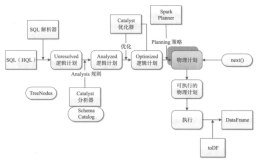
1.Spark 的四大组件下面哪个不是 (D )
A.Spark Streaming B Mlib
C Graphx D Spark R
2.下面哪个端口不是 spark 自带服务的端口 (C )
A.8080 B.4040 C.8090 D.18080
3.spark 1.4 版本的最大变化 (B )
A spark sql Release 版本 B 引入 Spark R
C DataFrame D支持动态资源分配
4.Spark Job 默认的调度模式 (A )
A FIFO B FAIR
C 无 D 运行时指定
5.哪个不是本地模式运行的个条件 ( D)
A spark.localExecution.enabled=true B 显式指定本地运行 C finalStage 无父 Stage D partition默认值
6.下面哪个不是 RDD 的特点 (C )
A. 可分区 B 可序列化 C 可修改 D 可持久化
7.关于广播变量,下面哪个是错误的 (D )
A 任何函数调用 B 是只读的 C 存储在各个节点 D 存储在磁盘或 HDFS
8.关于累加器,下面哪个是错误的 (D )
A 支持加法 B 支持数值类型
C 可并行 D 不支持自定义类型
9.Spark 支持的分布式部署方式中哪个是错误的 (D )
A standalone B spark on mesos
C spark on YARN D Spark on local
10.Stage 的 Task 的数量由什么决定 (A )
A Partition B Job C Stage D TaskScheduler
11.下面哪个操作是窄依赖 (B )
A join B filter
C group D sort
12.下面哪个操作肯定是宽依赖 (C )
A map B flatMap
C reduceByKey D sample
13.spark 的 master 和 worker 通过什么方式进行通信的? (D )
A http B nio C netty D Akka
14 默认的存储级别 (A )
A MEMORY_ONLY B MEMORY_ONLY_SER
C MEMORY_AND_DISK D MEMORY_AND_DISK_SER
15 spark.deploy.recoveryMode 不支持那种 (D )
A.ZooKeeper B. FileSystem
D NONE D Hadoop
16.下列哪个不是 RDD 的缓存方法 (C )
A persist() B Cache()
C Memory()
17.Task 运行在下来哪里个选项中 Executor 上的工作单元 (C )
A Driver program B. spark master
C.worker node D Cluster manager
18.hive 的元数据存储在 derby 和 MySQL 中有什么区别 (B )
A.没区别 B.多会话 C.支持网络环境 D数据库的区别
19.DataFrame 和 RDD 最大的区别 (B )
A.科学统计支持 B.多了 schema
C.存储方式不一样 D.外部数据源支持
20.Master 的 ElectedLeader 事件后做了哪些操作 (D )
A. 通知 driver B.通知 worker
C.注册 application D.直接 ALIVE
答案:
DCBAD CDDDA
BCDAD CCBBD