t-分布领域嵌入算法(t-SNE, t-distributed Stochastic Neighbor Embedding )是目前一个非常流行的对高维度数据进行降维的算法, 由Laurens van der Maaten和 Geoffrey Hinton于2008年提出。这个算法已经在机器学习领域被广泛应用,因为它可以有效的将高维度数据转换成二维图像。虽然如此, 在使用这个算法时,可能会产生一些错误认识,这篇文章就是为了防止这些认识上的常见错误。
我们会通过一系列的例子来阐述t-SNE图像。只有在正确地理解了这些图像以后, t-SNE算法才能被真正地很好使用。
在开始之前,如果你还没有接触过t-SNE算法, 这里就对这个算法背后的一些数学知识做一个简单的介绍。 这个算法的目的是将高维度空间中的数据点集合在一个低维度空间中准确的表示出来。这里低维度空间一般指二维空间。这个算法是非线性的并能适应底层数据,在不同领域中进行不同的转换。而这些不同可能是产生歧义的主要原因。
t-SNE算法的另一个特性就是支持调优参数-困惑度,简单来说它是用来平衡数据的局部和全局关注度。换句话说,这个参数是对每个数据点相邻数据点数量的猜测。困惑度会对最后产生的二维图像有复杂的影响。在原始的论文中是这样阐述的:“SNE的性能对于困惑度的改变还是相当可靠的,而困惑度典型值一般在5到50之间”。而事实上比这个阐述更复杂,我们需要对不同困惑度下产生的结果进行分析,这样才能体现t-SNE算法的真正价值。
这个算法的复杂性不止于此。t-SNE算法可能在连续的运行中不总能得出相似的结果。比如,在优化过的工程中有额外的超参数。
1. 那些超参数会产生影响
让我们从t-SNE算法的“hello world”开始:现在有一组数据,分成了两个聚簇。方便起见,我们将这两个聚簇在一个二维空间中,标记成两种不同颜色。右图显示了在五个不同困惑度下t-SNE结果图。

在van der Maaten和Hilton的建议值(5-50)下,图示出这些聚簇,即使他们的形状不同。在范围之外,图片的显示就有点奇怪。在困惑度2的情况下,局部变量起到主导作用。而困惑度100的图片,这里这个算法就有个小陷阱,两个原本聚簇点集合并在一起了。为了使该算法运行正确,困惑度的值应该小于数据点的数量,如果不是这样,那最终的结果可能会产生异常。
以上的例子都被设定成5000次迭代和10的学习度,并且我们可以看到它们都能在5000次迭代前达到一个稳定状态。那这两的数值该如何选取呢?就我们的经验来说,最重要的是迭代次数的选取一定要使结果到达一个稳定的状态。

以上的例子显示了在困惑度30下,五个不同的运行结果。前四个在稳定前就停止了。在10,20,60和120迭代后,显示出来的是类似一维图像,甚至单点图像。 如果一个t-SNE图像有着被挤压的图形,很有可能是因为迭代次数还不够。不幸的是,并没有一个固定的值能保证得到一个稳定的结果。不同的数据集需要不同的迭代次数。
另一个问题是有着相同超参数的不同运行是否会产生同样的结果。在这个我们已经讨论过的两聚簇的例子中,多次运行的结果有着相同的全局形状。然而,某些数据集在不同运行中产生明显不同的图; 我们将举一个例子。
从这里开始,除非特殊说明,我们讨论的例子都是基于5000次迭代的结果。这样基本能涵盖这篇文章所涉及的多数例子。我们仍会使用不同的困惑度,因为它会产生许多不同的结果。
2. t-SNE中聚簇的大小无关紧要
如果两个聚簇有不同的标准偏差和不同的大小(这里的大小是指边界框的大小,而不是数据点的数量)呢?下面是混合高斯模型在平面中的t-SNE结果图像,其中一个的分散度是另一个的10倍。

令人惊讶的是,两个聚簇在t-SNE图像中看起来大小相同。 这是怎么回事?t-SNE算法使得“距离”这个概念能适应数据集中的区域密度变化。因此,它自然地扩展密集的聚簇,并收缩稀疏的聚簇,平均聚簇的大小。显然,这个特别的效果不同于任何维度降低技术都破坏距离的事实(毕竟,在这个例子中,所有数据都是二维的。)。相反,密度均衡在t-SNE算法中是经过设计的,并且也是t-SNE算法的可预测特征。
然而,归根结底在t-SNE图中看不到簇的相对大小。
3. 两个聚簇间的距离可能不表示任何东西
那么两个聚簇间的距离呢?下图显示了三个高斯聚簇,分别有50数据点。一对之间的距离是另一对的5倍。

在困惑度50的情况下,图示结果给出了很好的全局几何。对于较低的困惑度,聚簇看起来是等距的。 当困惑度为100时,我们看到全局几何图形很精细,但是其中一个聚簇表现得不准确,比其它两个小得多。由于困惑度50在这个例子中给了我们一个比较好的结果,那么如果我们想要看到全局几何,是否可以将困惑度总是为50呢?
可惜的是答案是否定的。 如果我们向每个聚簇中添加更多的点,那我们必须提高困惑度来加以补偿。 这里是三个高斯聚簇的t-SNE算法结果图像,每个具有200数据点,而不是之前的50个。现在没有一个困惑度值能给出了一个令人满意的结果。

因此想要得到完善的全局几何,就需要对困惑度进行调整。而现实世界中的数据可能有着包含不同数量元素的不同聚簇。那就可能导致没有一个困惑度将适用于所有聚簇的距离,因为困惑度是一个全局性的参数。 解决这个问题可能是未来研究的一个领域。
因此,在t-SNE算法结果图像中分离良好的聚类之间的距离可能没有什么意义。
4. 随机噪声不总是看起来随机
一个典型的错误观点就是认为你看到的模式就是随机数据。能够识别出噪音是一项重要的能力,而培养出这种准确的自觉是需要时间的。关于t-SNE算法的一个棘手的事情是它在窗口中抛出了很多现有的直觉。下图显示真正随机数据,从100维的单位高斯分布绘制的500点。 左边的原图是前两个坐标上的投影。
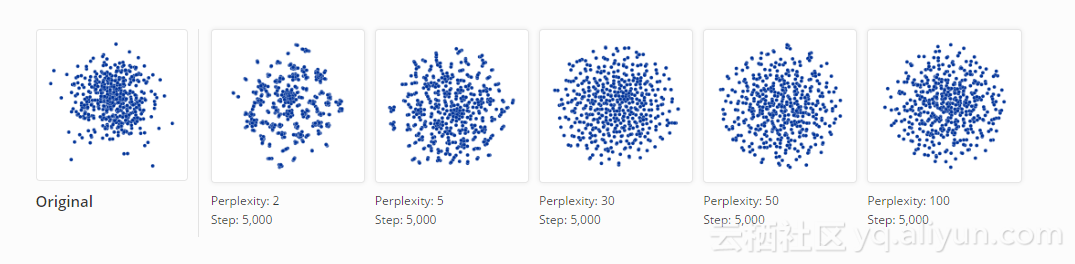
当困惑度设为2时,它似乎表现出非常强的聚簇性。 如果你通过调整困惑度从而提取出数据中的结构,那你可能会认为你中了大奖。
当然,由于我们知道这些数据点是随机生成的,统计学上对这些聚簇不感兴趣:这些“团块”没有任何意义。 如果回头看前面的例子,低困惑度通常导致了这种分布。 将这些聚簇识别为随机噪声是读取t-SNE图的重要部分。
还有一些有趣的现象,可以作为t-SNE算法的优点。首先,困惑度30下的图像不像高斯分布:在这个数据点集不同区域之间,数据点分布的密度差异非常细微,几乎可以看成均匀分布。事实上,这些特征对于高维正态分布是有用的,这些分布非常接近于球体上的均匀分布,点与点之间具有大致相等的空间。从这个角度看,t-SNE算法得出的图像比任何线性投影都更准确。
5. 有时你可以看到一些形状
数据点很少以完全对称的方式分布。 让我们来看看50维度下轴对准高斯分布,其中坐标i的标准偏差是1 / i。 也就是说,我们可以看到一个长长的椭圆形点阵。
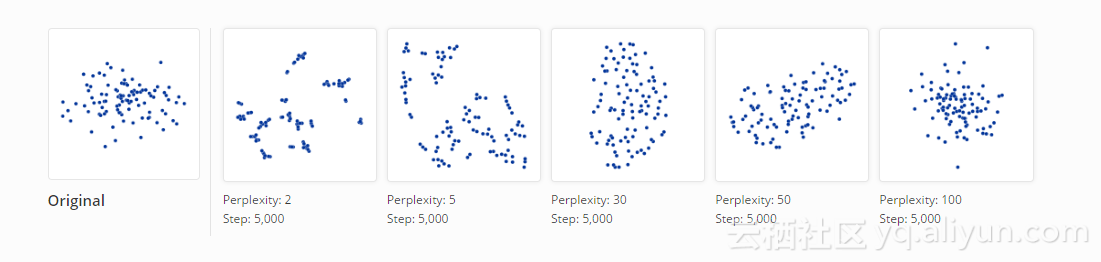
对于足够高的困惑度,我们可以容易地得到细长形状。如果困惑度偏低,局部效应和无意义的“聚集”将占据图像的中心。 在特定的困惑度下,更极端的形状也可能出现。 例如,这里是两个二维的75个点的聚簇,他们就呈现出具有一些噪声点的两条平行线。

对于一定范围的困惑度,长条形的聚簇点阵看起来更正确一点。
即使在最好的情况下,该算法结果也存在着一个细微的失真:线型在t-SNE图中呈现出略向外弯曲。 主要原因就是,t-SNE算法趋向于扩展更密集的数据区域。 由于聚簇点阵中间部分的空白空间比两端少,所以算法把它们扩大了。
6. 对于拓扑,可能需要多个图像
有时你可以从t-SNE算法结果图像中读取拓扑信息,但是这通常需要通过多个困惑度下的视图来获得。 最简单的拓扑性质之一是拓扑包含。 下图显示了两组在50维空间中的75个数据点的聚簇。 两组聚簇都是以原点为中心的对称高斯分布,但是其中一个的密度比另一个高50倍。 较小的聚簇实际上包含在大的聚簇里面。
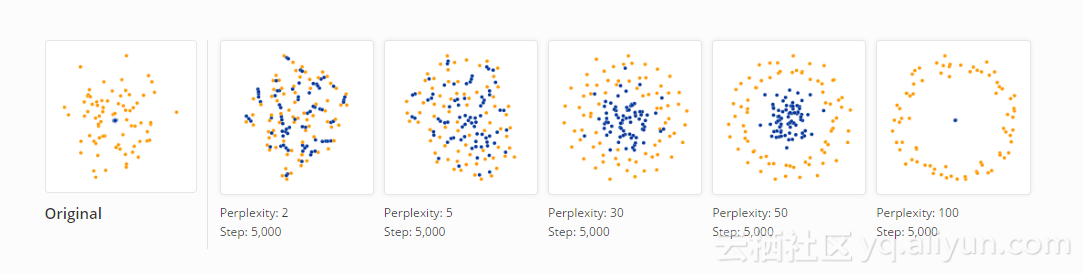
困惑度30下的视图正确地显示出了基本拓扑,但是t-SNE算法再一次夸大了较小的聚簇点阵的大小。 在困惑度50时,有另一个新的现象出现:外聚簇点阵变成一个圈。因为算法试图描述这样一个事实,即所有的外聚簇点阵与内聚簇大约保持相同的距离。 如果你单独看这个图像,很容易把这些外围的点误认为是一个一维结构。
那更复杂的拓扑类型呢? 这可能是数学家需要研究的课题,而非数据分析师。但那些有趣的低维结构也往往成为探索的领域。
让我们来考虑一组在三维中跟踪链接或节点的点。通过查看多个困惑度下的试图给出了最完整的结论。 低困惑度时,算法给出两个完全独立的环; 而高困惑度时则显示出两个连接的环。

三叶结是一个有趣的例子,说明了多个运行如何影响t-SNE算法的结果。 下面是五个在困惑度2下的视图。
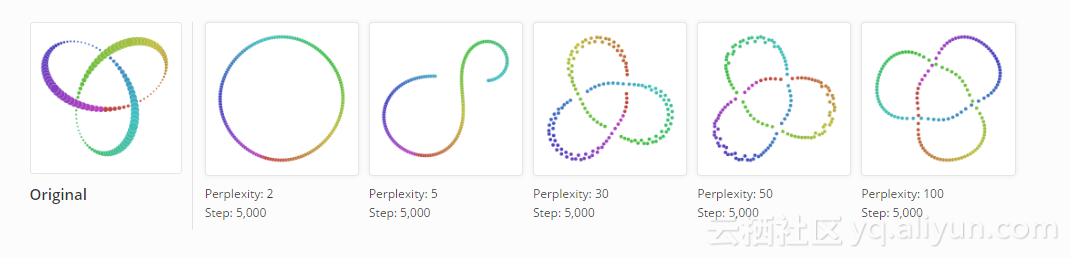
该算法在圆上建立两次,这至少保留了原本的拓扑。 但在三个运行结果中,它得到三个不同的结果并引入人工中断。 使用点颜色作为指南,我们可以看到第一次和第三次运行之间的差异。
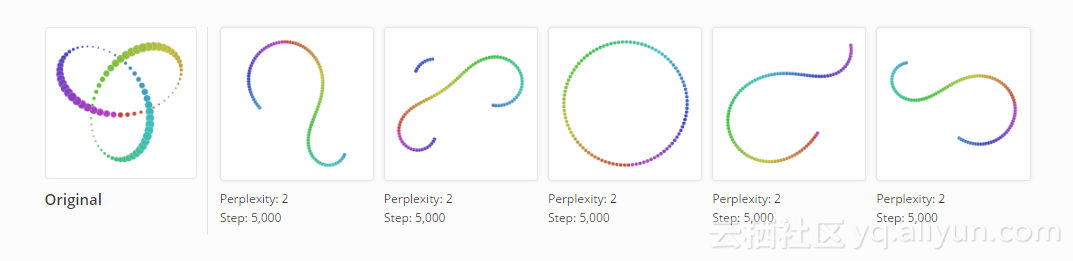
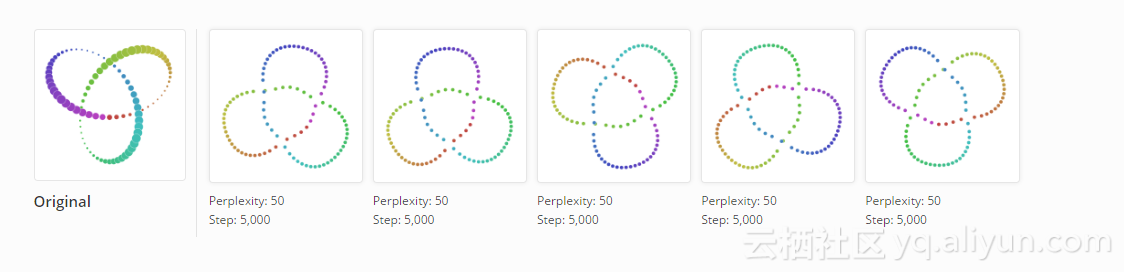
然而,在困惑度50下的五次运行给出(直到对称性)了在视觉上相同的结果。 显然,一些问题比其他问题更容易优化。
结语
t-SNE变得如此受欢迎的重要原因是它的灵活性,并且经常得出其他降维算法不能得到的结构。 不幸的是,这种灵活性使得理解t-SNE结果变得非常困难。 在用户看不见的情况下,算法进行着各种调整,以使结果可视化。 不要让这些困难让你对t-SNE望而却步。更值得一提的是,通过研究t-SNE算法在简单情况下的运行过程,可以为那些复杂的情况制定基准。
