SAF 中缓存服务的实现
概述
本文是《Developing Application Frameworks in .NET》的读书笔记。SAF 是书中的一个范例框架,意为 Simple Application Framework(简单应用程序框架),通过这篇文章,我主要想向大家说明 SAF 中缓存服务的实现方式。由于添加了大量注释,所以代码部分的讲述相对比较少。
设计思想
我们经常需要在应用程序中缓存一些常用数据供全局使用以提升性能。如果需要缓存的对象类型和数目是固定的,我们可能会直接将其声明为static;如果我们需要缓存的对象类型和数目是不定的,我们可能会借助一个static Hashtable来实现。但是Hashtable有个缺陷:它没有层次结构,它总是以键/值的形式来存储数据,一个Key对应一个Value,如果我们想获取相关联的一组数据就会比较困难了。
NOTE:如果你从事Asp.Net的开发,提起缓存你可能首先会想到Output Cache、数据源缓存或者是基于System.Web.Caching.Cache的对象缓存。实际上缓存的目的就是把对象(数据)存储在内存中,不用每次需要对象服务的时候都重新创建对象(相对耗时)。将对象声明为static,那么对象将在其所属的类被载入AppDomain时初始化,这样对象的生命周期与AppDomain同样长,从而起到缓存的目的。
感兴趣的朋友可以做个测试:在站点下新建一个Default.aspx文件,在后置代码中添加如下代码:
public class Test {
public static DateTime a = DateTime.Now;
public DateTime b = DateTime.Now;
}
protected void Page_Load(object sender, EventArgs e) {
Test t = new Test();
Label1.Text = Test.a.ToString() + "<br />"; //Label1为页面上的一个Label控件
Label1.Text += t.b.ToString();
}
结果是只要站点不重启(代码也不修改),那么a的值是恒定不变的,即使将页面关了重新打开也一样,可见a只在Test类加载到AppDomain中进行了一次初始化。而b在每次刷新时都会改变,因为每次请求页面都会在创建Test类型实例时重新对a进行初始化。
NOTE:声明为静态(static)的一个特例是声明为const,这是因为const天生就是static的。但它的局限性是对象的类型必须为诸如int或者string的简单类型。除此以外,声明为const的对象将不再是变量,而是一个常量。例如const a = "abc"; 相当于给string类型的字符串"abc"起了个别名叫a。因此const必须在声明时就赋值。
XML文档结构是树形的,具有标准的层次结构。XPath用于从Xml文档中选择一个或多个结点。比如 "/BookStore/Book",选择Book结点下的所有子结点。
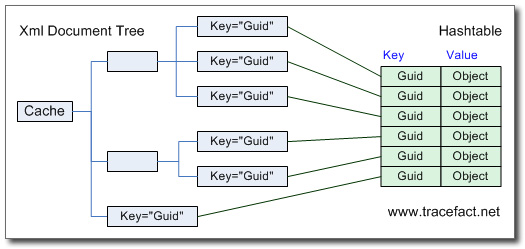
SAF 中的缓存服务通过一个在内存中动态构造的Xml文档树作为桥梁,将 静态(static)缓存 和 XPath 这两个技术结合了起来,支持使用XPath的语法来获取Hashtable中对象。其中静态缓存进行实际的数据缓存,XPath用于获取数据对象。从程序员的角度来看,即是Hashtable的Key支持了XPath的语法,可以将原本“平板式”的Hashtable想象成为一个“树形结构”,它的结点包含了缓存的数据,我们通过标准的XPath到达结点(当然这只是一个假象)并获取数据。通过这种方式就可以使用XPath来一次获取Hashtable中的多个相关数据对象。
而实际上是怎么实现这一过程的呢?我们一步步来看:
- 首先在内存中动态构建一个 Xml文档,它只包含一个根结点,可以任意命名,这里将它命名为了Cache。
- 提供一个Xpath路径:获取对象(数据)前首先要存储对象,存对象自然要先提供一个路径(这里称为“路径”,是因为它是一个XPath,实际上也就相当于Hashtable中的键Key)。
- 根据上一步提供的路径,以Cache为根结点,逐层深入地创建XmlNode结点。
- 生成一个GUID,在叶结点上添加一个Key属性,为这个Key属性赋值为GUID。
- 在Hashtable中存储对象,其中Hashtable的Key即为上一步生成的GUID,而Value为要存储的对象。
使用这种方式,Hashtable的实际的Key,即动态生成的GUID对程序员来说是透明的,程序员在存储/获取对象时,只需要提供XPath表达式就可以。下面这幅图说明了它们之间的关系:
这里还需要再说明三点:
- 我们使用Hashtable存储对象,可以直接将Hashtable声明为static的,也可以将Hashtable声明为instance的,但是将Hashtable所属的对象声明为static的。这里应用了Singleton模式,先将对Hashtable的操作封装成一个类,然后在这个类上应用Singleton模式,确保了这个类只有一个(这个类所维护的Hashtable实例自然也只有一个了)。很明显,这个类包含了主要的逻辑,我们将之命名为Cache。
- 使用Hashtable的好处是可以存储任何类型的对象,缺点是丧失了类型安全。有时候我们可能会想使用一个泛型集合类来取代Hashtable,比如Dictionary<T key, T value>。所以这里又引入了Strategy模式,创建了一个ICacheStrategy接口,这个接口包括三个方法,分别用于添加、获取、删除对象。
- 用Xpath获取结点时,可以是基于当前结点的相对路径;也可以是基于根结点的绝对路径。在本文的范例程序中,使用的是绝对路径,显然这样更加方便一些。
类型接口
我们先看一下类型的组织,然后再看实现。
ICacheStrategy用于定义如何添加、获取、删除欲进行缓存的对象。实际上,在接口的实体类中要明确使用何种类型来存储对象,是Dictionary还是Hashtable或者其他。
public interface ICacheStrategy {
void AddItem(string key, object obj);// 添加对象
object GetItem(string key); // 获取对象
void RemoveItem(string key); // 删除对象
}
接下来是Cache类,这个类包含了主要的逻辑,包括 动态构建的XML文档、将Xml文档映射到Hashtable 等。
public class Cache {
void AddItem(string xpath, object obj);
object GetItem(string xpath);
object[] GetList(string xpath);
void RemoveItem(string xpath);
}
仅从接口上看,这个类似乎和ICacheStrategy的没有太大分别,实际上,这个类保存了一个对于ICacheStrategy类型实例的引用,最后一步的实际工作,都委托给了ICacheStrategy去完成。而在此之前各个方法的工作主要是由 Xml结点到Hashtable的映射(这里说是Hashtable,是因为它是作者提供的一个默认实现,当然也可以是其他)。
类型实现
我们首先看DefaultCacheStrategy,它实现了ICacheStrategy接口,并使用Hashtable存储对象。
public class DefaultCacheStrategy : ICacheStrategy {
private Hashtable objectStore;
public DefaultCacheStrategy() {
objectStore = new Hashtable();
}
public void AddItem(string key, object obj) {
objectStore.Add(key, obj);
}
public object GetItem(string key) {
return objectStore[key];
}
public void RemoveItem(string key) {
objectStore.Remove(key);
}
}
接下来我们一步步地看Cache类的实现,下面是Cache类的字段以及构造函数(注意为私有)。
public class Cache {
private XmlElement rootMap; // 动态构建的 Xml文档 的根结点
private ICacheStrategy cacheStrategy; // 保存对ICacheStrategy的引用
public static readonly Cache Instance = new Cache(); // 实现Singleton模式
private XmlDocument doc = new XmlDocument(); // 构建 Xml文档
// 私有构造函数,用来实现Singleton模式
private Cache() {
// 这里应用了Strategy模式。
// 改进:可以将使用何种Strategy定义到app.config中,然后使用反射来动态创建类型
cacheStrategy = new DefaultCacheStrategy();
// 创建文档根结点,用于映射 实际的数据存储(例如Hashtable) 和 Xml文档
rootMap = doc.CreateElement("Cache");
// 添加根结点
doc.AppendChild(rootMap);
}
// 略...
}
Cache类还包含两个私有方法。PreparePath()用于对输入的Xpath进行格式化,使其以构造函数中创建的根节点("Cache")作为根结点(这样做是可以使你在添加/获取对象时免去写根结点的麻烦);CreateNode() 用于根据XPath逐层深入地创建Xml结点。
// 根据 XPath 创建一个结点
private XmlNode CreateNode(string xpath) {
string[] xpathArray = xpath.Split('/');
string nodePath = "";
// 父节点初始化
XmlNode parentNode = (XmlNode)rootMap;
// 逐层深入 XPath 各层级,如果结点不存在则创建
// 比如 /DvdStore/Dvd/NoOneLivesForever
for (int i = 1; i < xpathArray.Length; i++) {
XmlNode node = rootMap.SelectSingleNode(nodePath + "/" + xpathArray[i]);
if (node == null) {
XmlElement newElement = rootMap.OwnerDocument.CreateElement(xpathArray[i]); // 创建结点
parentNode.AppendChild(newElement);
}
// 创建新路径,更新父节点,进入下一级
nodePath = nodePath + "/" + xpathArray[i];
parentNode = rootMap.SelectSingleNode(nodePath);
}
return parentNode;
}
// 构建 XPath,使其以 /Cache 为根结点,并清除多于的"/"字符
private string PrepareXPath(string xpath) {
string[] xpathArray = xpath.Split('/');
xpath = "/Cache"; // 这里的名称需与构造函数中创建的根结点名称对应
foreach (string s in xpathArray) {
if (s != "") {
xpath += "/" + s;
}
}
return xpath;
}
AddItem()方法用于向缓存中添加对象,包括了下面几个步骤:
- 根据输入的XPath判断到达 叶结点 的路径是否已经存在,如果不存在,调用上面的CreateNode()方法,逐层创建结点。
- 生成GUID,在组结点下创建 XmlNode 叶结点,为叶结点添加属性Key,并将值设为GUID。
- 将对象保存至实际的位置,默认实现是一个Hashtable,通过调用ICacheStrategy.AddItem()方法来完成,并将Hashtable的Key设置为GUID。
NOTE: 为了说明方便,这里有一个我对一类结点的命名--“组结点”。假设有XPath路径:/Cache/BookStore/Book/Title,那么/Cache/BookStore/Book即为“组结点”,称其为“组结点”,是因为其下可包含多个叶结点,比如 /Cache/BookStore/Book/Author 包含了叶结点 Author;而/Cache/BookStore/Book/Title 中的Title为叶结点,GUID存储在叶结点的属性中。需要注意 组结点 和 叶结点是相对的,对于路径 /Cache/BookStore/Book 来说,它的组结点就是“/Cache/BookStore”,而 Book是它的叶结点。
下面是AddItem()方法的完整代码:
// 添加对象,对象实际上还是添加到ICacheStrategy指定的存储位置,
// 动态创建的 Xml 结点仅保存了对象的Id(key),用于映射两者间的关系
public virtual void AddItem(string xpath, object obj) {
// 获取 Xpath,例如 /Cache/BookStore/Book/Title
string newXpath = PrepareXPath(xpath);
int separator = newXpath.LastIndexOf("/");
// 获取组结点的层叠顺序 ,例如 /Cache/BookStore/Book
string group = newXpath.Substring(0, separator);
// 获取叶结点名称,例如 Title
string element = newXpath.Substring(separator + 1);
// 获取组结点
XmlNode groupNode = rootMap.SelectSingleNode(group);
// 如果组结点不存在,创建之
if (groupNode == null) {
lock (this) {
groupNode = CreateNode(group);
}
}
// 创建一个唯一的 key ,用来映射 Xml 和对象的主键
string key = Guid.NewGuid().ToString();
// 创建一个新结点
XmlElement objectElement = rootMap.OwnerDocument.CreateElement(element);
// 创建结点属性 key
XmlAttribute objectAttribute = rootMap.OwnerDocument.CreateAttribute("key");
// 设置属性值为 刚才生成的 Guid
objectAttribute.Value = key;
// 将属性添加到结点
objectElement.Attributes.Append(objectAttribute);
// 将结点添加到 groupNode 下面(groupNode为Xpath的层次部分)
groupNode.AppendChild(objectElement);
// 将 key 和 对象添加到实际的存储位置,比如Hashtable
cacheStrategy.AddItem(key, obj);
}
RemoveItem()则用于从缓存中删除对象,它也包含了两个步骤:1、先从Xml文档树中删除结点;2、再从实际的存储位置(Hashtable)中删除对象。这里需要注意的是:如果XPath指定的是一个叶结点,那么直接删除该结点;如果XPath指定的是组结点,那么需要删除组结点下的所有结点。代码如下:
// 根据 XPath 删除对象
public virtual void RemoveItem(string xpath) {
xpath = PrepareXPath(xpath);
XmlNode result = rootMap.SelectSingleNode(xpath);
string key; // 对象的Id
// 如果 result 是一个组结点(含有子结点)
if (result.HasChildNodes) {
// 选择所有包含有key属性的的结点
XmlNodeList nodeList = result.SelectNodes("descendant::*[@key]");
foreach (XmlNode node in nodeList) {
key = node.Attributes["key"].Value;
// 从 Xml 文档中删除结点
node.ParentNode.RemoveChild(node);
// 从实际存储中删除结点
cacheStrategy.RemoveItem(key);
}
} else { // 如果 result 是一个叶结点(不含子结点)
key = result.Attributes["key"].Value;
result.ParentNode.RemoveChild(result);
cacheStrategy.RemoveItem(key);
}
}
最后的两个方法,GetItem()和GetList()分别用于从缓存中获取单个或者多个对象。值得注意的是当使用GetList()方法时,Xpath应该为到达一个组结点的路径。
// 根据 XPath 获取对象
// 先根据Xpath获得对象的Key,然后再根据Key获取实际对象
public virtual object GetItem(string xpath) {
object obj = null;
xpath = PrepareXPath(xpath);
XmlNode node = rootMap.SelectSingleNode(xpath);
if (node != null) {
// 获取对象的Key
string key = node.Attributes["key"].Value;
// 获取实际对象
obj = cacheStrategy.GetItem(key);
}
return obj;
}
// 获取一组对象,此时xpath为一个组结点
public virtual object[] GetList(string xpath) {
xpath = PrepareXPath(xpath);
XmlNode group = rootMap.SelectSingleNode(xpath);
// 获取该结点下的所有子结点(使用[@key]确保子结点一定包含key属性)
XmlNodeList results = group.SelectNodes(xpath + "/*[@key]");
ArrayList objects = new ArrayList();
string key;
foreach (XmlNode result in results) {
key = result.Attributes["key"].Value;
Object obj = cacheStrategy.GetItem(key);
objects.Add(obj);
}
return (object[])objects.ToArray(typeof(object));
}
至此,SAF 的缓存服务的设计和代码实现都完成了,现在我们来看看如何使用它。
程序测试
static void Main(string[] args) {
CacheService.Cache cache = CacheService.Cache.Instance;
// 添加对象到缓存中
cache.AddItem("/WebApplication/Users/Xin", "customer xin");
cache.AddItem("/WebApplication/Users/Jimmy", "customer jimmy");
cache.AddItem("/WebApplication/Users/Steve", "customer other");
cache.AddItem("/WebApplication/GlobalData", "1/1/2008");
cache.AddItem("/Version", "v10120080401");
cache.AddItem("/Site", "TraceFact.Net");
// 获取所有User
object[] objects = cache.GetList("/WebApplication/Users");
foreach (object obj in objects) {
Console.WriteLine("Customer in cache: {0}", obj.ToString());
}
// 删除所有WebApplication下所有子孙结点
cache.RemoveItem("/WebApplication");
// 获取单个对象
string time = (string)cache.GetItem("/WebApplication/GlobalData");
string name = (string)cache.GetItem("/WebApplication/Users/Xin");
Console.WriteLine("Time: {0}", time);// 输出为空,WebApplication下所有结点已删除
Console.WriteLine("User: {0}", name);// 输出为空, WebApplication下所有结点已删除
// 获取根目录下所有叶结点
objects = cache.GetList("/");
foreach (object obj in objects) {
Console.WriteLine("Object: {0}", obj.ToString());
}
Console.ReadLine();
}
输出的结果为:
Customer in cache: customer xin
Customer in cache: customer jimmy
Customer in cache: customer other
Time:
User:
Object: v10120080401
Object: Trace