热门
让你的文档从静态展示到一键部署可操作验证
一键生成视频!用 PAI-EAS 部署 AI 视频生成模型 SVD 工作流
XiaodiSec day009 Learn Note 小迪渗透学习笔记
vue下拉列表
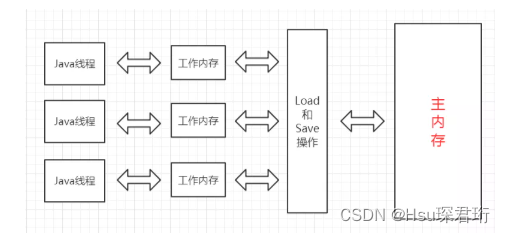
【JavaEE多线程】从单例模式到线程池的深入探索
XiaodiSec day008 Learn Note 小迪渗透学习笔记
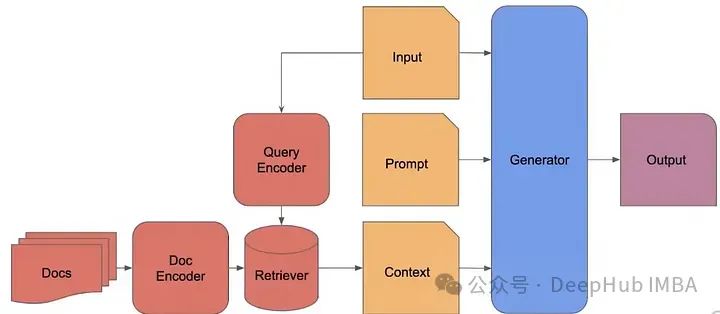
RAG 2.0架构详解:构建端到端检索增强生成系统
XiaodiSec day007 Learn Note 小迪渗透学习笔记
Oracle的PL/SQL隐式游标:数据的“自动导游”与“轻松之旅”
Oracle的PL/SQL显式游标:数据的“私人导游”与“定制之旅”
Oracle的PL/SQL游标:数据的“探秘之旅”与“寻宝图”
Python推导式:简洁高效的数据结构构建与应用
Oracle的PL/SQL循环语句:数据的“旋转木马”与“无限之旅”
【JavaEE多线程】线程安全、锁机制及线程间通信
JavaScript Dom方法
Oracle的PL/SQL条件控制:数据的“红绿灯”与“分岔路”
Oracle的PL/SQL表达式:数据的魔法公式
Oracle的PL/SQL定义变量和常量:数据的稳定与灵动
Oracle的PL/SQL特殊数据类型:数据的魔法师
Oracle PL/SQL基本数据类型:数据世界的多彩画卷
Oracle常用系统函数之聚集函数:数据的统计大师
Oracle常用系统函数之日期和时间类函数:时空穿梭者的魔法棒
Oracle常用系统函数之数字类函数:数字的魔术师
Oracle常用系统函数之字符类函数:文字的魔法师
Oracle示例模式Scott:数据库世界的“小导游”
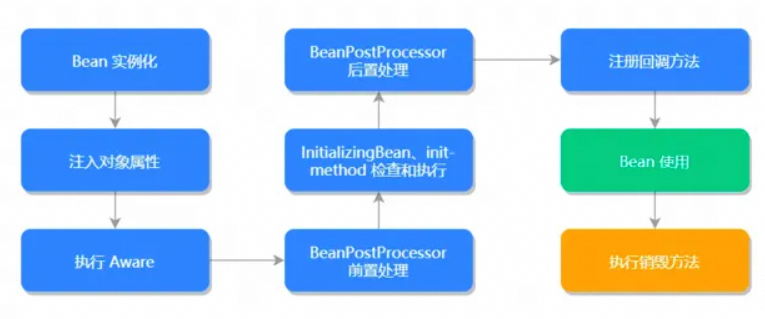
这些年背过的面试题——Spring篇
【JavaEE多线程】理解和管理线程生命周期
Oracle的模式与模式对象:数据库的“城市规划师”
Oracle SQL*Plus的TTITLE和BTITLE命令:为你的数据报告加上精美的“画框”
PHP面向对象编程精要:接口、抽象类和继承
Oracle SQL*Plus的COLUMN命令:数据展示的“化妆师”
AI助理小课堂02期
Oracle SQL*Plus的SPOOL命令:数据库世界的“录像机”
Oracle SQL*Plus的DESCRIBE命令:数据结构的“侦探”
Oracle SQL*Plus的HELP命令:你的数据库“百事通”
代码随想录训练营 | 一刷总结
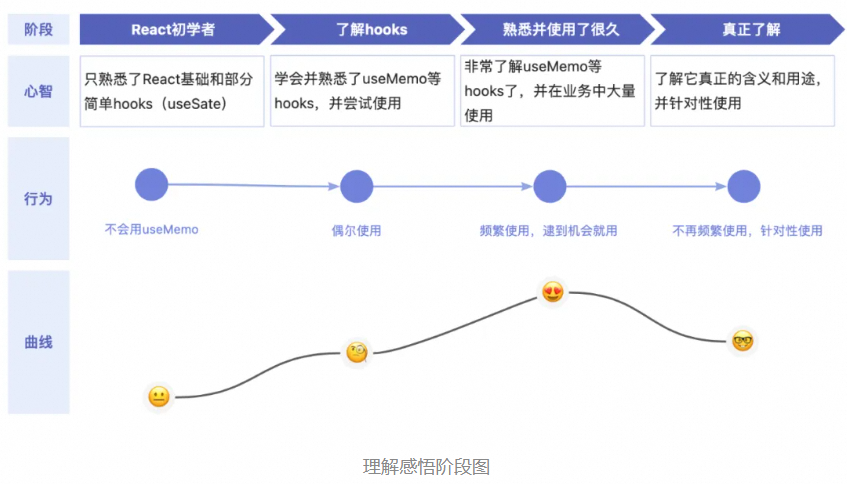
请删掉99%的useMemo
Oracle SQL*Plus的SET命令:你的数据库会话“调色板”
Oracle常用数据字典:数据王国的“藏宝图”
Oracle数据字典:数据王国的“百科全书”
Oracle程序全局区:数据王国的“魔术舞台”
Oracle系统全局区:数据王国的“大舞台”
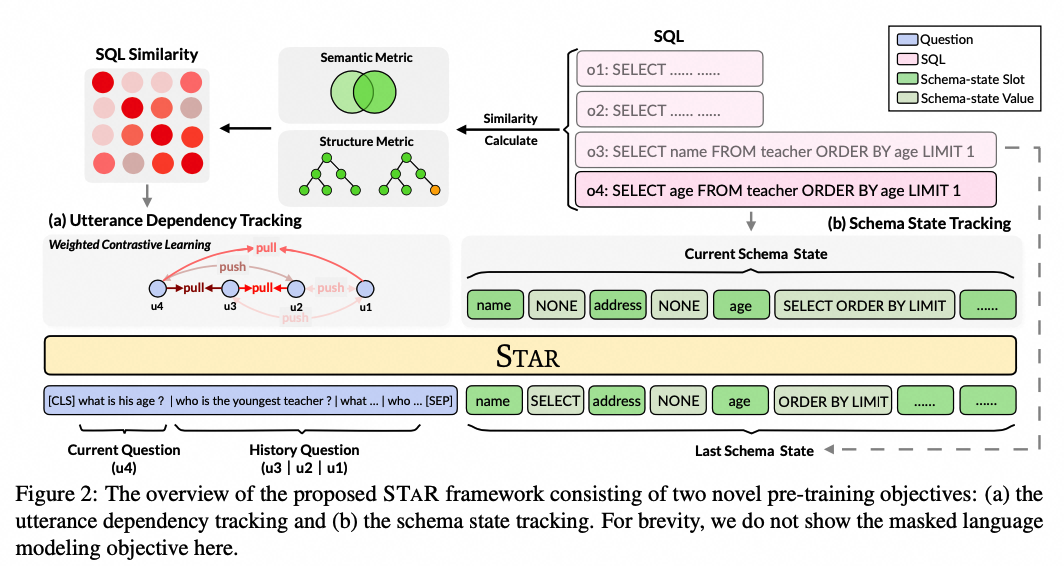
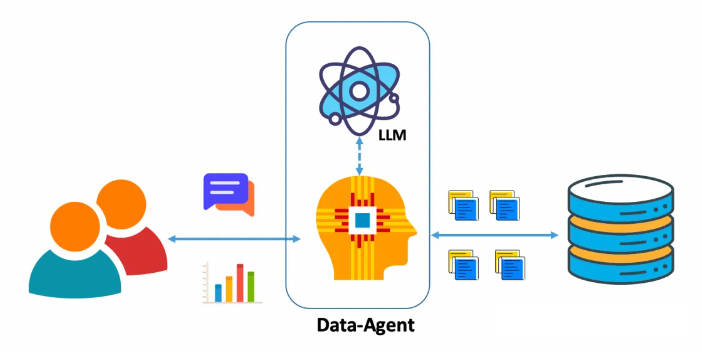
NL2SQL实践系列(2):2024最新模型实战效果(Chat2DB-GLM、书生·浦语2、InternLM2-SQL等)以及工业级案例教学
Oracle的三重奏:密码文件、警告文件与跟踪文件
Oracle服务器参数文件:数据王国的“调控大师”
Oracle日志文件:数据王国的“记事本”
Oracle控制文件:数据王国的导航仪
代码随想录算法训练营第六十天 | LeetCode 84. 柱状图中最大的矩形
NL2SQL技术方案系列(1):NL2API、NL2SQL技术路径选择;LLM选型与Prompt工程技巧,揭秘项目落地优化之道
Oracle数据文件:数据王国的秘密藏宝图