,α)对
αα的极大
maxα−12∑i=1N∑j=1Nαiαjyiyj(xi⋅xj)+∑i=1Nαis.t.∑i=1Nαiyi=0αi≥0,i=1,2,⋯,Nmaxα−12∑i=1N∑j=1Nαiαjyiyj(xi⋅xj)+∑i=1Nαis.t.∑i=1Nαiyi=0αi≥0,i=1,2,⋯,N
将上式由求极大变成求极小,也就是加个负号,就变成了
minα12∑i=1N∑j=1Nαiαjyiyj(xi⋅xj)−∑i=1Nαis.t.∑i=1Nαiyi=0αi≥0,i=1,2,⋯,Nminα12∑i=1N∑j=1Nαiαjyiyj(xi⋅xj)−∑i=1Nαis.t.∑i=1Nαiyi=0αi≥0,i=1,2,⋯,N
上面三式就是原始问题的对偶问题,并且存在
ω∗ω∗是原始问题的解,
α∗,β∗α∗,β∗是对偶问题的解。
对线性可分数据集,假设对偶最优化问题对
αα的解为
α∗=(α∗1,α∗2,⋯,α∗N)Tα∗=(α1∗,α2∗,⋯,αN∗)T,可以由
α∗α∗求得原始最优化问题的解
(ω∗,b∗)(ω∗,b∗),有如下关系
ω∗=∑i=1Nα∗iyixib∗=yj−∑i=1Nα∗iyi(xi⋅xj)ω∗=∑i=1Nαi∗yixib∗=yj−∑i=1Nαi∗yi(xi⋅xj)
我认为,利用对偶问题求解,主要简化了待求参数的数量。在原始问题中,为了求间隔最大的分离超平面,将问题转化成了约束最优化问题,需要求的参数为ω,bω,b,两个。但是对偶问题,我只需要求一个αα,利用αα就可以得到ω,bω,b。而且,只有一个参数的最优化问题理论上来说也更好解。
推导过程(根据KKT条件)
根据KKT条件,有:
▽ωL(ω∗,b∗,α∗)=ω∗−∑i=1Nα∗iyixi=0▽bL(ω∗,b∗,α∗)=−∑i=1Nα∗iyi=0α∗i(yi(ω∗⋅xi+b∗)−1)=0yi(ω∗⋅xi+b∗)−1≥0α∗i≥0▽ωL(ω∗,b∗,α∗)=ω∗−∑i=1Nαi∗yixi=0▽bL(ω∗,b∗,α∗)=−∑i=1Nαi∗yi=0αi∗(yi(ω∗⋅xi+b∗)−1)=0yi(ω∗⋅xi+b∗)−1≥0αi∗≥0
由此可得:
ω∗=∑i=1Nα∗iyixiω∗=∑i=1Nαi∗yixi
其中,至少有一个
α∗j>0αj∗>0(反证法),对此j有
yj(ω∗⋅xj+b∗)−1=0(∗)yj(ω∗⋅xj+b∗)−1=0(∗).而
yjyj是代表类别的,取值只有{+1,-1},所以
y2j=1yj2=1.将
ω∗ω∗取值代入(*)式,左右两侧同乘
yjyj,即得
b∗=yj−∑i=1Nα∗iyi(xi⋅xj)b∗=yj−∑i=1Nαi∗yi(xi⋅xj)
因此分离超平面就可以写成
∑i=1Nα∗iyi(x⋅xi)+b∗=0∑i=1Nαi∗yi(x⋅xi)+b∗=0
分类决策函数就可以写为:
f(x)=sign(∑i=1Nα∗iyi(x⋅xi)+b∗)f(x)=sign(∑i=1Nαi∗yi(x⋅xi)+b∗)
由上式,以及
b∗b∗的表达式我们可以知道,
分离超平面与分类决策函数都是只和输入x和其内积有关。
于是,对于线性可分数据集,我们可以首先求对偶问题的解
α∗α∗,再利用
ω∗,b∗ω∗,b∗和
α∗α∗的关系,求原始问题的解
ω∗,b∗ω∗,b∗,从而得到分离超平面和觉得函数。
这就是
线性可分支持向量机的对偶学习算法,也是其基本算法。
上述过程作为算法描述如下:
1. 构造求解约束最优化问题:
minα12∑i=1N∑j=1Nαiαjyiyj(xi⋅xj)−∑i=1Nαis.t.∑i=1Nαiyi=0αi≥0,i=1,2,⋯,Nminα12∑i=1N∑j=1Nαiαjyiyj(xi⋅xj)−∑i=1Nαis.t.∑i=1Nαiyi=0αi≥0,i=1,2,⋯,N
求得最优解
α∗=(α∗1,α∗2,⋯,α∗N)Tα∗=(α1∗,α2∗,⋯,αN∗)T.
2. 由
α∗α∗得到
ω∗ω∗,
ω∗=∑i=1Nα∗iyixiω∗=∑i=1Nαi∗yixi
.选择
α∗α∗的一个正分量,即
α∗j>0αj∗>0,计算
b∗=yj−∑i=1Nα∗iyi(xi⋅xj)b∗=yj−∑i=1Nαi∗yi(xi⋅xj)
3.
ω∗,b∗ω∗,b∗代入,求得分离超平面和分类函数。
在对偶算法中去描述支持向量,就是对应于数据中α∗i>0αi∗>0 的实例点。这其实与前面我们定义的支持向量是等价的。
以上就是针对线性可分数据集的对偶算法及推导。(看来多看几遍还是有用的,现在又多明白了一些·····)