1. 基础知识
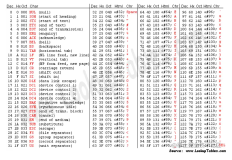
字符集(Charset):是一个系统支持的所有抽象字符的集合。字符是各种文字和符号的总称,包括各国家文字、标点符号、图形符号、数字等。
字符编码(Character Encoding):是一套法则,使用该法则能够对自然语言的字符的一个集合(如字母表或音节表),与其他东西的一个集合(如号码或电脉冲)进行配对
2.常用字符集
上个世纪60年代,美国制定了一套字符编码,对英语字符与二进制位之间的关系,做了统一规定。这被称为ASCII码,一直沿用至今。
ASCII码一共规定了128个字符的编码,比如空格“SPACE”是32(二进制00100000),大写的字母A是65(二进制01000001)。这128个符号(包括32个不能打印出来的控制符号),只占用了一个字节的后面7位,最前面的1位统一规定为0
在计算机科学领域中,Unicode(统一码、万国码、单一码、标准万国码)是业界的一种标准,它可以使电脑得以体现世界上数十种文字的系统。Unicode 是基于通用字符集(Universal Character Set)的标准来发展,并且同时也以书本的形式[1]对外发表。Unicode 还不断在扩增, 每个新版本插入更多新的字符。直至目前为止的第六版,Unicode 就已经包含了超过十万个字符(在2005年,Unicode 的第十万个字符被采纳且认可成为标准之一)、一组可用以作为视觉参考的代码图表、一套编码方法与一组标准字符编码、一套包含了上标字、下标字等字符特性的枚举等。Unicode 组织(The Unicode Consortium)是由一个非营利性的机构所运作,并主导 Unicode 的后续发展。
UTF-32:
使用4字节的数字来表达每个字母、符号,或者表意文字(ideograph),每个数字代表唯一的至少在某种语言中使用的符号的编码方案,称为UTF-32。UTF-32又称UCS-4是一种将Unicode字符编码的协定,对每个字符都使用4字节。就空间而言,是非常没有效率的,不被使用。
UTF-16:
尽管有Unicode字符非常多,但是实际上大多数人不会用到超过前65535个以外的字符。因此,就有了另外一种Unicode编码方式,叫做UTF-16(因为16位 = 2字节)。UTF-16将0–65535范围内的字符编码成2个字节.
对于UTF-16编码,不同计算机以不同顺序保存字节。这意味着字符U+4E2D在UTF-16编码方式下可能被保存为4E 2D或者2D 4E,这取决于该系统使用的是大尾端(big-endian)还是小尾端(little-endian)
UTF-8:
UTF-8 is a variable-width encoding that can represent every character in the Unicode character set. It was designed for backward compatibility with ASCII and to avoid the complications of endianess and byte order marks in UTF-16 and UTF-32.
互联网的普及,强烈要求出现一种统一的编码方式。UTF-8就是在互联网上使用最广的一种unicode的实现方式。其他实现方式还包括UTF-16和UTF-32,不过在互联网上基本不用。重复一遍,这里的关系是,UTF-8是Unicode的实现方式之一。
UTF-8最大的一个特点,就是它是一种变长的编码方式。它可以使用1~4个字节表示一个符号,根据不同的符号而变化字节长度。
UTF-8的编码规则很简单,只有二条:
1)对于单字节的符号,字节的第一位设为0,后面7位为这个符号的unicode码。因此对于英语字母,UTF-8编码和ASCII码是相同的。
2)对于n字节的符号(n>1),第一个字节的前n位都设为1,第n+1位设为0,后面字节的前两位一律设为10。剩下的没有提及的二进制位,全部为这个符号的unicode码。
下表总结了编码规则,字母x表示可用编码的位。
Unicode符号范围 | UTF-8编码方式
(十六进制) | (二进制)
--------------------+---------------------------------------------
0000 0000-0000 007F | 0xxxxxxx
0000 0080-0000 07FF | 110xxxxx 10xxxxxx
0000 0800-0000 FFFF | 1110xxxx 10xxxxxx 10xxxxxx
0001 0000-0010 FFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
下面,还是以汉字“严”为例,演示如何实现UTF-8编码。
已知“严”的unicode是4E25(100111000100101),根据上表,可以发现4E25处在第三行的范围内(0000 0800-0000 FFFF),因此“严”的UTF-8编码需要三个字节,即格式是“1110xxxx 10xxxxxx 10xxxxxx”。然后,从“严”的最后一个二进制位开始,依次从后向前填入格式中的x,多出的位补0。这样就得到了,“严”的UTF-8编码是“11100100 10111000 10100101”,转换成十六进制就是E4B8A5。
3. Java中字符编码。
3.1 Char to Byte & Byte to Char
public static void charTest() throws Exception{
//char: The char data type is a single 16-bit Unicode character. It has a minimum value of '\u0000' (or 0) and a maximum value of '\uffff' (or 65,535 inclusive).
char c = '\u4E25';
System.out.println("Unicode to char : "+c);
byte[] cb = new byte[2];
cb[0] = (byte) ((c&0xFF00)>>8); //取高8位
cb[1] = (byte) (c&0x00FF); // 取低8位
System.out.println("Byte[0] is 0x4E?: " + (cb[0] == 0x4E)+" --- Byte[1] is 0x25?: "+ (cb[1]==0x25));
System.out.println(new String(cb,"Unicode"));
System.out.println(new String(cb,"utf8"));//乱码,因为编码是unicode,解码是utf8
byte[] ba = new byte[3];//E4B8A5 是‘严’的 UTF8编码,三个byte
ba[0]=(byte)0xE4;
ba[1]=(byte)0xB8;
ba[2]=(byte)0xA5;
System.out.println("UTF8 encoding 3 bytes to chinese character: "+new String(ba,"utf8"));
c = 'a';
System.out.println("ASCII code of print char : " + (byte)c);
c = '\n';
System.out.println("ASCII code of ctrl char : " + (byte)c);
}
3.2 Variable-width encoding UTF8
//UTF8 是变长的编码
public static void UTF8Test() throws Exception{
String s = "人们";
System.out.print("Encoded by GBK : ");
displayByteArr(s.getBytes("GBK"));
System.out.print("Encoded by UTF8 : ");//一个汉字 占3个byte
displayByteArr(s.getBytes("UTF8"));
s = "ab";
System.out.print("Encoded by UTF8 : ");//一个英文字母 占1个byte
displayByteArr(s.getBytes("UTF8"));
System.out.print("Encoded by ASCII : ");//UTF8 对ASCII兼容,英文字母编码相同
displayByteArr(stringToBytesASCII(s));
System.out.print("Encoded by UTF32 : ");//UTF32对任何字符都用4字节,空间浪费严重
displayByteArr(s.getBytes("UTF32"));
}
public static void displayByteArr(byte[] ba){
for (byte b : ba){
System.out.print(b+" ");
}
System.out.println("");
}
public static byte[] stringToBytesASCII(String str) {
char[] buffer = str.toCharArray();
byte[] b = new byte[buffer.length];
for (int i = 0; i < b.length; i++) {
b[i] = (byte) buffer[i];
}
return b;
}
参考:
http://www.cnblogs.com/skynet/archive/2011/05/03/2035105.html#_4.Accept-Charset/Accept-Encoding/Ac
http://www.ruanyifeng.com/blog/2007/10/ascii_unicode_and_utf-8.html
http://en.wikipedia.org/wiki/UTF-8
http://www.javacodegeeks.com/2010/11/java-best-practices-char-to-byte-and.html