今儿调模型大佬又给支了一招,叫Batch Normalization(下面简称BN),虽然还没有深刻理解这玩意是什么,但是是真的挺有效的,哈哈。因此本文只是总结一下BN的具体操作流程以及如何用tensorflow来实现BN,对于BN更深层次的理解,为什么要BN,BN是否真的有效大家可以参考知乎上的回答:https://www.zhihu.com/question/38102762
1、BN的流程
传统的神经网络,只是在将样本x进入到输入层之前对x进行0-1标准化处理(减均值,除标准差),以降低样本间的差异性,如下图所示:
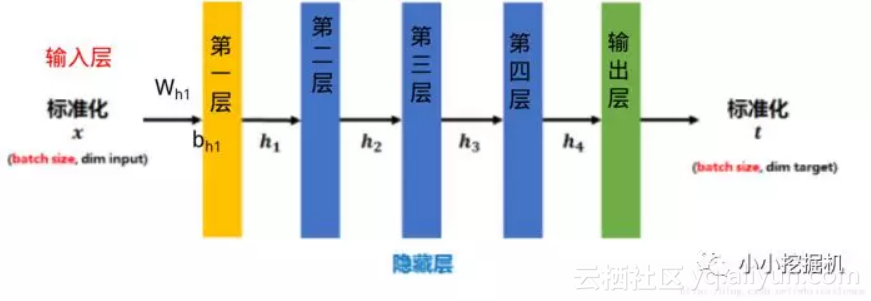
BN是在此基础上,不仅仅只对输入层的输入数据x进行标准化,还对每个隐藏层的输入进行标准化,如下图所示:
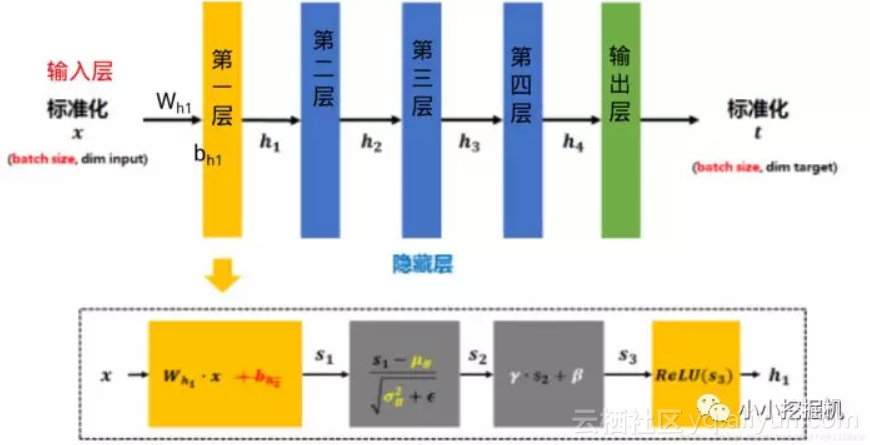
可以看到,由标准化的x得到第二层的输入h1的时候,经历了如下的步骤:
1、第一层的权重项w 和 输入x想成,得到s1
2、对s1进行0-1均值方差标准化,得到s2
3、设置两个参数γ 和 β ,计算γ * s1 + β 得到s3。注意,这里的γ 和 β是网络要学习的变量。
4、将s3经过激活函数激活之后得到h1
哎,BN的流程原来是这样的。。早上的时候看的太快,以为就是对每一层的输入做一个0-1标准化,再加一个γ 和 β呢。唉,得好好反思反思,明天罚自己减一个鸡腿。废话不多说,我们来看看实现吧。
2、tensorflow实现BN
tensorflow实现BN是很简单的,只需要两个函数就可以。
tf.nn.moments
该函数的样例如下:
batch_mean, batch_var = tf.nn.moments(data, [0])
可以看到,我们输入的第一个参数是我们的data,一定要记住,这个data是w*x之后的。第二个参数是我们要在哪一维做标准化,如果是二维数据,通常每一列代表的是一个特征,因此我们一般选择axis=[0],如果你想对所有的数据做一个标准化,那么axis=[0,1]。
tf.nn.batch_normalization
该函数的样例如下:
我们需要输入我们的data,即w*x,然后还有刚刚用moments函数得到的均值和方差,scala和offset即前文提到的的γ 和 β ,这是两个Variable。
完整实例
最后来看一个完整实例吧:
参考资料:https://blog.csdn.net/whitesilence/article/details/75667002
原文发布时间为:2018-08-22
本文作者:文文
本文来自云栖社区合作伙伴“Python爱好者社区”,了解相关信息可以关注“Python爱好者社区”。


