本文PPT来自阿里巴巴产品经理何源(花名:荆杭)10月16日在2016年杭州云栖大会上发表的《复杂网络架构下的网络故障智能处理——DC Brain之故障篇》。
网络是沟通世界的纽带,然而这个纽带却往往没有人们想象中的那么稳定。面对突如其来网络故障,网络工程师们经常会显得束手无策。与其他故障不同,网络故障的特殊性体现在1.体量大,经常涉及几万台网络设备和几百万端口2. 型号架构多,日志格式不统一,警告规则不统一 3.结构复杂,重复告警多 4. 自身依赖,监控系统本身运行在网络上。因此如何处理巨大的数据、不被海量的警告淹没、理清复杂的依赖关系和逻辑关系,是工程师们普遍关心的问题。
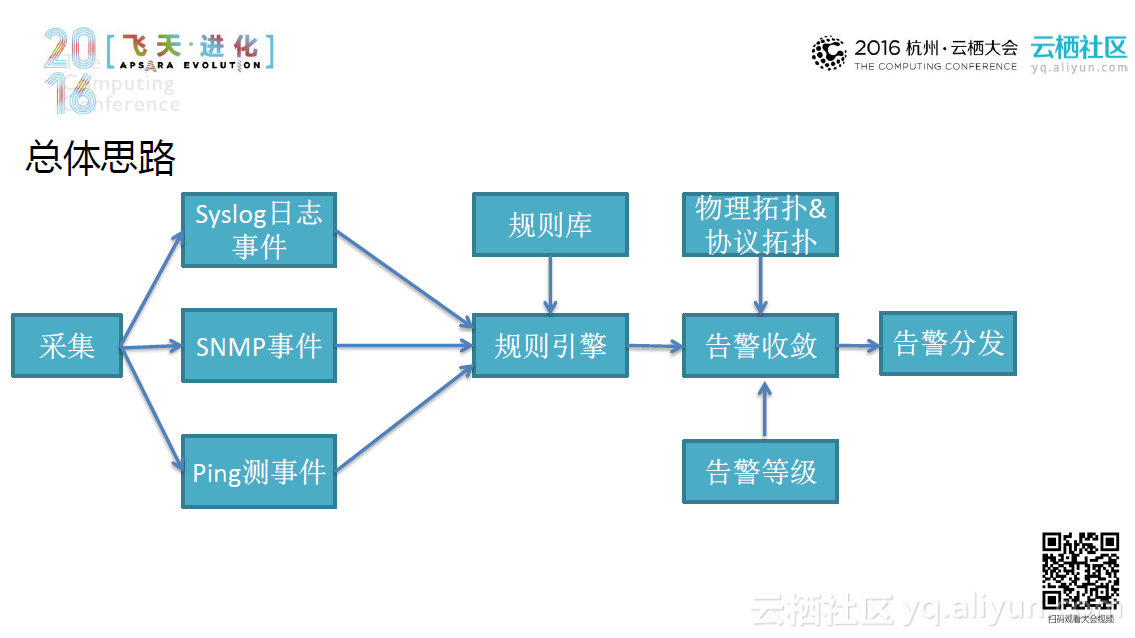
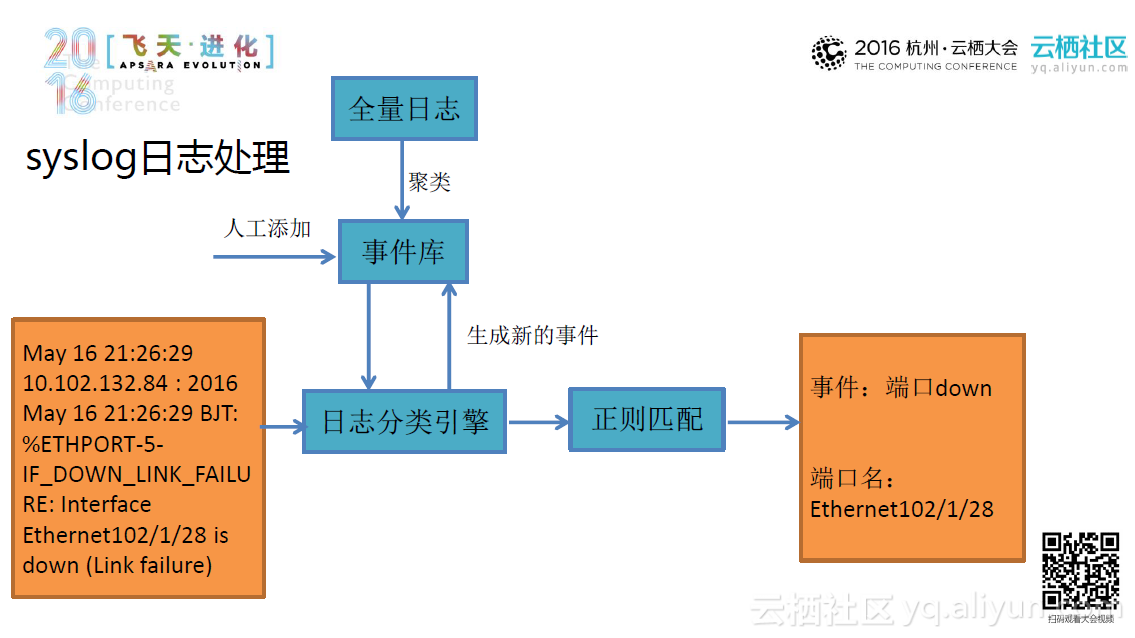
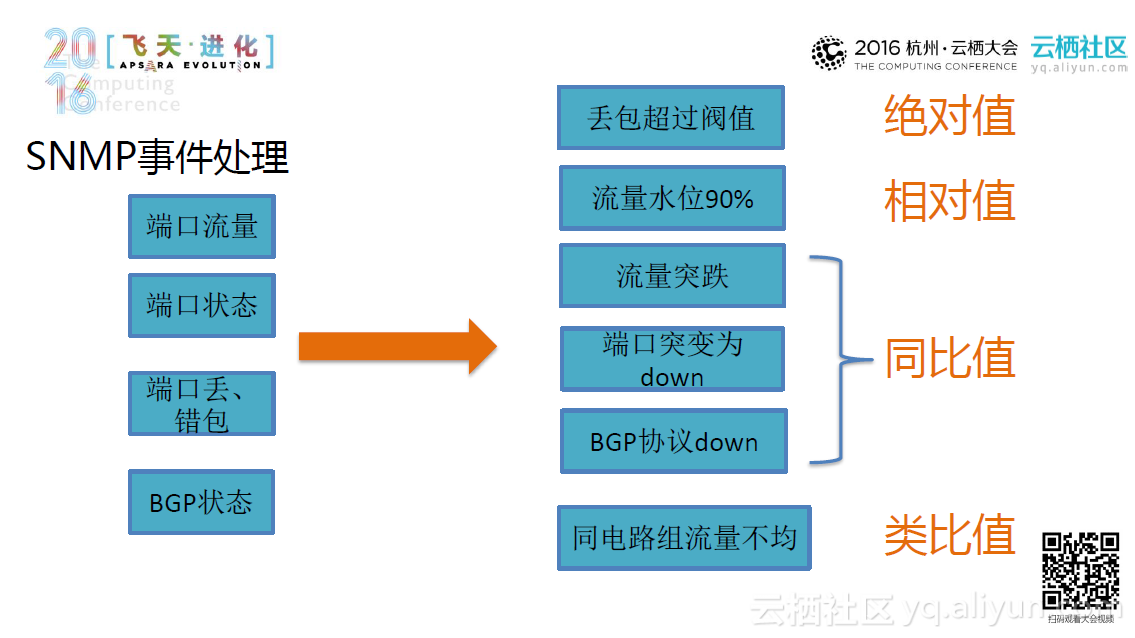
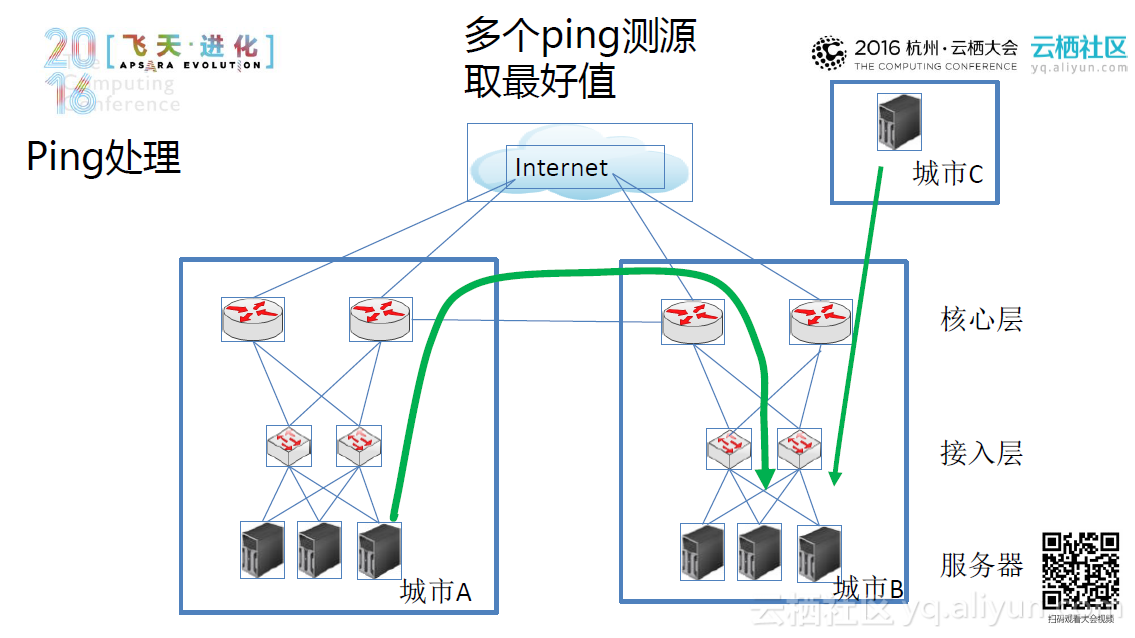
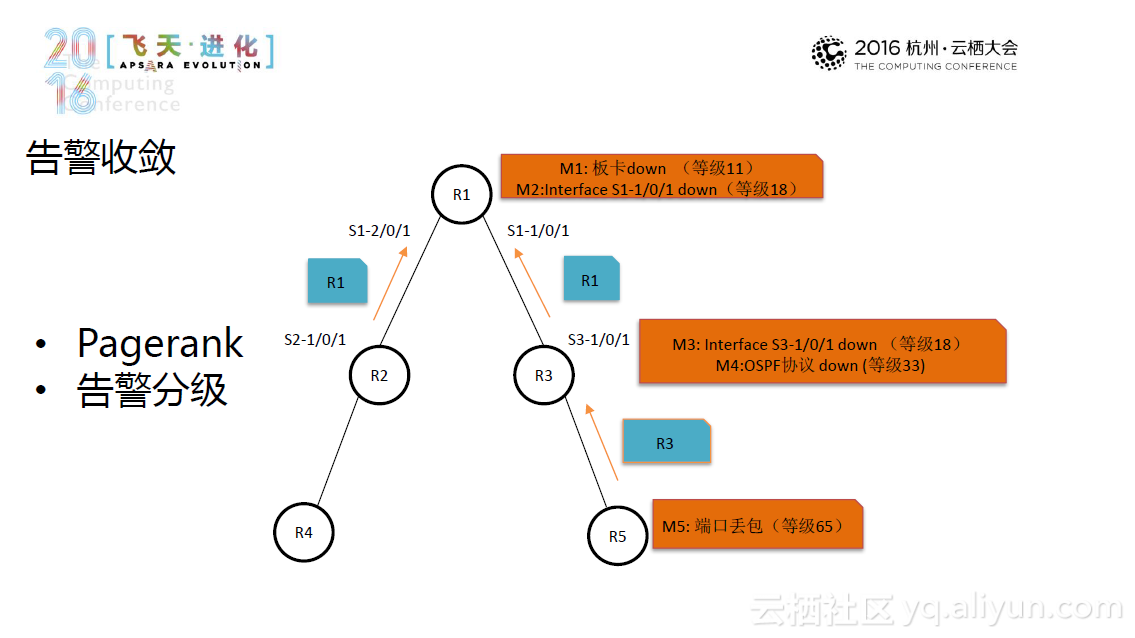
所以这里我们采用多元化、交叉覆盖的检测手段,根据可扩展、可自定义的规则并结合基于pagerank算法的告警收敛,利用告警监控系统冗余部署来检测网络系统异常。大体的思路是这样的:首先系统采集Syslog日志事件,并利用包含大量事件库的日志分类引擎来处理Syslog日志,最终再通过正则匹配使原本杂乱无章的系统日志变得简单明了。类似地,系统也会采集SNMP和Ping测事件,并且用包含对应规则库的规则引擎来分析处理这些事件。再经过引擎处理后,系统将根据告警等级和物理拓扑及协议拓扑将告警分发出去。
总结:大型的系统数据量每分钟可达千万级,因而基于spark streaming流式处理,spark graphX图算法这些单一的监控手段都会有失效的可能,所以要有多重手段。大数据不可怕,基础设施怕的是没有数据。所以既懂基础设施,又懂数据的人才很稀缺,将来会在市场上更具竞争力。