应用场景
Flume作为Hadoop中的日志采集工具,非常的好用,但是在安装Flume的时候,查阅很多资料,发现形形色色,有的说安装Flume很简单,有的说安装Flume很复杂,需要依赖zookeeper,所以一方面说直接安装Flume,解压即可用,还有一方面说需要先装了Zookeeper才可以安装Flume。那么为何会才生这种情况呢?其实两者说的都对,只是Flume的不同版本问题。
背景介绍
Cloudera 开发的分布式日志收集系统 Flume,是 hadoop 周边组件之一。其可以实时的将分布在不同节点、机器上的日志收集到 hdfs 中。Flume 初始的发行版本目前被统称为 Flume OG(original generation),属于 cloudera。但随着 FLume 功能的扩展,Flume OG 代码工程臃肿、核心组件设计不合理、核心配置不标准等缺点暴露出来,尤其是在 Flume OG 的最后一个发行版本 0.94.0 中,日志传输不稳定的现象尤为严重,这点可以在 BigInsights 产品文档的 troubleshooting 板块发现。为了解决这些问题,2011 年 10 月 22 号,cloudera 完成了 Flume-728,对 Flume 进行了里程碑式的改动:重构核心组件、核心配置以及代码架构,重构后的版本统称为 Flume NG(next generation);改动的另一原因是将 Flume 纳入 apache 旗下,cloudera Flume 改名为 Apache Flume。
Flume OG
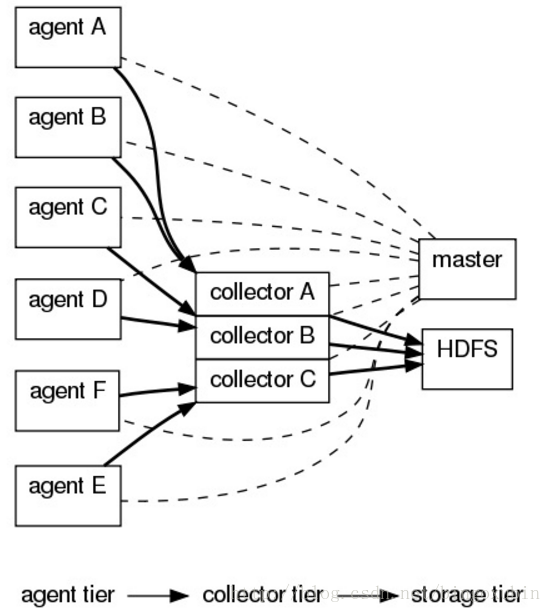
- FLUM OG 有三种角色的节点:代理节点(agent)、收集节点(collector)、主节点(master)。
-
-agent 从各个数据源收集日志数据,将收集到的数据集中到 collector,然后由收集节点汇总存入 hdfs。master 负责管理 agent,collector 的活动。
-agent、collector 都称为 node,node 的角色根据配置的不同分为 logical node(逻辑节点)、physical node(物理节点)。对 logical nodes 和 physical nodes 的区分、配置、使用一直以来都是使用者最头疼的地方。
-agent、collector 由 source、sink 组成,代表在当前节点数据是从 source 传送到 sink。
Flume OG 架构图
Flume OG 节点组成图
Flume NG
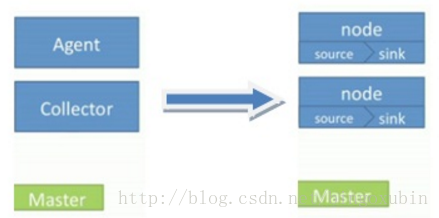
- NG 只有一种角色的节点:代理节点(agent)。
-
没有 collector、master 节点。这是核心组件最核心的变化。
去除了 physical nodes、logical nodes 的概念和相关内容。
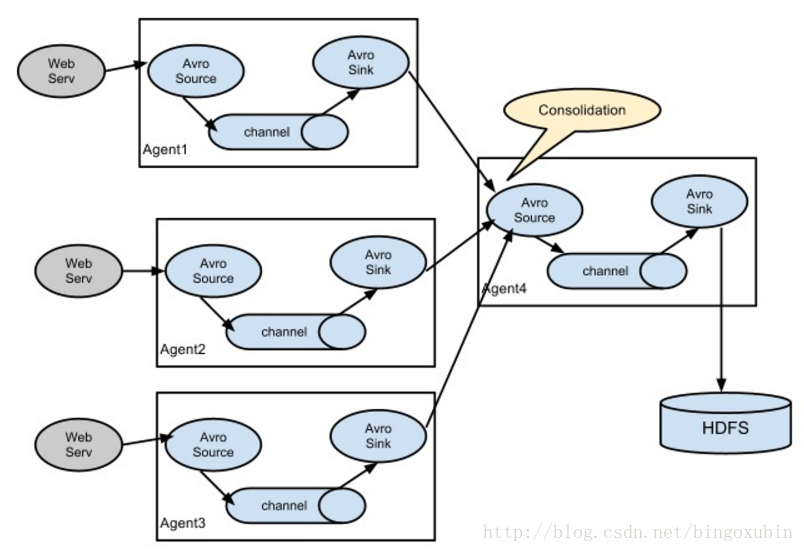
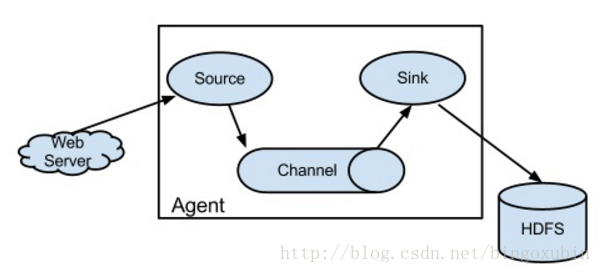
agent 节点的组成也发生了变化。NG agent 由 source、sink、channel 组成。
Flume NG 架构图
Flume NG 节点组成图
Flume OG vs Flume NG
在 OG 版本中,Flume 的使用稳定性依赖 zookeeper。它需要 zookeeper 对其多类节点(agent、collector、master)的工作进行管理,尤其是在集群中配置多个 master 的情况下。当然,OG也可以用内存的方式管理各类节点的配置信息,但是需要用户能够忍受在机器出现故障时配置信息出现丢失。所以说 OG 的稳定行使用是依赖zookeeper 的。
而在 NG 版本中,节点角色的数量由 3 缩减到 1,不存在多类角色的问题,所以就不再需要 zookeeper 对各类节点协调的作用了,由此脱离了对 zookeeper 的依赖。由于 OG 的稳定使用对 zookeeper 的依赖表现在整个配置和使用过程中,这就要求用户掌握对 zookeeper 集群的搭建及其使用
OG 在安装时:在 flume-env.sh 中设置$JAVA_HOME。 需要配置文件 flume-conf.xml。其中最主要的、必须的配置与 master 有关。集群中的每个 Flume 都需要配置 master 相关属性(如 flume.master.servers、flume.master.store、flume.master.serverid)。 如果想稳定使用 Flume 集群,还需要安装 zookeeper 集群,这需要用户对 zookeeper 有较深入的了解。 安装 zookeeper 之后,需要配置 flume-conf.xml 中的相关属性,如 flume.master.zk.use.external、flume.master.zk.servers。 在使用 OG 版本传输数据之前,需要启动 master、agent。
NG 在安装时,只需要在 flume-env.sh 中设置$JAVA_HOME。
所以,当下我们使用Flume的时候,一般都采用Flume NG




