接着来搞树!
支持云栖社区,也希望大家能支持下我的独立博客——白水东城
文章地址:
算法之树(二,B+树、哈夫曼树、堆、红黑树)(Java版)-持续更新补充
一、B+树
B+树的特征
- 有k个子树的中间节点包含有k个元素(B树中是k-1个元素),每个元素不保存数据,只用来索引,所有数据都保存在叶子节点。
- 所有的叶子结点中包含了全部元素的信息,及指向含这些元素记录的指针,且叶子结点本身依关键字的大小自小而大顺序链接。
- 所有的中间节点元素都同时存在于子节点,在子节点元素中是最大(或最小)元素。
如图(图片来自程序员小灰)

在程序员小灰的公众号里提到了一个概念——卫星数据:索引元素指向的数据记录,比如数据库中的某一行。在B+树中只有叶子节点带卫星数据,其他的中间节点只是索引,没有任何数据关联。在数据库的聚集索引(Clustered Index)中,叶子节点直接包含卫星数据。在非聚集索引(NonClustered Index)中,叶子节点带有指向卫星数据的指针。 吧
B+树的优势
- 单一节点存储更多元素。B+树中间节点没有卫星数据(也就是说只包含索引信息),所以每个非叶子节点可以包含更多的内容,同样大小的磁盘页可以容纳更多的节点元素。也就是说B+树会在相同数据量的情况下比B树更加“矮胖”,查询的IO次数更少。
- 查询效率稳定。B+树的查询必须最终找到叶子节点,而B树如果在中间节点找到匹配的即可(最好情况是只查根节点,最差是查到叶子节点),而B+树每一次都是稳定的。B-树的好处是,虽然查询性能不稳定,但平均的查询速度快一些。试想一个数据库的查询,有时候执行10毫秒,有时候执行100毫秒,肯定是不太合适的。还不如每次都执行30毫秒。
- 范围查询简便。B树的范围查询只能依靠繁琐的中序遍历,找到下限和上限。而B+树的范围查询很简单,只需要在叶子节点那一层的链表上做遍历就行。
为什么数据库中一定要索引
二分查找,二叉树查找都依赖特定的数据结构,分别是待查找数据有序、二叉查找树,显然数据本身不能完全满足各种数据结构。
所以,数据库除了维护数据之外,还维护者满足特定查找算法的数据结构——索引,索引以某种方式引用数据,这样就可以在索引的基础上实现高级的查找等操作。目前大部分数据库系统和文件系统都采用B树或者变种的B+树来作为索引结构。
为什么MySQL数据库中使用B+树
1.局部性原理与磁盘预读
由于磁盘的存取速度与内存之间鸿沟,为了提高效率,要尽量减少磁盘I/O.磁盘往往不是严格按需读取,而是每次都会预读,磁盘读取完需要的数据,会顺序向后读一定长度的数据放入内存。而这样做的理论依据是计算机科学中著名的局部性原理:
当一个数据被用到时,其附近的数据也通常会马上被使用,程序运行期间所需要的数据通常比较集中
由于磁盘顺序读取的效率很高(不需要寻道时间,只需很少的旋转时间),因此对于具有局部性的程序来说,预读可以提高I/O效率.预读的长度一般为页(page)的整倍数。
2.数据库索引采用B+树的主要原因
根据上面的局部性原理和磁盘预读,B树中用了这个技巧:每次新建节点时,直接申请一个页的空间,这样就保证一个节点物理上也存储在一个页里,加之计算机存储分配都是按页对齐的,就实现了一个结点只需一次I/O。
B树在提高了IO性能的同时并没有解决元素遍历的效率低下的问题,正是为了解决这个问题,B+树应用而生。B+树只需要去遍历叶子节点就可以实现整棵树的遍历。而且在数据库中基于范围的查询是非常频繁(比如查询某段时间之内的数据)的,而B树不支持这样的操作或者说效率太低(前文已经说明效率低的原因)。
二、哈夫曼树
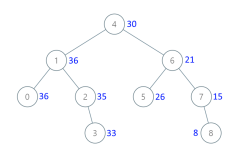
带权路径长度最小的树就叫最优二叉树,也就是哈夫曼树。要使带权路径长度最小,那么权值大的点就应该离根节点越近。
构造方法:先从小到大排序,然后选择最小的两棵树合并,重复这两个步骤。
哈夫曼编码
如果对一段英文转换为二进制传输,采用哈夫曼编码,让频率高的用短码,频率低的用长码,而且保证不会有某个字符的串是另一个字符的前缀(因为如果每个字符的长度不一样会出现这样的问题,比如,一个字符被11表示,另一个被110表示,出现一段11011,这样就有歧义)
哈夫曼树实现
之前数据结构课上用C写过哈夫曼树,Java的暂时不搞了,之后遇见再回来补充。
三、堆
堆是一个完全二叉树,大顶堆就是每个节点都不大于它的父节点。
插入和删除时间复杂度都是O(logn)。
堆排序
初始化一个堆,然后把无序数组的每个值都依次插入堆中,然后一直删除,把被删除的元素放到数组的最后一个有效元素之后的位置。
public class Heap {
private int[] element;
public Heap(int maxSize) {
element = new int[maxSize];
element[0] = 0;//存放堆中实际的个数
}
public boolean isEmpty() {
return element[0] == 0;
}
public boolean isFull() {
return element[0] == element.length - 1;
}
public void insert(int value) {
if(isFull()) {
throw new IndexOutOfBoundsException("堆已经满啦..");
}
if(isEmpty()) {
element[1] = value;
}else {
int i = element[0] + 1;
while(i != 1 && value > element[i / 2]) {
element[i] = element[i / 2];
i /= 2;
}
element[i] = value;
}
element[0] ++;
}
public int delete() {
if(isEmpty()) {
throw new IndexOutOfBoundsException("堆空啦");
}
int deleteElement = element[1];
element[1] = element[element[0]];
element[0]--;
int value = element[1];
int parent = 1;
int child = 2;
while(child <= element[0]) {
if(child + 1 <= element[0] && element[child] < element[child + 1]) {
child ++;
}
if(value >= element[child]) {
break;
}else {
element[parent] = element[child];
parent = child;
child *= 2;
}
}
element[parent] = value;
return deleteElement;
}
public void printAll() {
for(int i = 0; i < element[0]; i++) {
System.out.print(element[i]);
if(i != element[0]) {
System.out.print(",");
}
}
System.out.println();
}
public void sort() {
int size = element[0];
for(int i = 0; i < size; i++) {
int deleteElement = delete();
element[element[0] + 1] = deleteElement;
}
for(int i = 1; i <= size; i++) {
System.out.print(element[i]);
if(i != size) {
System.out.print(",");
}
}
}
}
AI 代码解读
红黑树
红黑树的插入、删除、查找最坏时间复杂度都是O(logn)。
红黑树理解概念就OK了,目前不深入研究。
推荐一篇很好的对红黑树的概念理解文章:
漫画:什么是红黑树?