在2016杭州云栖大会的“开源数据库之Redis专场”上,高德开放平台总经理童遥带来了题为《高德经典数据库实践案例分享》精彩演讲。演讲中,他主要介绍了高德业务下的经典数据库实践案例。
以下内容根据演讲PPT及现场分享整理。
目前用户使用的高德地图,其实是C端地图,另外还有两个出口:一个是车机地图;另外一个是开放平台。开放平台就是行业合作,比如说使用打车应用或社交应用会请求高德的API,简单地说,就是SDK和API的业务。

作为互联网世界底图,目前10部手机中就有9部在使用高德的位置服务,简单介绍下三个行业的案例:高德开放平台为国内85%的车行App提供地图、导航和路径规划服务;为市场中超过60%的外卖App提供地图和定位服务;为80%的主流社交应用提供精准位置和搜索功能,如发微博时的地点定位。目前,大概有30万款应用正在使用高德开放平台业务。
高德经典数据库应用场景
高德的经典数据库应用场景里面怎样同时为C端和B端用户提供全量服务的呢?实际上两者模式完全不一样,C端有高峰,对于高德,可能十一的第一天就是C端的高峰;对于微博来讲,女排夺冠那天可能就是高峰;但B端很坑,它的高峰每天都有,30万个应用每天都有自己的业务高峰,它们各自的高峰就是B端的高峰。
Cache场景
Cache场景主要偏向机房和机房之间整个应用的部署。当业务做到一定规模的时候,可靠性就很难做到,需要依赖很多环境。例如阿里云的某些技术在下层会有很多链路、机房、甚至说一些技术提供商的劫持问题,在做服务时,也相应地诞生非常多的可能性。
下面来看一下机房之间的Redis应用。

先从最简单的同城双机房开始。当业务达到一定程度时,需要部署双机房,通常会选在同一个城市,将应用成本降到最低。将其中一个机房当做Cache用,通常是把它直接落到一个地方,这就相当于有两个机房,但是Redis只在一个机房里。这是最简单的,也是业务方面极为常见的一个场景。在做一个新业务的时,可以先用这种方式过渡,当业务量不大时,这是最快的一种方式。这一点也说明了服务化还有很长的路要走;如果服务化做得好,会直接达到非常完美的状态。

第二种也很简单:在业务层面做一些取舍。例如两个机房,并希望读取的次数高时,可以做一个双写。这不是一个正统和学术的方式,它会导致一致性的问题:如果双写时本机房的写好了但超时了,这时就不知道写没写进去。
因此Cache场景可以简单粗暴的处理一些问题,尽可能拿到98%、99%的收益。采用这种方式的好处是:读和写非常稳定。这里需要注意的是同城之间,因为同城之间的风险就是在双写的那一刻,不是写失败的问题,而是不知道有没有写成功。同城双机房缓存双写的情况是只读自己的,放弃写入到A或B,它会像当前逻辑上的Master去做写入,所以这个时候是跨机房的。
Codis集群部署

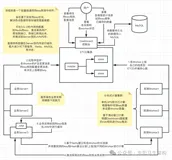
高德在Codis方面起步较晚。目前,高德所有的主流业务都在自家的平台上;还有一些业务依赖Redis。利用Codis部署将上层流量分下来,再通过业务化Hash将其分到不同的分组去,也可能是同城两个机房的某个地方;图中的ZK既用作Master接入点的发现,也用来做分组信息的维护。在此类场景中,一个实例上或多个实例上会有不同的GROUP,通过分组信息,找到这个GROUP,再把数据写进去或者读出来,整体的读取或写入流量是由上层通过业务负载进行转发。
上图左下角表达的是业务监控系统监控机房,当压力比较大时会有一些抖动,这时要判断需不需要响应。目前,架构中存在两套业务监控系统:一套是性能层面;一套是语义层面。即有一个监测内存、CPU等;有一个负责业务。

接下来到高德真正利用到Redis原生机制做双机房同步的时候了:为了缓存同步的一致性,将数据化打开,采用持久化去做同步。但实际在这种状态下,有一个机制判断当前谁是主、谁是从、哪里是写入点,把它写入到对应的Master里面,然后其他节点会依照Redis把它拷贝过去。
持久化场景

高德主营地图业务,会有一些数据更新的场景,比如今天通过数据挖掘发现有一家加油站不营业,那怎么发现呢。就是说以前在9点钟的时候,用户的定位点这里会有50辆车,今天发现只有一辆或都没有了,这样持续了一定时间后,就知道出问题了,再去查证,所以就会有数据的更新。最土的方式就是不把一批量的数据更新,而以A/B集群的方式更新,这样可以避免很多写入时候的延迟对整个性能的影响问题。这时写入是一个持续的操作,当写入完成的时候会有一个校验的流程,当一切确认的时候,会切换进去(这里有一个冷集群和一个热集群)。这是地图行业比较讨巧的一个做法,在纯线上业务可能不太会这么做,但在一些集中性的数据发布时就比较常见。
现在描述数据更新业务的时候,实际上在更新之后会有一个ZK的机制做切换,业务会自动地通过信息知道现在处于哪个集群。当新集群上线之后,旧集群会等待下一次数据更新。

谈到同步,上图其实是Albiter的图,但在Redis里也相同。当在同城之间需要判断主和从是否要需要提升时,其实不能依赖两个节点的判断来做。这是因为:一是两者之间没有办法判断谁是活的、谁是死的,大家都觉得自己是活的;还有一个原因是网络抖动很有可能在很短的时间发生并在很短的时间内恢复,比如说抖动了5秒或6秒,这时对持久化数据库的简单主从的提升操作会加剧数据的不一致,所以会引入第三个机房来帮助判断。

在跨城的场景下,以计费为例。计费是流量的统计,就是说一个开放平台,发流量配额给一些合作伙伴,给你一分钟200万的配额,那你的请求实际上是落到全国各地阿里云的机房,那如何快速有效地统计这些流量,在超量的时候及时告诉你呢?
这是一个核心问题,其实是一个跨机房汇总问题。也就是说,如果每个流量收一毛钱,那用户设置的时候,我只想要100万流量,超过就停掉,那跨机房统计费用的及时性就直接导致了控制是否准确。但如果因为数据的不同步,在外地多跑了20万,那这20万就收不到钱。本质上这是一个时效性问题,如果接入点在多个机房,并且机房距离比较远,那怎么保证时效的正确性?基本做法是在所有机房的接入层把所有流量原封不动地写入到缓存集群;然后缓存集群会分时延做出一个Snapshot,时延随着业务压力大小而变化,并直接影响到计费统计的反应能力。这样超量就会发现,时延会保证流量及时地记录下来。记下来之后会通过阶段性的Snapshot,专门有一个程序往计费集群中写。
计费集群也是Redis的上层应用。在跨机房之间有ZK的全职,上面的Redis互相不同步,只有本机房的信息,计费集群跨机房择主,那么这个程序就会向被选为主的集群写入信息来归总这份数据,里面如果涉及到无法确定或无法连接的情况,(因为是Snapshot场景)它会等待可用。就是说你规定了15秒的快照时间,有可能因为推迟会变成30秒或40秒,那么在计费集群的HBase下面会有一个Open TSDB做真正的存储。上层的Redis会保留一段时间,如果出现一些计算错误或用户投诉,就反查回来看一下是不是有问题,但本质上是以最终落地的那份数据为主。但这个例子不是实时,计费报表并不是马上出,可能第二天或过两天才出。所以这里在业务上做了一些取舍,会把实时牺牲掉来保证正确性或性能。

顺便提一下分片混合部署,现在高德不会有较大的抖动,数据自动地分布到不同的机房和节点,可以保证一个小分片同时会有三个副本,且不在同一个机器上。这也使得数据向下切割成一个分片时保证存储可靠,但是它始终会有一个Primary的主写入节点。

下面这一步很多人都会遇到,当数据热了要重新分布就会有Proxy的改造方案,相当于把数据的分布策略和动态的重新平衡策略做进DB,不再拿给业务做。这是因为当只有一个主流业务,可以全身心关注;但是如果有20个业务,每天都有不同的出问题,这就有了Proxy的方案,希望把整个发现全都放在Redis里面,业务不必Care。典型的逻辑是把服务的发现和Hash全都放在一个Proxy层里面,然后通过一个额外配置的中间管理去Client,使其知道应该读哪个Proxy。
异地单元化&就近接入
最后简单分享一下真正的挑战,刚刚讲的很多场景都有取舍。读完马上就要写的业务,这种场景最难。

未来,高德会同阿里云一道设计就近接入的方案,该业务和地理位置高度相关,把用户数据放在离他比较近的地方。其实就是把用户的数据按照对应纬度或所属地区的纬度切分到对应的机房去,用干预的方式尽量选到所属的主节点,在主节点不出问题的情况下,希望用户的数据从哪里写就从哪里读。其他机房会作为他异步传输的同步。
这其中除了涉及到数据搬迁,还有最上层的流量分配(如何保证把用户分发到正确的地方去)。高大上的答案是可以通过地域化的DNS,但一定会有百分之几比例的用户会发错,这种情况下就通过7层把流量转发过去,此时会有30毫秒的IT开销甚至数以倍计的可靠性的下降,这只是一个短暂的方式,将来会通过Channel的建设,DNS的解析等尽量去提高分发的比例,这也是高德正在做的一个事情。