应用场景
当我们安装好Hadoop分布式集群后,默认底层计算是采用MapReduce,速度比较慢,适用于跑批场景,而Spark可以和hadoop完美的融合,Spark提供了更强劲的计算能力,它基于内存计算,速度快,效率高。虽然Spark也支持单机安装,但是这样就不涉及分布式计算,以及分布式存储,如果我们要用Spark集群,那么就需要分布式的hadoop环境,调用hadoop的分布式文件系统,本篇博文来学习分布式Spark的安装部署!
操作步骤
1. Scala2.11.6配置
1.1 下载Scala2.11.6
Scala2.11.6下载地址,下载scala2.11.6压缩包,上传到主节点的opt目录下
1.2 解压缩并更换目录
# cd /opt/
# tar -xzvf scala-2.11.6.tgz
# mv scala-2.11.6 scala2.11.61.3 配置环境变量
# vim /etc/profile
export JAVA_HOME=/opt/jdk1.8
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$PATH:$JAVA_HOME/bin
export HADOOP_HOME=/opt/hadoop2.6.0
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
export HIVE_HOME=/opt/hive2.1.1
export HIVE_CONF_DIR=$HIVE_HOME/conf
export CLASSPATH=.:$HIVE_HOME/lib:$CLASSPATH
export PATH=$PATH:$HIVE_HOME/bin
export SQOOP_HOME=/opt/sqoop1.4.6
export PATH=$PATH:$SQOOP_HOME/bin
export ZK_HOME=/opt/zookeeper3.4.10
export PATH=$PATH:$ZK_HOME/bin
export HBASE_HOME=/opt/hbase1.2.6
export PATH=$PATH:$HBASE_HOME/bin
export SCALA_HOME=/opt/scala2.11.6
export PATH=$PATH:$SCALA_HOME/bin
#加上最后两行,关于scala的环境变量配置 # source /etc/profile #使环境变量配置生效1.4 验证scala配置
# scala -version
2. Spark1.6.1配置
2.1 下载Spark1.6.1
spark1.6.1下载地址,下载spark1.6.1压缩包,上传到主节点的opt目录下
2.2 解压缩并更换目录
# cd /opt
# tar -xzvf spark-1.6.1-bin-hadoop2.6.tgz
# mv spark-1.6.1-bin-hadoop2.6 spark1.6.12.3 配置环境变量
# vim /etc/profile
export JAVA_HOME=/opt/jdk1.8
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$PATH:$JAVA_HOME/bin
export HADOOP_HOME=/opt/hadoop2.6.0
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
export HIVE_HOME=/opt/hive2.1.1
export HIVE_CONF_DIR=$HIVE_HOME/conf
export CLASSPATH=.:$HIVE_HOME/lib:$CLASSPATH
export PATH=$PATH:$HIVE_HOME/bin
export SQOOP_HOME=/opt/sqoop1.4.6
export PATH=$PATH:$SQOOP_HOME/bin
export ZK_HOME=/opt/zookeeper3.4.10
export PATH=$PATH:$ZK_HOME/bin
export HBASE_HOME=/opt/hbase1.2.6
export PATH=$PATH:$HBASE_HOME/bin
export SCALA_HOME=/opt/scala2.11.6
export PATH=$PATH:$SCALA_HOME/bin
export SPARK_HOME=/opt/spark1.6.1
export PATH=$PATH:$SPARK_HOME/bin
#加上最后两行,关于spark的环境变量配置
#切记,不要把SPARK_HOME/sbin也配置到PATH中,因为sbin下的命令和hadoop中的sbin下的命令很多相似的,避免冲突,所以执行spark的sbin中的命令,要切换到该目录下再执行 # source /etc/profile #使环境变量配置生效3. 修改Spark-env.sh配置文件
# cd /opt/spark1.6.1/conf/
# cp spark-env.sh.template spark-env.sh
# vim spark-env.sh
export SCALA_HOME=/opt/scala2.11.6
export JAVA_HOME=/opt/jdk1.8
export HADOOP_HOME=/opt/hadoop2.6.0
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export SPARK_HOME=/opt/spark1.6.1
export SPARK_MASTER_IP=hadoop0
export SPARK_EXECUTOR_MEMORY=4G #在末尾添加上述配置4. 修改slaves配置文件
# cd /opt/spark1.6.1/conf/
# cp slaves.template slaves
# vim slaves
hadoop1
hadoop2 #删除localhost,添加从节点的两个主机名5. 将主节点的scala2.11.6,spark1.6.1搬到两个从节点上
# cd /opt
# scp -r scala2.11.6 root@hadoop1:/opt/
# scp -r scala2.11.6 root@hadoop2:/opt/
# scp -r spark1.6.1 root@hadoop1:/opt/
# scp -r spark1.6.1 root@hadoop2:/opt/并且修改从节点的环境变量!而且使环境变量生效!
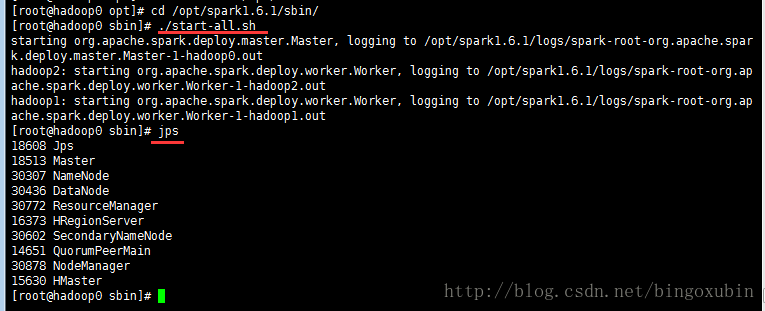
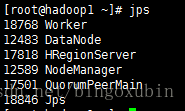
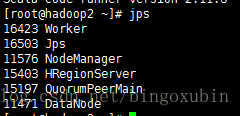
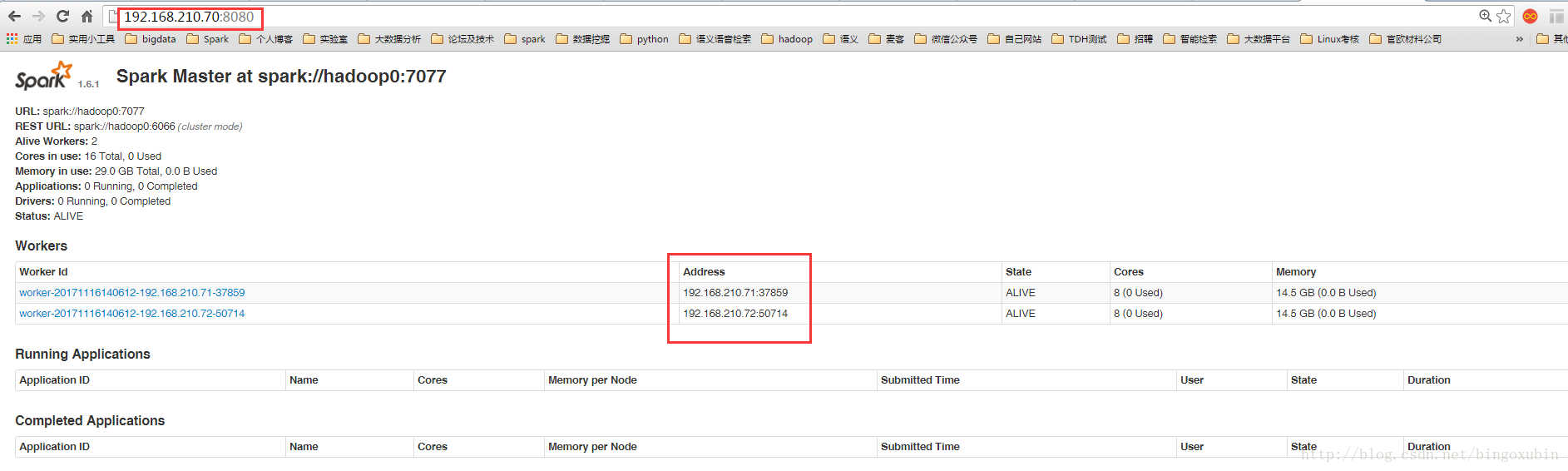
6. 启动并且验证spark
注:在运行spark之前,必须确保hadoop在运行中,因为spark集群是依托于hadoop的。
# cd /opt/spark1.6.1/sbin
# ./start-all.sh