1. 概述
华为Fusion Insight是一个分布式数据处理系统,对外提供大容量的数据存储、查询和分析能力。Fusion Insight在Hadoop集群上又封装了一层,类似于开源的CDH,HDP等大数据平台。
2. Fusion Insight框架介绍
Fusion Insight 组成结构图
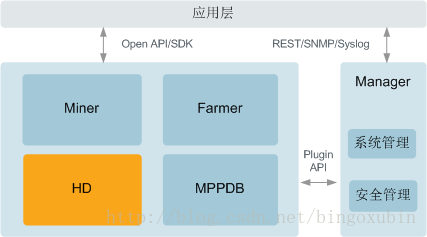
- Fusion Insight解决方案由4个子产品Fusion Insight HD、Fusion Insight MPPDB、Fusion Insight Miner、Fusion Insight Farmer和1个操作运维系统Fusion Insight Manager构成。
-
Fusion Insight HD:企业级的大数据处理环境,是一个分布式数据处理系统,对外提供大容量的数据存储、分析查询和实时流式数据处理分析能力。
Fusion Insight MPPDB:企业级的大规模并行处理关系型数据库。Fusion Insight MPPDB采用MPP(Massive Parallel Processing)架构,支持行存储和列存储,提供PB(Petabyte,2的50次方字节)级别数据量的处理能力。
Fusion Insight Miner:企业级的数据分析平台,基于华为Fusion Insight HD的分布式存储和并行计算技术,提供从海量数据中挖掘出价值信息的平台。
Fusion Insight Farmer:企业级的大数据应用容器,为企业业务提供统一开发、运行和管理的平台。
Fusion Insight Manager:企业级大数据的操作运维系统,提供高可靠、安全、容错、易用的集群管理能力,支持大规模集群的安装部署、监控、告警、用户管理、权限管理、审计、服务管理、健康检查、问题定位、升级和补丁等功能。
这次华为搭建的平台,可以描述为Fusion Insight HD,其他的子产品后续需要使用的话,需要另外搭建。
3. Fusion Insight HD架构概述
Fusion Insight HD系统逻辑架构图
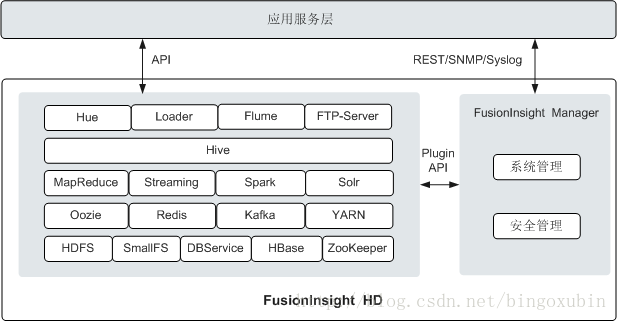
FusionInsight HD对开源组件进行封装和增强,包含Manager和众多组件,分别提供功能如下:
- Manager
作为运维系统,为Fusion Insight HD提供高可靠、安全、容错、易用的集群管理能力,支持大规模集群的安装部署、监控、告警、用户管理、权限管理、审计、服务管理、健康检查、问题定位、升级和补丁等。
- Hue
提供了Fusion Insight HD应用的图形化用户Web界面。Hue支持展示多种组件,目前支持HDFS、YARN、Hive和Solr。
Loader
实现Fusion Insight HD与关系型数据库、文件系统之间交换数据和文件的数据加载工具;同时提供REST API接口,供第三方调度平台调用。
- Flume
一个分布式、可靠和高可用的海量日志聚合系统,支持在系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写入各种数据接受方(可定制)的能力。
- FTP-Server
通过通用的FTP客户端、传输协议提供对HDFS文件系统进行基本的操作,例如:文件上传、文件下载、目录查看、目录创建、目录删除、文件权限修改等。
- Hive
建立在Hadoop基础上的开源的数据仓库,提供类似SQL的Hive Query Language语言操作结构化数据存储服务和基本的数据分析服务。
- MapReduce
提供快速并行处理大量数据的能力,是一种分布式数据处理模式和执行环境。
- Streaming
提供分布式、高性能、高可靠、容错的实时计算平台,可以为海量数据提供实时处理。CQL(Continuous Query Language)提供的类SQL流处理语言,可以快速进行业务开发,缩短业务上线时间。
- Spark
基于内存进行计算的分布式计算框架。
- Solr
一个高性能,基于Lucene的全文检索服务器。Solr对Lucene进行了扩展,提供了比Lucene更为丰富的查询语言,同时实现了可配置、可扩展,并对查询性能进行了优化,并且提供了一个完善的功能管理界面,是一款非常优秀的全文检索引擎。
- Oozie
提供了对开源Hadoop组件的任务编排、执行的功能。以Java Web应用程序的形式运行在Java servlet容器(如:Tomcat)中,并使用数据库来存储工作流定义、当前运行的工作流实例(含实例的状态和变量)。
- Redis
一个开源的、高性能的key-value分布式存储数据库,支持丰富的数据类型,弥补了memcached这类key-value存储的不足,满足实时的高并发需求。
- Kafka
一个分布式的、分区的、多副本的实时消息发布和订阅系统。提供可扩展、高吞吐、低延迟、高可靠的消息分发服务。
- YARN
资源管理系统,它是一个通用的资源模块,可以为各类应用程序进行资源管理和调度。
- HDFS
Hadoop分布式文件系统(Hadoop Distributed File System),提供高吞吐量的数据访问,适合大规模数据集方面的应用。
- SmallFS
提供小文件后台合并功能,能够自动发现系统中的小文件(通过文件大小阈值判断),在闲时进行合并,并把元数据存储到本地的LevelDB中,来降低NameNode压力,同时提供新的FileSystem接口,让用户能够透明的对这些小文件进行访问。
- DBService
一个具备高可靠性的传统关系型数据库,为Hive、Hue、Spark组件提供元数据存储服务。
- HBase
提供海量数据存储功能,是一种构建在HDFS之上的分布式、面向列的存储系统。
- ZooKeeper
提供分布式、高可用性的协调服务能力。帮助系统避免单点故障,从而建立可靠的应用程序。