应用场景
在用CDH5.4.7搭建Hadoop集群的时候,难免遇到一些错误,比如在检查主机的时候遇到各种报错等等。
错误展示:
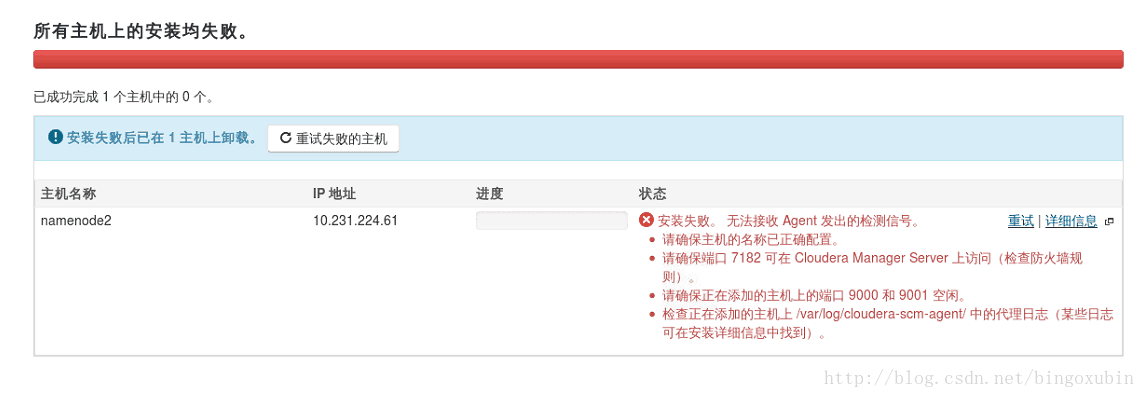
解决方案
server_host可能忘了修改了
# vim /opt/cm-5.4.7/etc/cloudera-scm-agent/config.ini
server_host修改为namenode1在用CDH5.4.7搭建Hadoop集群的时候,难免遇到一些错误,比如在检查主机的时候遇到各种报错等等。
错误展示:
server_host可能忘了修改了
# vim /opt/cm-5.4.7/etc/cloudera-scm-agent/config.ini
server_host修改为namenode1
