1
根据监控对象的不同,监控系统可以分为系统监控、应用监控和业务监控。“实时交易监控系统”属于业务监控,主要用于监控客户的购买行为及订单情况,一般用于支持公司的日常运营决策和重大营销活动,如“双11”、“双12”及“双旦”等,对数据的实时性要求较高。
“实时交易监控系统”对数据的一般处理流程:实时捕获数据库中交易数据的变更、实时计算订单各维度的指标、再实时推送指标到浏览器大屏。通过采集、计算、展示三个阶段的实时性来保证整个监控系统的时效性,延迟可控制在秒级或亚秒级以内
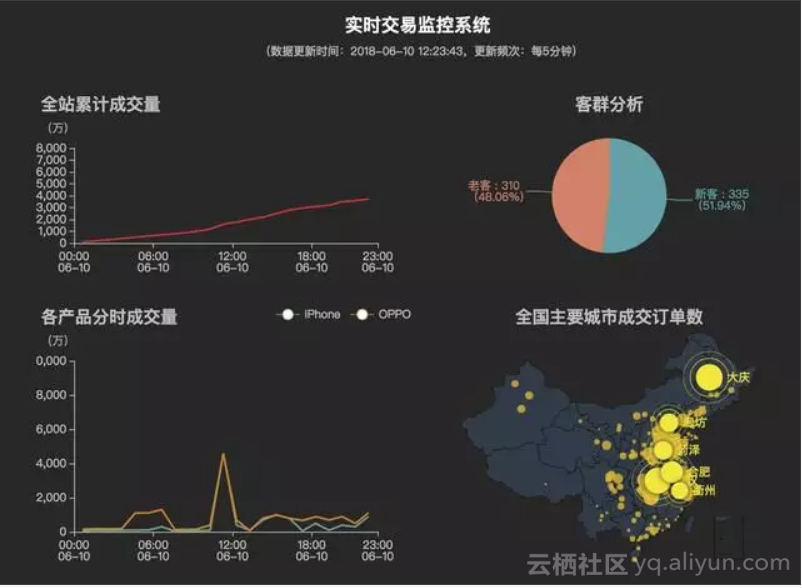
这个是效果图,企业内上线的项目监控的需求会有很多,这个是简易版的,做了很多的需求删减。
通过“实时交易监控系统”的开发,来讲解典型的大数据实时解决方案的过程及原理,包括数据采集(kafka+canal)、数据计算(spark streaming/storm/kafka stream)、数据存储(hbase)、数据应用及可视化(echarts)等。
监控系统概述
包含要素:
全方位的监控指标
异常告警通知:告警触发阈值、告警监控对象、告警通知接收人以及发送渠道
可视化图表分析
监控规则配置化
应用场景:
业务质量实时关注
业务异常提前发现
业务精细化运营/运维
实施流程:
指标采集->指标加工->指标存储->指标可视化
项目技术架构流程图
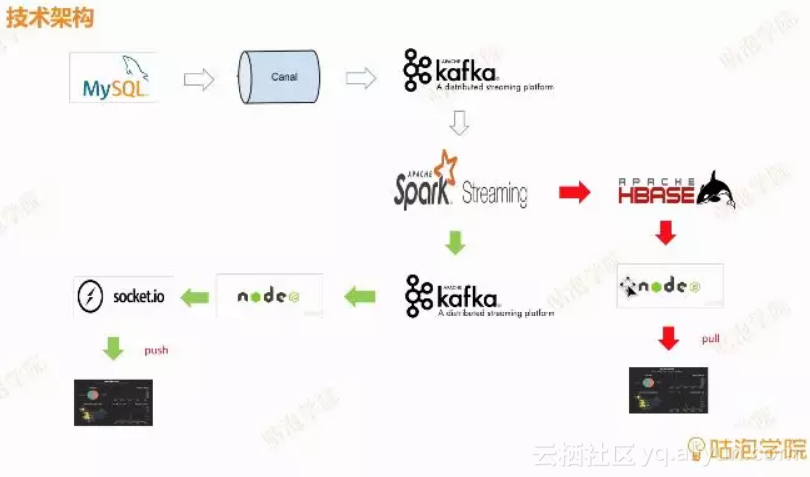
看图方式为从上往下、从左往右来看,以箭头的指向,箭头指向的是原数据的流向到最终展示的路径。
MySql为例,mysql的交易数据binlog,里面的订单数据、用户的注册数据或者用户的购买信息。原数据怎么实时的往后面流转呢?这里就用到了Alibaba Canal开源组件,实时监控数据变更与捕获在推送到kafka。
Kafka是一个大型的消息队列缓冲区,是个集群模式的消息缓冲区,可以存大量的缓冲数据,如果我们的交易量较大的时候会用到kafka做一个消息缓冲作用,形成一些原始的交易数据。
缓冲完之后,会再进入到实时计算框架spark streaming中,spark streaming会消费kafka里面的这些订单数据,从spark streaming这一段的分支,分别是做监控的思路
绿色箭头方案:
spark streaming把数据处理成我们想要的metric,做一些聚合与指标的处理,metric又会回流到kafka当中。
在处理完指标之后,会启一个nodejs的一个服务,这个服务会再次去消费metric的这个kafka,然后通过socket.io这样的一个web socket双向交互的工具在把数据推送到浏览器,然后就会看到整个数据是从数据库抽取出来,一系列的传递在实时推送到浏览器的,实时的处理链路就清晰了,在看到实时的动态变化的大屏。只要mysql里面有交易发生,那整个数据流就会通过这样一个管道最后到达浏览器。
红色箭头方案:
spark streaming把基础数据加工完成之后,会放到HBASE里。根据hbase里有没有新增的指标,有新增指标在传输过去做变动展示,浏览器做不定时的刷新。
技术点梳理
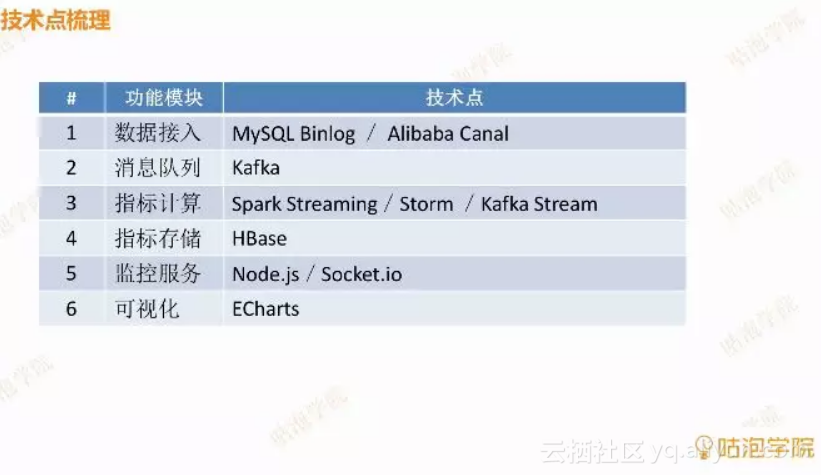
相信读者对于这个业务监控项目有了一定的了解,数据的处理方式与如何在浏览器上展示并且有两种方式去做到数据实时更新。
了解了大数据的入门所必须的基础知识点,不用多说,最后的实战训练是最重要的,进行一些实际项目的操作练手,可以帮助我们更好的理解所学的内容,同时对于相关知识也能加强记忆,在今后的运用中,也可以更快的上手,对于相关知识该怎么用也有了经验。
原文发布时间为:2018-08-26

