应用场景
当我们按照hadoop完全分布式集群搭建博客搭建了hadoop以后,发现这是一个空的hadoop,只有YARN,MapReduce,HDFS,而这些实际上我们一般不会直接使用,而是需要另外部署Hadoop的其他组件,来辅助使用。比如我们需要数据库,那么hadoop提供了分布式非关系型数据库hbase,用来存储半结构化,非结构化的一些数据,供我们查询使用等,下面我们来介绍一下,如何实现在完全分布式hadoop集群之上安装hbase。
操作步骤
1. 下载hbase1.2.6压缩包
hbase1.2.6下载地址
下载后上传到管理节点的opt目录下
2. 解压缩hbase和修改目录名
# cd /opt
# tar -xzvf hbase-1.2.6-bin.tar.gz
# mv hbase-1.2.6 hbase1.2.6
# chmod 777 -R /opt/hbase1.2.63. 配置环境变量
# vim /etc/profile
export JAVA_HOME=/opt/jdk1.8
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$PATH:$JAVA_HOME/bin
export HADOOP_HOME=/opt/hadoop2.6.0
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
export HIVE_HOME=/opt/hive2.1.1
export HIVE_CONF_DIR=$HIVE_HOME/conf
export CLASSPATH=.:$HIVE_HOME/lib:$CLASSPATH
export PATH=$PATH:$HIVE_HOME/bin
export SQOOP_HOME=/opt/sqoop1.4.6
export PATH=$PATH:$SQOOP_HOME/bin
export ZOOKEEPER_HOME=/opt/zookeeper3.4.10
export PATH=$PATH:$ZOOKEEPER_HOME/bin
export HBASE_HOME=/opt/hbase1.2.6
export PATH=$PATH:$HBASE_HOME/bin #添加最后两行,hbase的相关环境变量属性 # source /etc/profile #使环境变量配置生效4. 修改hbase-env.sh配置文件
# vim /opt/hbase1.2.6/conf/hbase-env.sh
export JAVA_HOME=/opt/jdk1.8
export HADOOP_HOME=/opt/hadoop2.6.0
export HBASE_HOME=/opt/hbase1.2.6
export HBASE_CLASSPATH=/opt/hadoop2.6.0/etc/hadoop
export HBASE_PID_DIR=/opt/hbase1.2.6/pids
export HBASE_MANAGES_ZK=false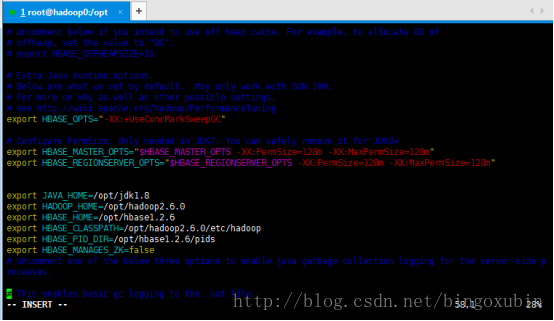
5. 修改hbase-site.xml配置文件
# 创建目录
# mkdir /opt/hbase1.2.6/tmp
# mkdir /opt/hbase1.2.6/pids # cd /opt/hbase1.2.6/conf/
# vim hbase-site.xml
<configuration>
<property>
<name>hbase.rootdir</name>
<value>hdfs://hadoop0:9000/hbase</value>
<description>The directory shared byregion servers.</description>
</property>
<property>
<name>hbase.zookeeper.property.clientPort</name>
<value>2181</value>
<description>Property from ZooKeeper'sconfig zoo.cfg. The port at which the clients will connect.
</description>
</property>
<property>
<name>zookeeper.session.timeout</name>
<value>120000</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>hadoop0,hadoop1,hadoop2</value>
</property>
<property>
<name>hbase.tmp.dir</name>
<value>/opt/hbase1.2.6/tmp</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
</configuration>6. 修改regionservers配置文件
# cd /opt/hbase1.2.6/conf
# vim regionservers # 添加集群的三个主机名
hadoop0
hadoop1
hadoop27. 拷贝管理节点的hbase到其他两个节点
# cd /opt/
# scp -r hbase1.2.6 root@hadoop1:/opt/
# scp -r hbase1.2.6 root@hadoop2:/opt/
# 修改环境变量添加【在其他两个节点】
export HBASE_HOME=/opt/hbase1.2.6
export PATH=$PATH:$HBASE_HOME/bin8. 启动和测试
启动
首先先确保,hadoop和zookeeper正常运行,然后只需要在管理节点启动Hbase即可。
# cd /opt//hbase1.2.6/bin
# ./start-hbase.sh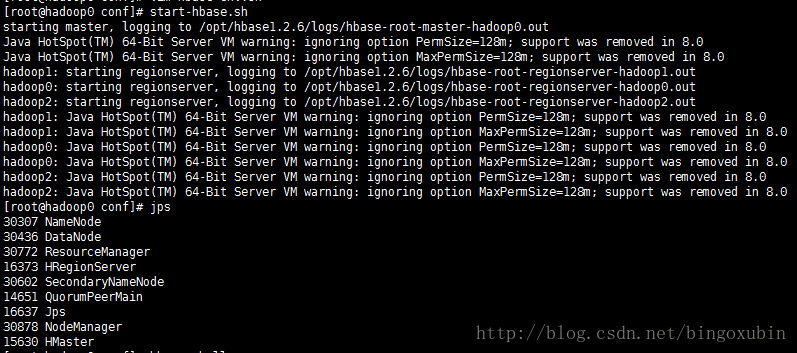
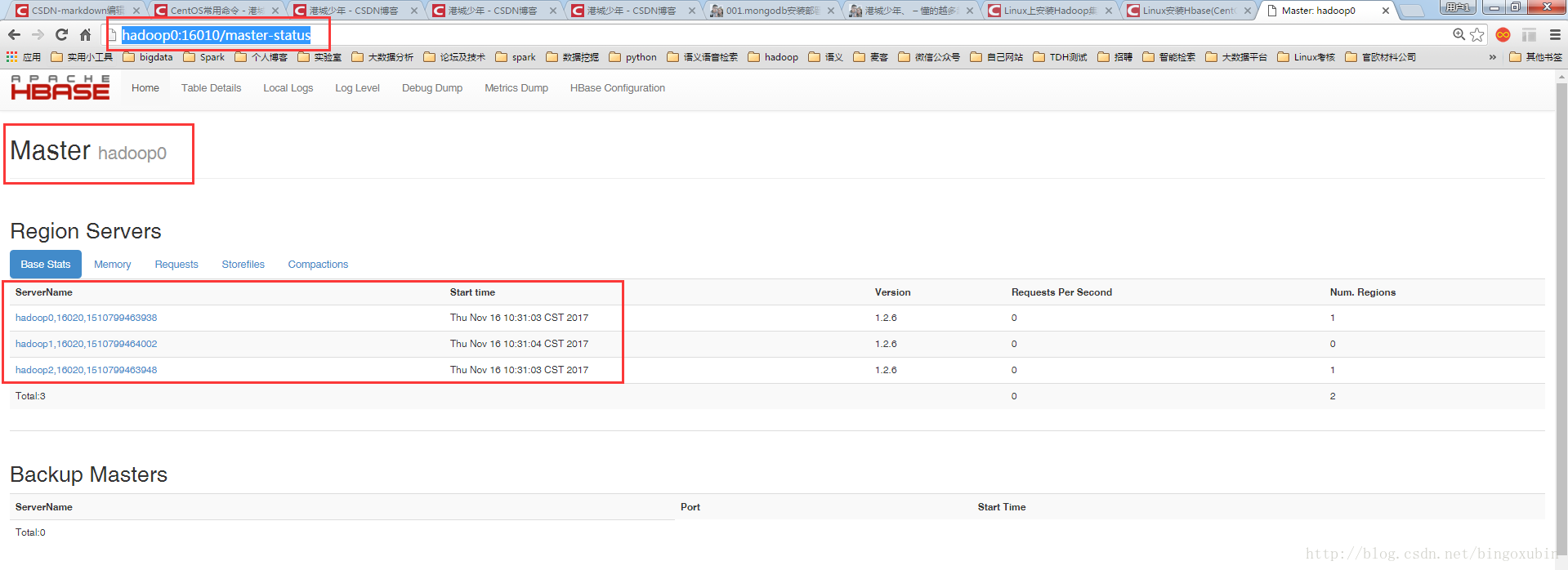
测试
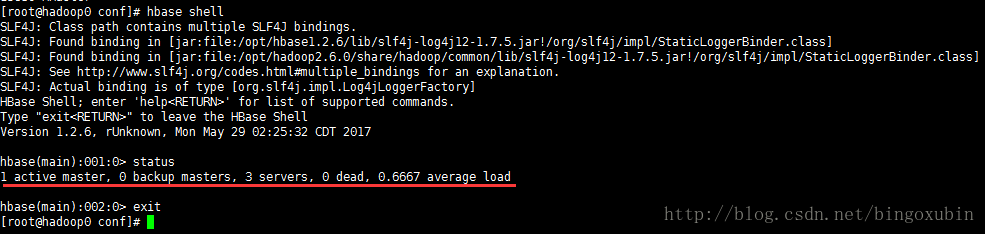
在主节点命令行,输入hbase shell,启动hbase后台