之前接触的一个业务,数据量的话现在在数据库中存了有将近400W的数据,在搜索的时候得到的这些数据会放入达到异步队列中,然后单独开一个线程来进行双写,写缓存,然后写数据库。Redis中的存储格式是Hash存储的,数据库的存储格式类似Hash,当时设计存储方式的时候是有些问题的,在Redis中存储的时候,数据库中有多少条数据,Redis中就会有多少个Key值。也就是说Redis中存储的一级Key有400W个,这样的存储格式会造成Redis的查询变慢,具体的原因下面解释。
| 具体原因 |
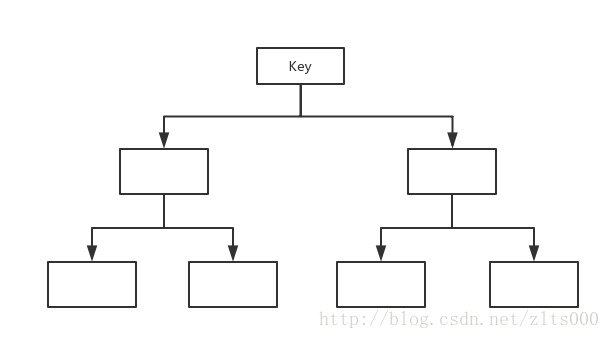
Redis的查询,都是根据Key值来操作的,Hash可以Key值或者根据Key和Field来确定一条记录。具体的操作可以去百度。其实可以把Redis的存储看成一棵树。Key是最顶端的存在。
数据量小的情况下,存储的话没有太大的要求。但是当数据量大的时候,就要细细的考虑下值的存储方式。正如我上边存储400W数据的方式,相当于把400W的数据都放到了一级Key上,就是没有任何的深度而言。
所有的Key都存储在了同一个层级上,这样的话,当查询的时候,就要遍历400W个Key值来找到你想要的数据。自己都感觉自己的设计是一坨翔。。。

| 优化设计 |
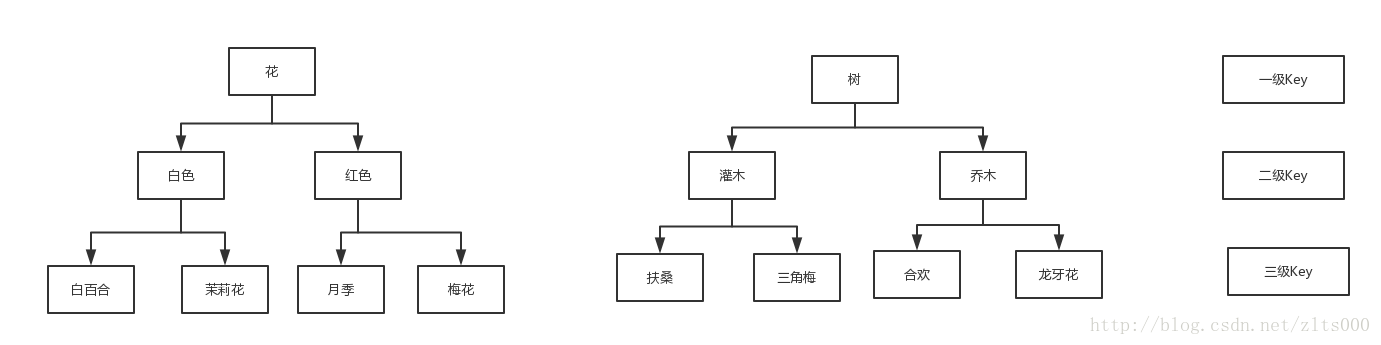
最好的办法,就是减少一级Key的数量。举个例子,花和树。假如全世界有花共100W种类,树也有100W,那怎么设计存储方式?
一级Key的设计要有自己的特点,这样删除的时候也很方便去删除。正如上图的设计一样,我要是查询一种具体的花,一级Key就可以过滤掉100W的数据,然后有可能知道具体的花的种类,再子节点查找的时候,每到一个子节点都可以过滤掉10倍的数据。这样才是最合适的。存的数据多,但是查询的时候也能够快速的定位到你想要的数据,何乐而不为呢?
转载请注明出处:http://blog.csdn.net/zlts000/article/details/56278531

