丰富的线上&线下活动,深入探索云世界
做任务,得社区积分和周边
资深技术专家手把手带教
技术交流,直击现场
让创作激发创新
海量开发者使用工具、手册,免费下载
极速、全面、稳定、安全的开源镜像
开发手册、白皮书、案例集等实战精华
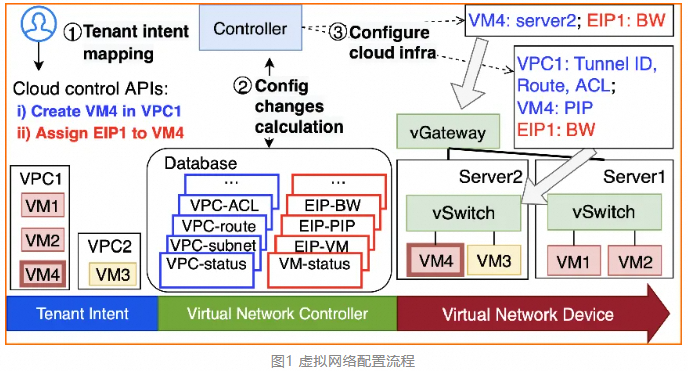
NSDI'24 | 阿里云飞天洛神云网络论文解读——《Poseidon》揭秘新型超高性能云网络控制器
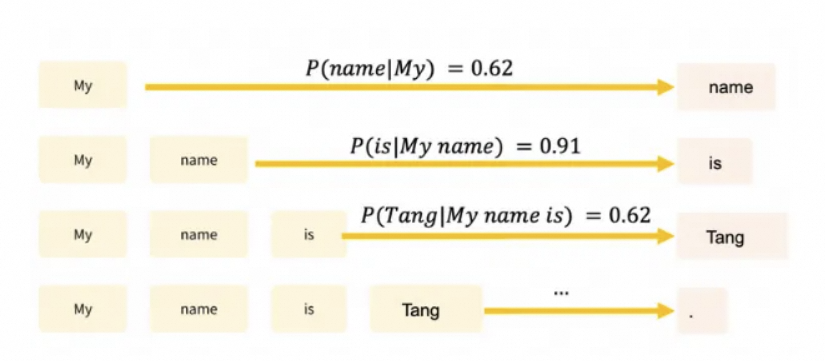
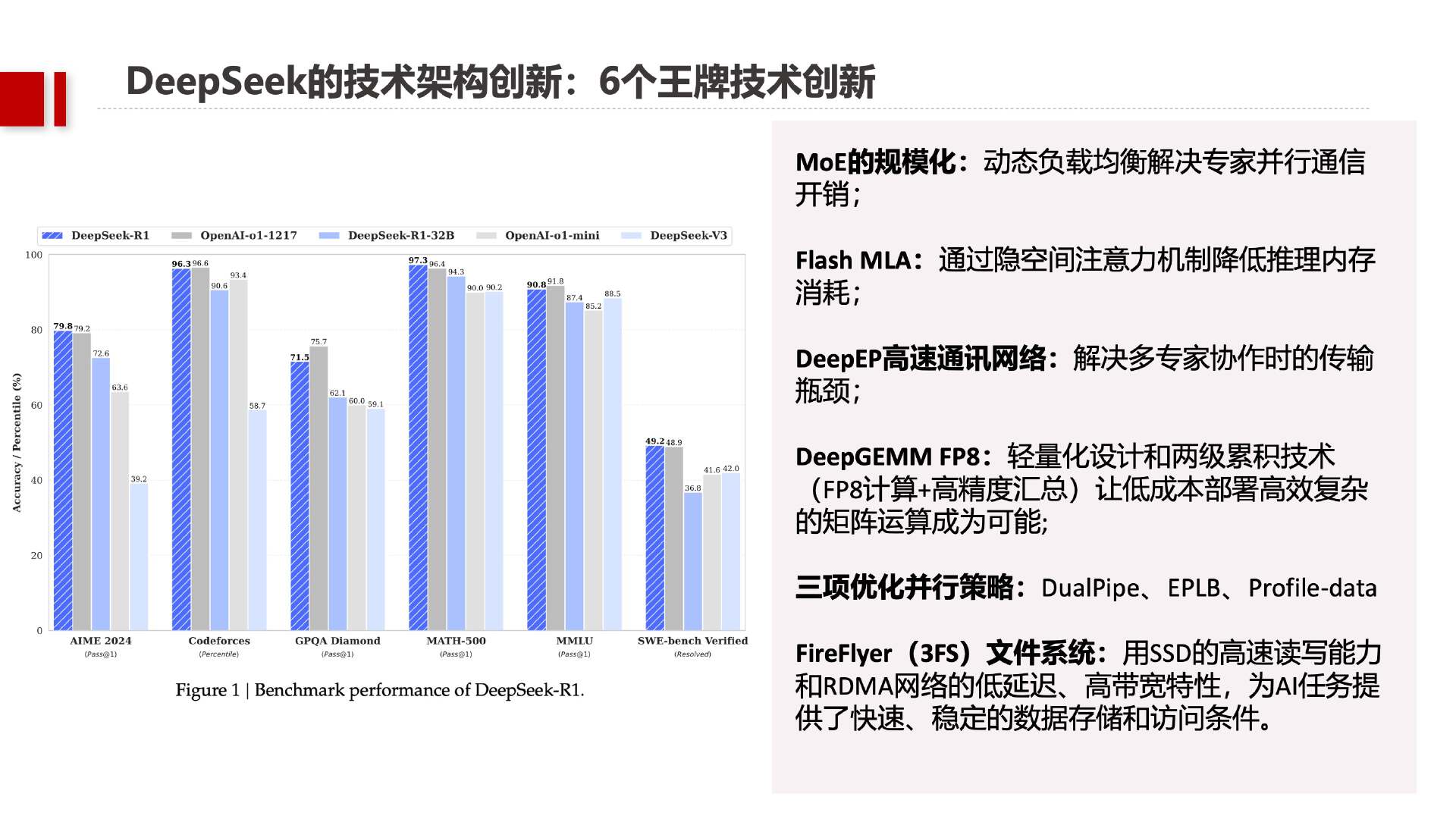
一篇关于DeepSeek模型先进性的阅读理解
一招解决数据库中报表查询慢的痛点
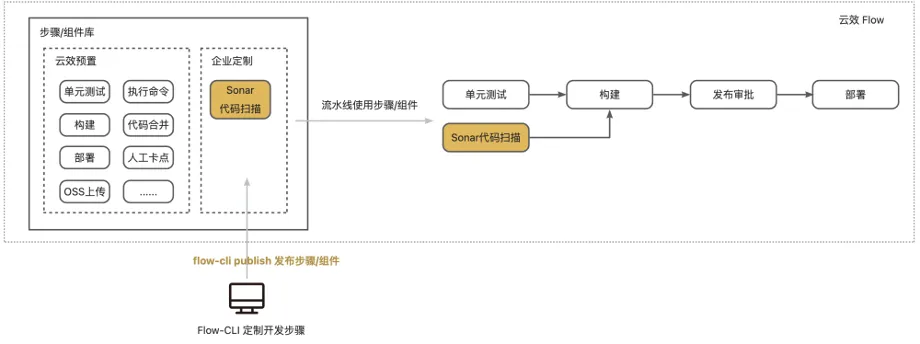
Flow-CLI 全新升级,轻松对接 Sonar 实现代码扫描和红线卡点
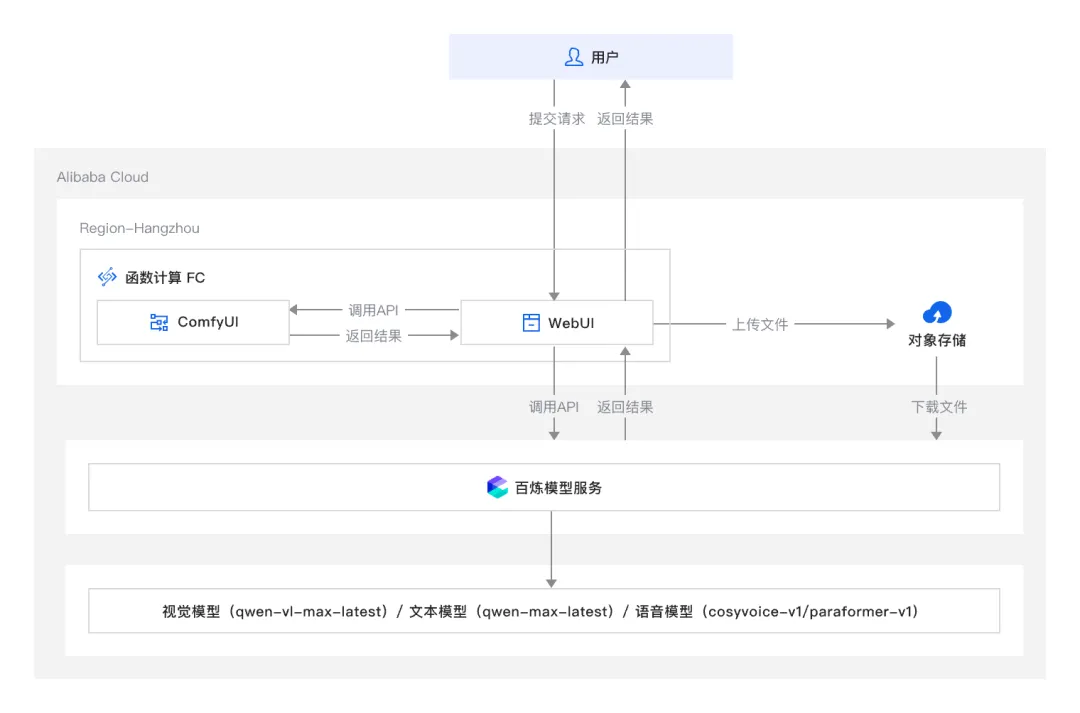
AI 短剧遇上函数计算,一键搭建内容创意平台
海外泼天流量|浅谈全球化技术架构
云端问道18期实践教学-AI 浪潮下的数据安全管理实践
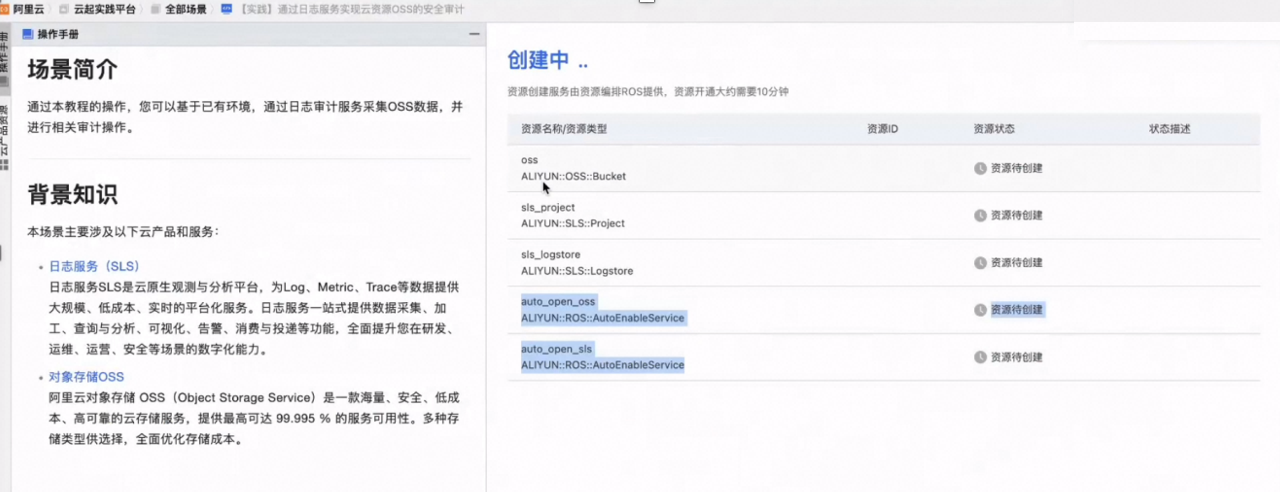
网络安全视角:从地域到账号的阿里云日志审计实践
云端问道11期实践教学-创建专属AI助手
OpenAI故障复盘 - 阿里云容器服务与可观测产品如何保障大规模K8s集群稳定性
探索大型语言模型LLM推理全阶段的JSON格式输出限制方法
高弹性、低成本的云消息队列RabbitMQ 版
体验云数据库RDS通用云盘核心能力
云端问道9期方案教学
10 分钟打造你的专属 AI 客服
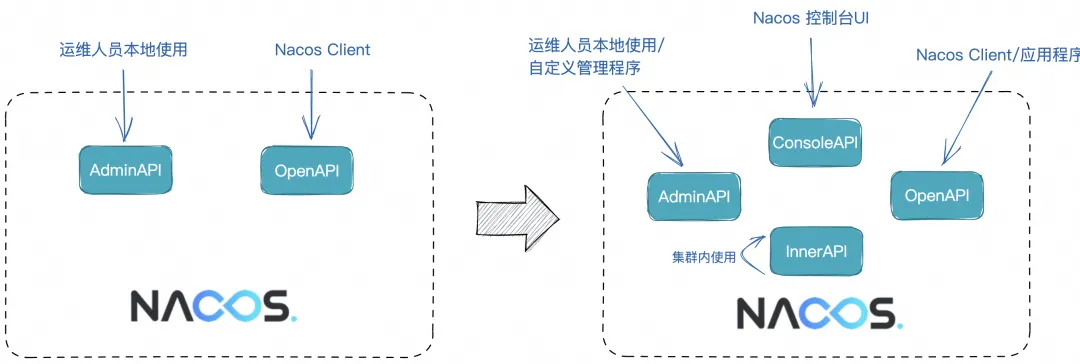
Nacos 3.0 Alpha 发布,在安全、泛用、云原生更进一步
SpringCloud 应用 Nacos 配置中心注解
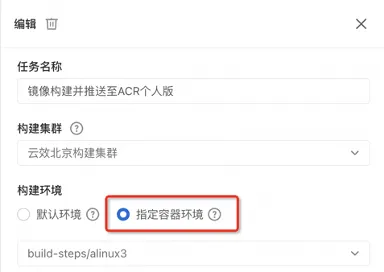
更快、更灵活、场景更丰富,云效镜像构建能力升级啦
阿里云“山海计划”:基于UE引擎的“中国特色”城市场景AIGC方案
C5GAME 游戏饰品交易平台借助 RocketMQ Serverless 保障千万级玩家流畅体验
【全览篇】解锁AllData数据中台商业版能力演示
DB-GPT V0.7.0版本更新:支持MCP协议、集成DeepSeek R1模型、GraphRAG检索链路增强、架构全面升级等
服务器数据恢复—Raid5磁盘阵列数据恢复案例
ReasonGraph:别让AI成黑箱!这个开源工具把大模型的脑回路画给你看
LHM:单图生成3D动画人!阿里开源建模核弹,高斯点云重构服装纹理
Qwen2.5-VL-32B:阿里开源多模态核弹!32B模型吊打自家72B,数学推理封神
StarVector:图像秒变矢量代码!开源多模态模型让SVG生成告别手绘
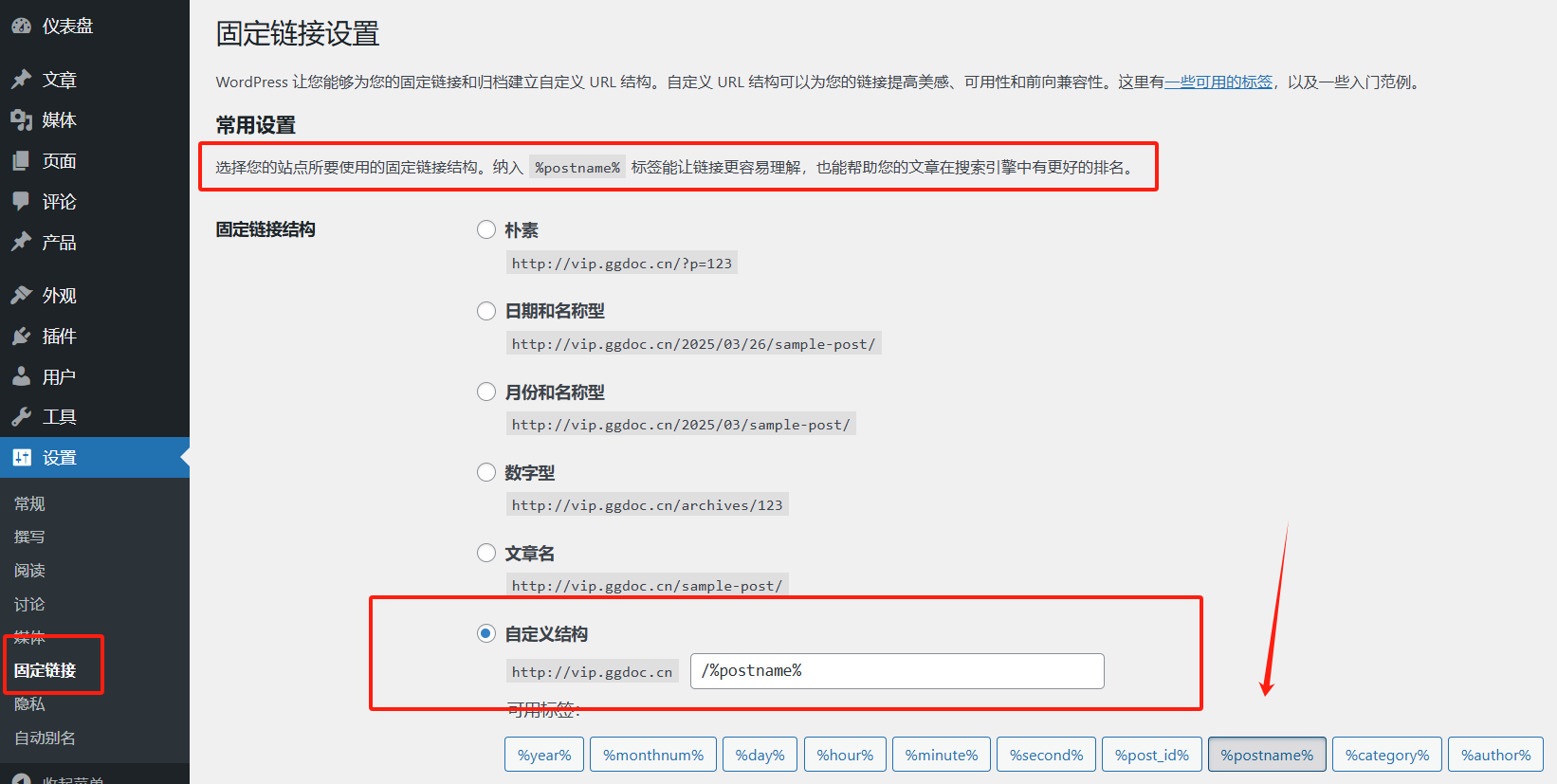
WordPress上 好用的自动别名插件
Qwen2.5-VL-32B: 更聪明、更轻量!
G1原理—4.G1垃圾回收的过程之Young GC
DeepSeek-V3小版本升级,非推理模型王者归来
今日论文推荐:MAPS、RoboFactory、OpenVLThinker等
Android调试终极指南:ADB安装+多设备连接+ANR日志抓取全流程解析,覆盖环境变量配置/多设备调试/ANR日志分析全流程,附Win/Mac/Linux三平台解决方案
鸿蒙开发:单一手势实现多次点击事件
17.1K star!两小时就能训练出专属与自己的个性化小模型,这个开源项目让AI触手可及!
企业内训|DeepSeek技术革命、算力范式重构与场景落地洞察-某头部券商
【赵渝强老师】Oracle数据库的客户端工具
AI第三极之争:生成式人工智能(GAI)认证如何重塑青年竞争力与时代担当
AI浪潮下的青年觉醒:生成式人工智能(GAI)认证赋能未来竞争力与人文担当
智能数据建设与治理 Dataphin 评测报告
自学能力与生成式人工智能(GAI)认证:解锁未来竞争力的教育密码
“人工智能+”新赛道与生成式人工智能(GAI)认证:驱动未来竞争力的双引擎
聚势赋能:“人工智能+”激活高质量发展动能与生成式人工智能(GAI)认证的新机遇
AI赋能:高质量发展新引擎与生成式人工智能(GAI)认证的兴起
中国AI崛起与生成式人工智能(GAI)认证:驱动全球科技变革的人才战略
从“人才数量红利”到“技能质量突围”:中国AI的认证进化论
网站建设有什么方法?
云上部署WoSign SSL“国密RSA双证书”,助力国密合规建设
阿里云连续两年入选沙利文中国企业出海云服务市场领导者梯队
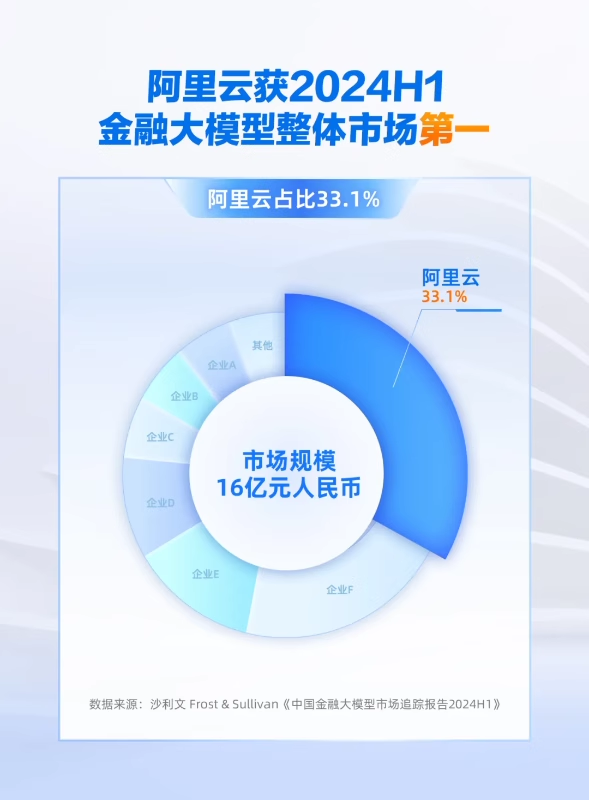
阿里云中国金融大模型整体市场第一
社区积分兑好礼