为了避免不必要的麻烦,先说一下我的系统版本
Python 3.6 tensorflow 1.10 windows 7
object detection API安装
object detection API 安装参见官方的github: https://github.com/tensorflow/models/tree/master/research/object_detection
这里需要特别强调一下,一定要检查一下,下面的python的包都安装了,方法很简单,全部执行一遍
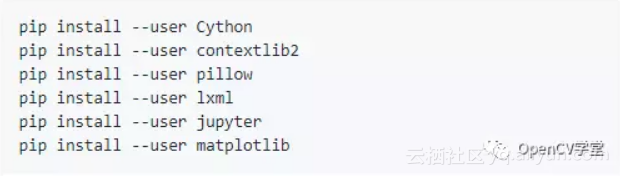
windows下面不需要--user选项,Oxford-IIIT Pet 数据集使用coco metrix, 所以下面必须执行这个命令行:
-
pip install git+https://github.com/philferriere/cocoapi.git#subdirectory=PythonAPI
在windows下面遇到utf-8编码错误
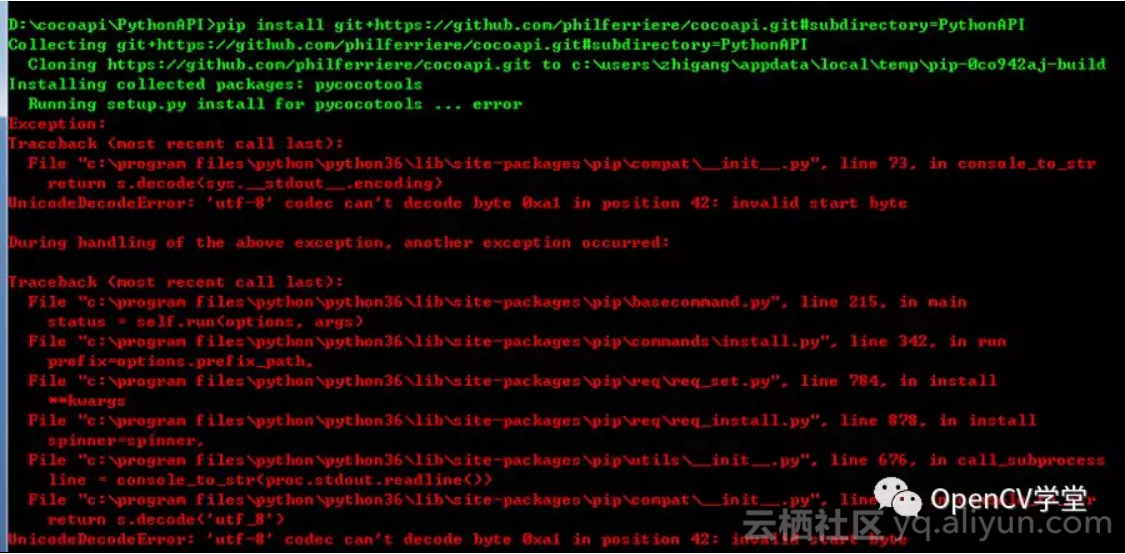
如下修正:
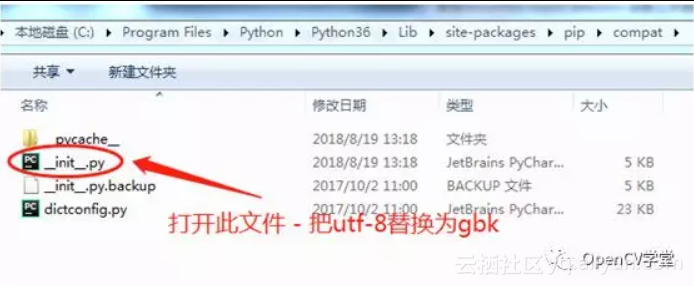
C:\Program Files\Python\Python36\Lib\site-packages\pip\compat\_init_.py
79行改成gbk, utf-8替换为gbk, 不一定是是79行。再次执行即可成功安装
创建训练数据记录tfrecord
下载好Oxford-IIIT Pets Dataset数据集,解压缩到这里
然后执行下面的命令行:

训练数据成功创建在指定目录:先切换到指定目录,完整的命令行执行
-
D:\tensorflow\models\research>python objectdetection/datasettools/createpettfrecord.py --labelmappath=objectdetection/data/petlabelmap.pbtxt -
--datadir=D:/petdata --output-dir=D:\tensorflow\mytrain\data -
还不会看这里: -
https://github.com/tensorflow/models/blob/master/research/objectdetection/g3doc/preparing_inputs.md
迁移学习
这步成功以后,就可以开始执行真正的训练啦,等等,别着急,我们是基于预训练模型的迁移学习,所以还有几件事情必须搞定,
下载预训练的tensorflow模型,我这里下载的是
![]()
http://download.tensorflow.org/models/objectdetection/ssdmobilenetv1coco201801_28.tar.gz
解压缩到指定目录,我的完整目录结构如下:

其实有+加号的表示目录文件夹, - 表示文件
labelmap file来自 D:\tensorflow\models\research\objectdetection\data\petlabelmap.pbtxt pipeline config file来自 D:\tensorflow\models\research\objectdetection\samples\configs\ssdmobilenetv1pets.config
直接copy过来,然后打开
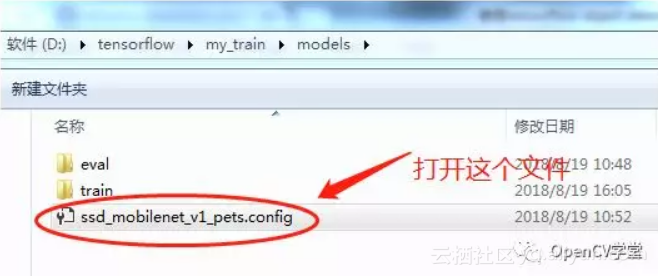
开始修改,把所有【PATH_TO_BE_CONFIGURED】都改到正确路径上来:

保存好啦,然后直接执行训练的命令行:
![]()
各个参数选项解释如下:
--pipelineconfigpath
训练时候配置目录,所有关于训练各种输入路径、参数模型、参数网络配置,都在这个里面。
--modeldir
训练时候会写文件的目录,训练完成输出的模型保存目录
--numtrainsteps
训练多少个steps
--numeval_steps
多少个eval, 基本上两者要相差10倍以上 steps : eval
--alsologtostderr
表示日志信息
如果遇到这个错误
TypeError: can't pickle dictvalues objects
这样修改,打开model_lib.py
D:\tensorflow\models\research\objectdetection
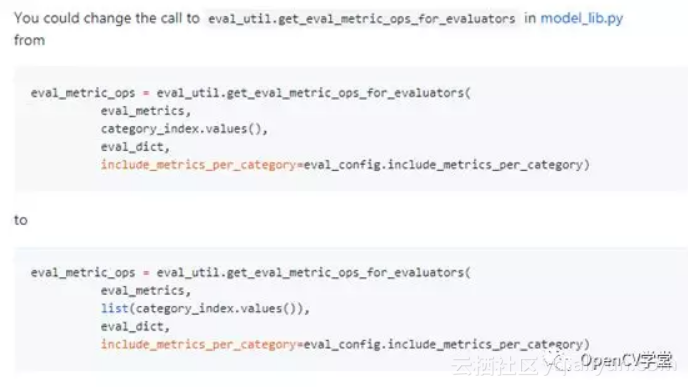
继续训练就会很OK
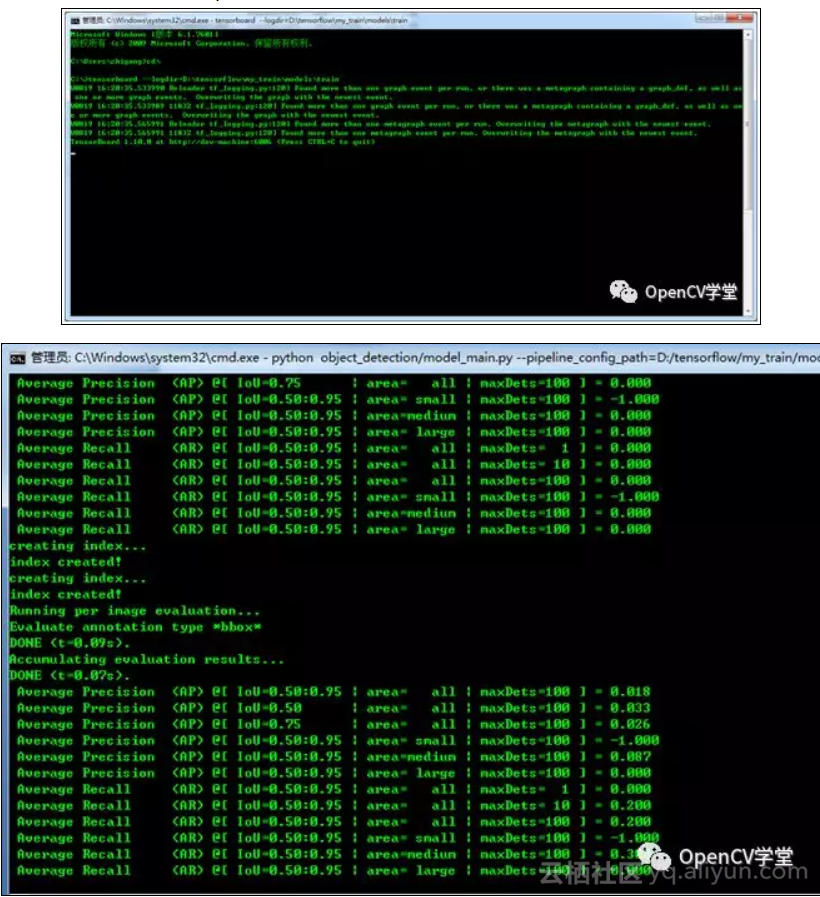
启动tensorboard查看训练过程: CPU 太慢了,半天走一个step
原文发布时间为:2018-08-27
本文作者:gloomyfish