应用场景
部署Hadoop集群过程中,可以使用开源的Apache Hadoop或者可以用CDH【国外的一家公司基于开源的封装的】,搭建更加方便,方便扩充节点规模,组件管控,性能监控等等,但是也有一个弊端,针对组件安装的目录,以及生成的配置文件位置比较难找到,目录结构混乱,所以还是请慎用。
操作步骤
1. 概述
CM: Cloudera Manager (Cloudera公司专有的Hadoop集群管控平台) 。 CDH: Cloudera Distributed Hadoop(Cloudera公司重新打包发布的Hadoop版本) 。
Hadoop是一个由Apache基金会所开发的分布式系统基础架构。用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。
Hadoop实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS。HDFS有高容错性的特点,并且设计用来部署在低廉的(low-cost)硬件上;而且它提供高吞吐量(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。HDFS放宽了(relax)POSIX的要求,可以以流的形式访问(streaming access)文件系统中的数据。
Hadoop的框架最核心的设计就是:HDFS和MapReduce。HDFS为海量的数据提供了存储,则MapReduce为海量的数据提供了计算。
2. 系统环境
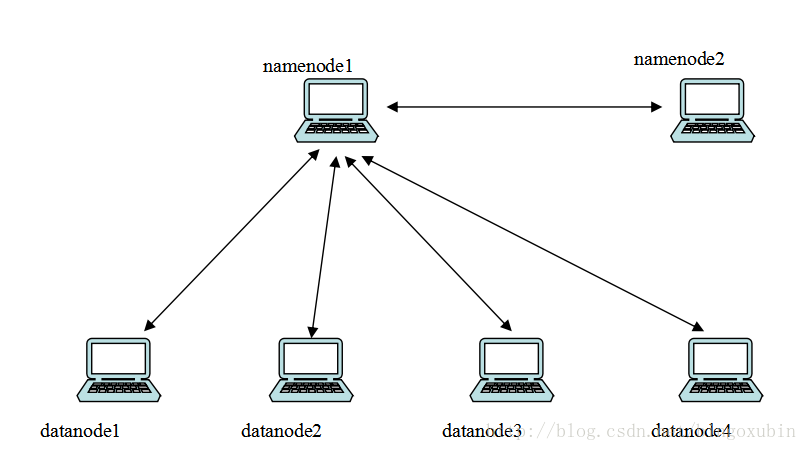
| 节点 | IP地址 | 系统 | 作用 |
|---|---|---|---|
| namenode1 | 10.231.224.60 | CentOS6.5 | 集群主节点,管理集群任务执行,存储 |
| namenode2 | 10.231.224.61 | CentOS6.5 | 主节点的备份节点,主节点失效,接管服务 |
| datanode1 | 10.231.224.64 | CentOS6.5 | 数据节点 |
| datanode2 | 10.231.224.65 | CentOS6.5 | 数据节点 |
| datanode3 | 10.231.224.66 | CentOS6.5 | 数据节点 |
| datanode4 | 10.231.224.67 | CentOS6.5 | 数据节点 |
3. 基础安装及配置
3.1 修改hostname和hosts文件(各个节点)
修改各个节点的hostname,已便于区分各个节点,同时方便下面配置免密码SSH互信操作。
# vim /etc/sysconfig/network
根据上文中的节点环境,将各个节点的hostname,修改为与上文对应,便于区分。
修改后,重启(注:重启生效)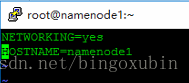
修改hosts文件。
# vim /etc/hosts
每个节点都需要操作。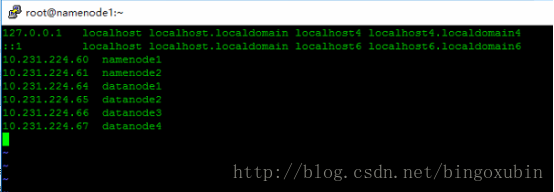
3.2 关闭防火墙和SELinux(各个节点)
关闭防火墙,并且设置为开机不启动。
# service iptables stop
# chkconfig iptables off
关闭SELinux。
# vim /etc/selinux/config
将SELINUX修改为disabled。
重启。3.3 配置SSH操作
- 配置ssh互信的核心思想如下:
-
1.首先,在要配置互信的机器上,生成各自的经过认证的key文件;
2.其次,将所有的key文件汇总到一个总的认证文件中;
3.将这个包含了所有互信机器认证key的认证文件,分发到各个机器中去;
4.验证互信。
在主机名为namenode1,namenode2,datanode1,datanode2,datanode3,datanode4的节点间创建ssh互信。
在每个节点上创建 RSA密钥和公钥,输入如下命令,一路回车
# mkdir ~/.ssh (如果目录存在,就不必要创建)
# chmod 700 ~/.ssh
# cd ~/.ssh
# ssh-keygen -t rsa 整合公钥文件
在namenode1节点上执行以下命令:
# cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
# ssh namenode2 cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
# ssh datanode1 cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
# ssh datanode2 cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
# ssh datanode3 cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
# ssh datanode4 cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
# chmod 600 ~/.ssh/authorized_keys分发整合后的公钥文件
在namenode1节点上执行以下命令
# scp ~/.ssh/authorized_keys namenode2:~/.ssh/
# scp ~/.ssh/authorized_keys datanode1:~/.ssh/
# scp ~/.ssh/authorized_keys datanode2:~/.ssh/
# scp ~/.ssh/authorized_keys datanode3:~/.ssh/
# scp ~/.ssh/authorized_keys datanode4:~/.ssh/ 测试ssh互信
在各个节点上运行以下命令,若不需要输入密码就显示系统当前日期,就说明SSH互信已经配置成功了。
在namenode1节点上输入以下命令:
# ssh namenode2 date
# ssh datanode1 date
# ssh datanode2 date
# ssh datanode3 date
# ssh datanode4 date3.4 配置集群NTP服务(各个节点)
NTP可以使用yum直接安装
# yum install -y ntp
每台机器安装ntp与ntpdate:
# service ntpd start
# chkconfig ntpd on
# chkconfig --list ntpd ##检查是否ntp开启,命令结果,2-5是启用与主控机同步,先配置主控机的时间与实际时间符合,然后搭建时间服务器并进行同步,步骤如下:
(1)配置NTP主机端
# vim /etc/ntp.conf
加入以下内容:
restrict 172.19.21.0 mask 255.255.255.0 nomodify notrap # 允许内网其他机器同步时间
server 127.127.1.0 # 外部时间服务器不可用时,以本地时间作为时间服务
fudge 127.127.1.0 stratum 10
# service ntpd restart
# ntpstat ##查看验证(2)配置NTP客户端
# vim /etc/ntp.conf
注释带server字眼行部分内容
添加 server 主机名或ip 如:server 10.231.224.60
# service ntpd restart
# ntpstat ####查看验证
# ntpdate -u 10.231.224.603.5 安装JDK(各个节点)
这里用的是jdk1.7
卸载原有JDK
# yum remove java
将下载的JDK安装包,拷贝到/usr/local目录下,进行解压缩,把解压缩后的文件夹名改为java。
# cd /usr/local
修改profile配置文件。
# vim /etc/profile
在末尾加上如下3行配置:
export JAVA_HOME=/usr/local/java
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$JAVA_HOME/bin:$PATH
使修改的配置文件生效:
# source /etc/profile
验证:
# java -version3.6 安装mysql(主节点namenode1)
安装:
Centos 6.5下安装Mysql很简单,
# yum list mysql-server
当只有一个时候就可以直接
# yum install mysql-server
进行安装
过程中选择Y继续安装,最后安装成功
# service mysqld start
配置:
设置Mysql开机启动
# chkconfig mysqld on
连接mysql数据库
# mysql
设置密码
mysql>use mysql;
mysql>update user set password=password('gtxd1234') where user='root';
mysql>flush privileges;
以后连接mysql数据库就要用如下命令:
# mysql -uroot -pgtxd1234
创建数据库:
创建以下数据库:
create database hive DEFAULT CHARSET utf8 COLLATE utf8_general_ci; --hive数据库
create database amon DEFAULT CHARSET utf8 COLLATE utf8_general_ci; --集群监控数据库
create database hue DEFAULT CHARSET utf8 COLLATE utf8_general_ci; --hue数据库
create database Oozie DEFAULT CHARSET utf8 COLLATE utf8_general_ci; -oozie数据库
设置root授权访问以上所有的数据库:
grant all privileges on *.* to root@'%' identified by 'gtxd1234' with grant option;
flush privileges;
# service mysqld restart4. 安装Cloudera Manager 5(cm5)
根据自己的系统选择相应的版本,本次安装选用的是cloudera-manager-el6-cm5.4.7_x86_64.tar.gz。下载完成后只上传到master(namenode1)节点即可。然后解压到/opt目录下,不能解压到其他地方,因为cdh5的源会默认在/opt/cloudera/parcel-repo寻找,怎么制作cdh5的本地源文件会在之后介绍。
给所有节点添加cloudera-scm用户:(各个节点)
# useradd --system --home=/opt/cm-5.4.7/run/cloudera-scm-server --no-create-home --shell=/bin/false --comment "Cloudera SCM User" cloudera-scm
修改/opt/cm-5.4.7/etc/cloudera-scm-agent/config.ini 下面的serer_host
# server_host=namenode1
为Cloudera Manager 5建立数据库:
# /opt/cm-5.4.7/share/cmf/schema/scm_prepare_database.sh mysql cm -hlocalhost -uroot -pgtxd1234 --scm-host localhost scm scm scm
格式是:scm_prepare_database.sh 数据库类型 数据库 服务器 用户名 密码 –scm-host Cloudera_Manager_Server所在的机器,后面那三个不知道代表什么,直接照抄官网的了。 因为我们用的是Mysql数据库,所以我们需要下载Mysql的JDBC驱动,本次从官网上下载最新稳定版:mysql-connector-java-5.1.30.tar.gz,解压之后找到mysql-connector-java-5.1.30-bin.jar放到/opt/cm-5.4.7/share/cmf/lib/目录下。 开启Cloudera Manager 5 Server端:
# /opt/cm-5.0.0/etc/init.d/cloudera-scm-server start
注意server首次启动不要立即关闭或重启,因为首次启动会自动创建相关表以及数据,如果因为特殊原因中途退出,请先删除所有表以及数据之后再次启动,否则将会出现启动不成功的情况。 开启Cloudera Manager 5 Agents端。 先scp /opt/cm-5.4.7到所有datanode节点上,然后在每台机器上开启Agents端:
# scp -r /opt/cm-5.4.7 datanode1:/opt/cm-5.4.7
等待拷贝成功,在所有datanode节点上启动:(注意必须以管理员权限启动)
# sudo /opt/cm-5.4.7/etc/init.d/cloudera-scm-agent start
浏览器启动Cloudera Manager 5 控制台(默认端口号是7180),启动成功就会看到登陆页面。(登录用户名admin,密码admin)
5. 安装CDH5
这里需要下载三样东西,首先是与自己系统版本相对应的parcel包,然后是manifest.json文件。下载完成后将这三个文件放到master节点的/opt/cloudera/parcel-repo下(目录在安装Cloudera Manager 5时已经生成),注意目录一个字都不能错,另外需要做一个小的修改,就是将.sha1文件,修改为.sha。
打开http://10.231.224.60:7180,登陆控制台,默认账户和密码都是admin,安装时选择免费版,之后由于cm5对中文的支持很强大,按照提示安装即可,如果系统配置有什么问题在安装过程中会有提示,根据提示给系统安装组件就可以了。
如果在安装时选择了安装Hive,可能会遇到安装失败的问题,查看一下日志发现时安装Hive时需要安装JDBC驱动,所以同样我们将Mysql的驱动包拷贝到/opt/cloudera/parcels/CDH-5.4.7-1.cdh5.4.7.p0.3/lib/hive/lib/目录下,之后再继续安装就不会遇到问题了。




