本文PPT来自资深专家封仲淹于10月16日在2016年杭州云栖大会上发表的《Large-Scale Stream Processing inside Alibaba》。
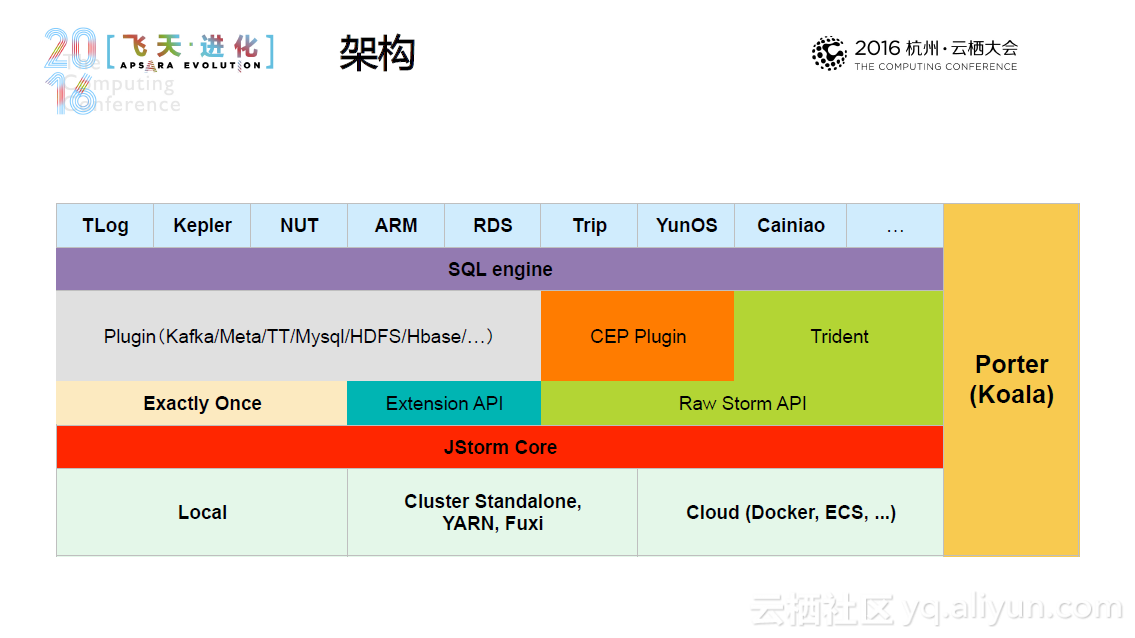
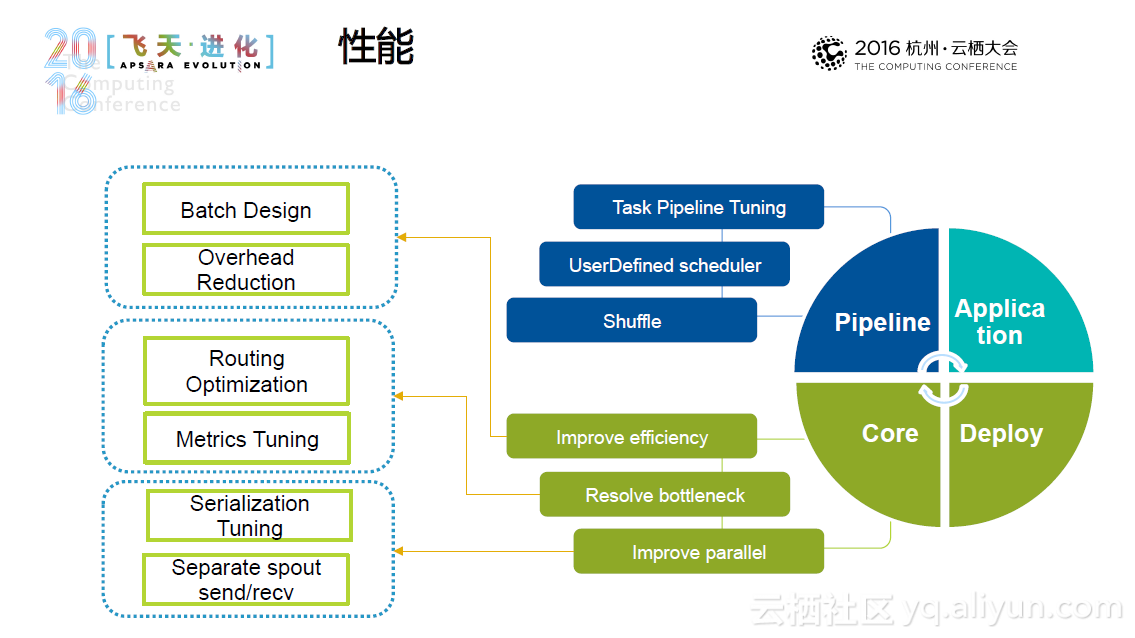
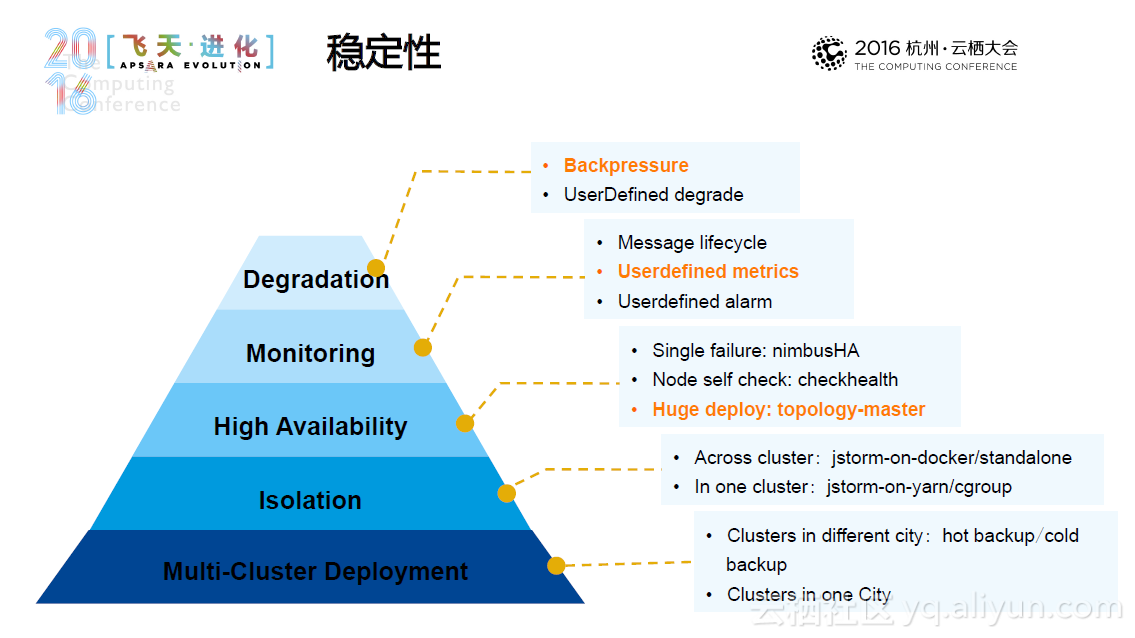
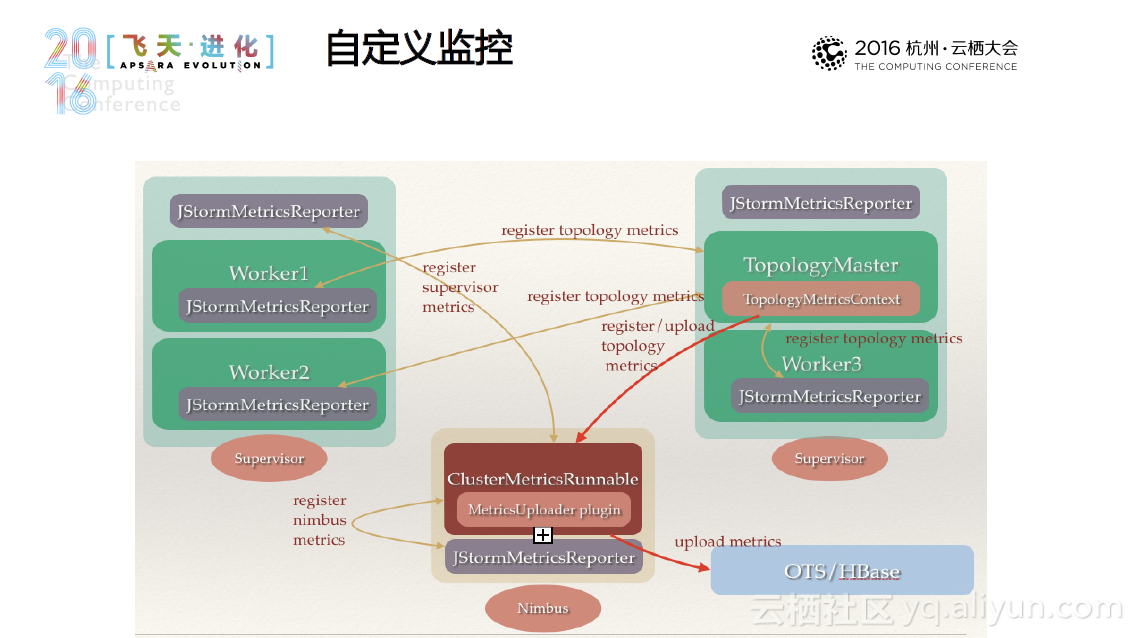
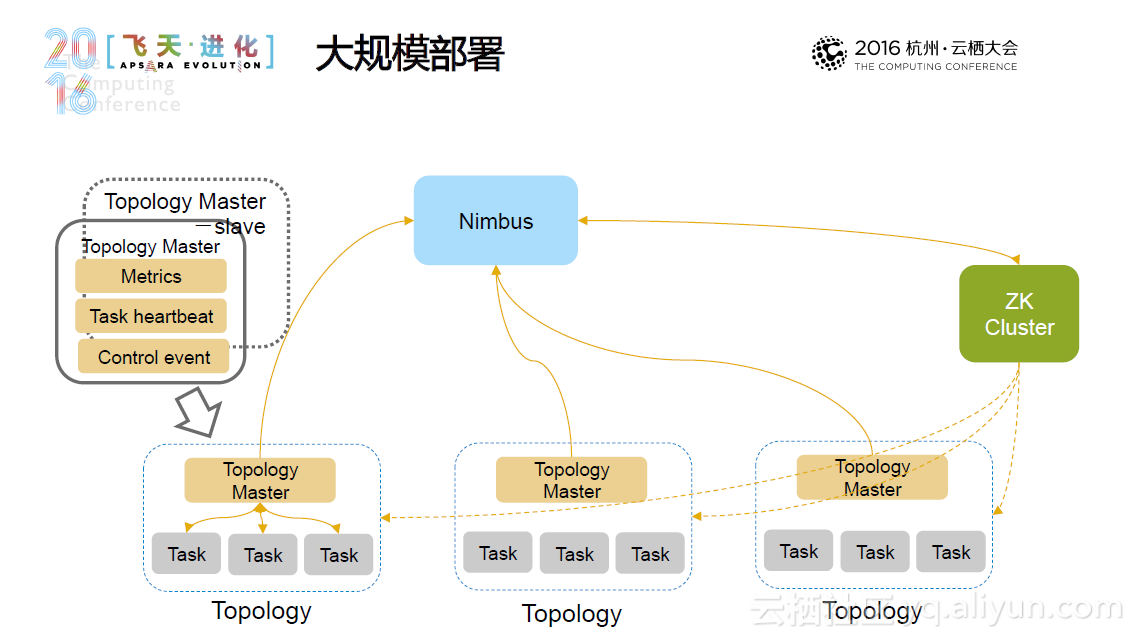
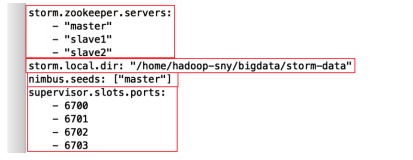
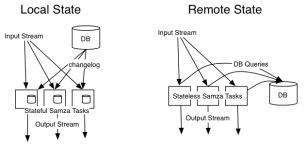
JStorm 是阿里巴巴基于storm采用Java重写的一套开源的分布式实时流计算框架,其诞生于2013年,经历多次迭代,至今已经发布25了版本。总体而言,JStorm具有高性能、高稳定性,适于大规模部署这些特点,其他的用户方的特色功能包括用户自定义的调度器和资源用法、先进的日志机制、更细粒度的Metrics、动态规模调整和快速的应用升级等等。
目前,JStorm运行在超过4000台机器上,它不仅能单独部署,也实现了JStorm-on-yarn和JStorm-on-docker,使JStorm能够被部署在框架上。这些集群共形成了超过1500个应用和2000余个拓扑结构,每天产生的数据超过惊人的2PB。在实际运用中,JStorm有许多应用场景,如欺诈检测、广告审核、数据统计、系统监控、数据传输、实时推荐和应用调度等,除了供阿里自身使用,JStorm还被众安保险、科大迅飞、网宿科技等超过50家公司使用。未来,JStorm将支持Apache Beam,并努力成为一个强大的高级语言框架,使其更容易学习和调试,提供更大的吞吐量。
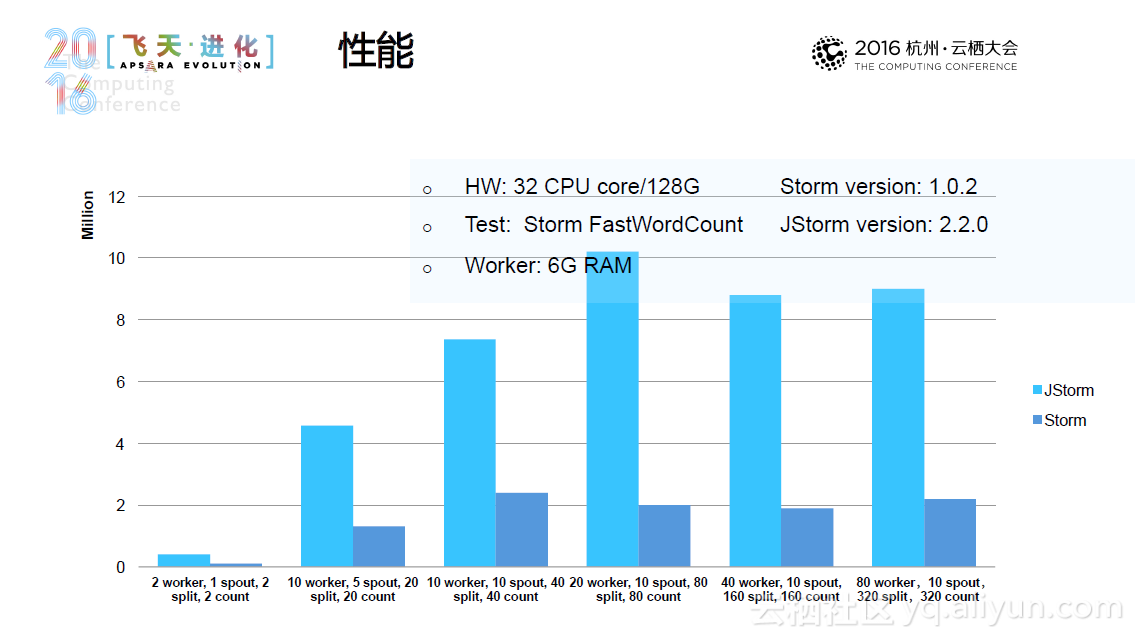
最后关于JStorm和Storm的区别,阿里的JStorm不仅仅是Storm的简单包装,更重要的是JStorm意味着一个流处理生态系统,一个企业级的Java Storm,并且比Storm更快、更稳定、特性也更多。