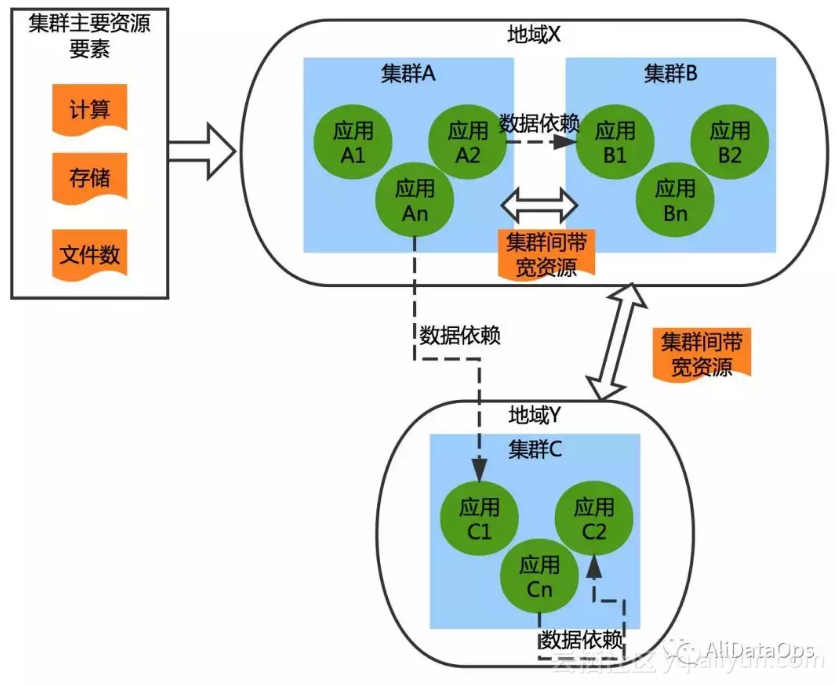
Maxcompute(原ODPS)是阿里唯一的自研大数据平台,平台承载了不可丢失的交易数据。内部是一个逻辑统一大数据池, EB级数据透明的相互依赖。但其在物理上却是横跨多地域庞大数量构成的集群组合. 这在容量问题上面会带来物理资源瓶颈无法满足业务需求的巨大挑战。
——对于集群(cluster),存在计算、存储、文件数等多个维度的资源,集群间存在通信的带宽资源,带宽成本因集群间的距离而不同;
——对于应用(project),各个应用对不同维度的资源的消耗存在差异,对于计算资源的消耗,存在很强的时段差异性;
——此外应用之间存在数据访问依赖,会消耗集群间的带宽资源。随着业务的日益发展,集群个数和规模在不断扩大,应用间的依赖也愈发复杂。
我们要解决的问题
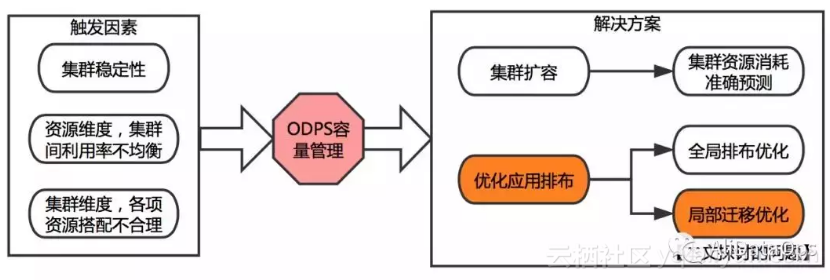
当任何一个集群计算、存储、文件数资源达到瓶颈都会对集团的业务造成影响,同时降低其他资源的使用效率,这就引发了Maxcompute的容量管理问题。目前对于容量问题主要有两大解决方案。
通过采购机器进行扩容,这要求我们对集群未来的资源消耗做出精准的预测,做出合理的采购预算;
优化 Maxcompute 应用在不同集群的排布,包括全局排布优化和局部迁移策略的优化。所谓全局排布优化,相当于将线上应用全部打乱,重新在各个集群间进行分配。
而局部迁移策略优化,是针对那些资源遇到瓶颈,稳定性可能受到影响的集群,提前做出应用的调度。受限于应用迁移的自动化程度、迁移效率、实际业务情况,全局排布优化的工程化实施还有一定困难。
当前我们在采购预算和局部应用迁移两个方面都取得了一定的进展,本文将详细解读如何利用数据+算法的方案来解决局部应用迁移优化的策略。
过去Maxcompute中应用的迁移强依赖于运维人员的经验,运维人员对各个维度资源的“危险水位”有着一定的敏感度,基于对各个业务的了解,在某个集群某个维度的资源到达危险水位时,制定出一些应用(project)的迁移方案。 但人工决策存在很多局限:
● 集群的资源维度多,运维人员每天需要花大量的时间查看监控指标,但依旧可能遗漏或未能及时发现迁移需求。● 线上的project众多,每个project也有多维的属性,project之间因为业务因素存在不同强度的数据依赖,人工很难全面考虑各个因素做出最优的迁移决策,运维人员通常根据业务归属,从较粗的粒度制定迁移计划。
● project的迁移会牵一发而动全身,带来各个层面的影响。
在迁移策略真正执行之前,人工难以准确地预估和量化这些影响,通常为了防止迁移后接受集群的资源不足或者出现集群间带宽被承包,运维人员作出的迁移计划一般较为保守。
2 DataOps数据驱动引入新思路
运维人员的资源调度经验十分宝贵,但作为大数据计算平台的建设和服务者,我们应该把握好数据这一利器,充分利用数据进行决策,突破人工运维存在的一些瓶颈。
● 迁移需求的及时甚至提前感知● 最优Project迁移策略的精细化求解
● 迁移结果的准确量化评估。
3 优化算法设计思路
3.1 整体解决方案设计
整体解决方案主要分为三个步骤:
● 集群层面的迁移需求判定和量化 即确定哪些集群需要迁移,各项资源需要迁移多少量;那些集群可以接收迁移,各项资源的容纳能力是多少。● 线性规划求解最优迁移策略 这一步的目的是挑选出最合适的project迁移到最合适的集群。
● 迁移影响的量化估计:分析本次迁移对集群资源水位和带宽消耗会产生什么影响,因为现实场景较复杂,存在跨集群复制等问题,有些影响需要得到迁移策略后,根据新的project排布才能模拟计算出影响的大小。
量化影响的目的是给运维人员一个图形化的直观展现,特别是算法运行初期,可以帮助运维人员判断算法的可行性。
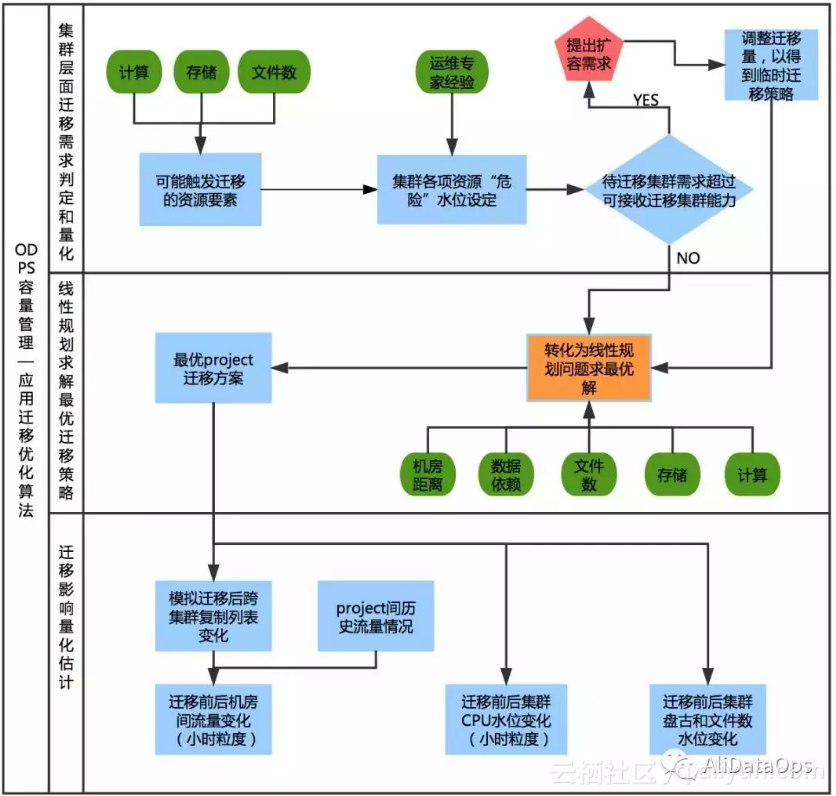
3.2 集群层面的迁移需求判定和量化
在Maxcompute当前线上每个集群的服务器规模、计算和存储能力及弹性均不相同。
因此我们结合运维人员的专家经验以及集群历史运行情况,为每个集群的每项资源均设定了个性化的“需迁移水位”和“可接收水位”。
其次,Maxcompute的资源使用存在明显的“高峰时段”,在量化迁移需求时,我们主要考虑高峰时段的水位,结合集群资源总体容量进而可以得到具体的需迁移量和可接收量。
另外,存在所有待迁移集群的需求超过所有可接收集群的能力的情况,此时表明平台整体有扩容需求,但由于采购需要一段时间,因此算法会根据接收能力调整迁移需求,产生临时性的迁移方案,以解决眼前线上的问题。
3.3 线性规划优化问题定义和求解
● 问题分析 :当我们确定了集群层面的迁移需求和接收能力后,需要从待迁移集群的众多project中选择最佳的迁移方案。这个迁移方案需要考虑以下几点:
● 既需要满足各个待迁移集群计算、存储和文件数的迁移需求,也不能超过接收集群各项资源的容纳能力。● 与存储和文件数不同,由于project的计算资源消耗具有很强的时段性,因此对于计算资源需要细化到小时粒度考虑。
● 前面提到应用间存在数据访问依赖,将消耗集群间的带宽,且位于不同地域的集群间带宽成本不同。project的迁移应尽量控制集群间的带宽消耗。
上面的过程可以表述成一个带约束条件的优化问题,且约束和目标函数均是线性的。线性规划是最著名的解决最优化问题的方法之一。典型的线性规划问题的标准形式如下:
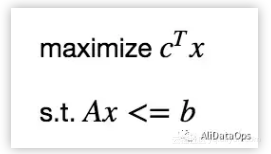
即决策变量是01变量,因此这个线性规划问题其实是01整数规划。目标函数中我们考虑了机房间的距离(带宽成本)以及应用间的数据依赖。
约束条件中我们考虑待迁移集群各项资源的迁移需求和可接收集群的接纳能力。
(以下为节选约束和变量说明)

project迁移对集群的影响可以帮助运维人员直观地看到本次迁移的效果和影响,具体可以分为三大部分进行分析。
原因在于,根据project之间的数据依赖以及当时的project的集群排布情况,线上每天会根据较复杂的一些规则产生一份跨集群复制列表,将原本需要跨集群直读的数据转化为集群内部的读取。
因此,在迁移策略真正产生之前,我们无法预估线上集群间的流量。而在我们的线性规划问题求解出迁移策略后,我们需要根据规则和新的project排布模拟出新的跨集群复制列表,再根据线上历史真实流量情况估计本次project迁移带来的机房间流量变化。
5 应用效果
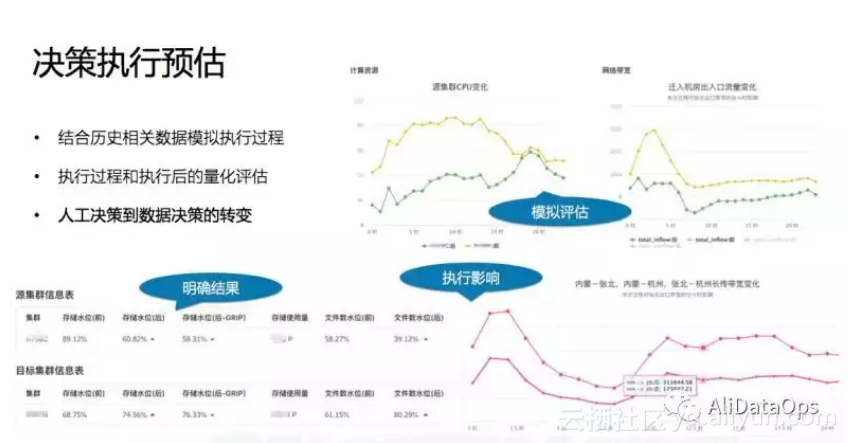
智能迁移功能让运维人员对于每次的迁移任务都拥有量化的精准评估,以及可视化的直观感受。
在该平台上,运维既可以看到平台根据当前各个集群水位动态计算出来的迁移方案,也可以输入一些个性化的迁移需求和约束,来定制一套最优的迁移策略。通过作业平台的并行调度,平台支持多个运维人员同时操作和计算。
对于每个迁移需求,详细求解并展示出结果:
(1)算法得到的具体最优迁移策略
(2)预计迁移前后集群计算和存储资源水位变化
(3)预计迁移前后集群间流量变化
(4)预计迁移前后跨地域带宽使用率变化
Project 迁移优化是面向大数据离线业务用 DataOps 驱动实现容量管理资源排布的一次智能化落地的技术探索。算法模型中综合多个维度的资源因素,可以在给定的约束条件下找到最优的迁移策略,同时可以量化迁移带来的影响。
原文发布时间为:2018-08-30
本文作者:张颖莹