List 列表
(1) List 是 Collection 的子接口
特点:有序 (存储顺序和取出顺序一致 ),可重复。
(2) List 的特有功能:
A:添加功能
void add(int index,Object element) :在指定位置添加元素B:删除功能
Object get(int index): 获取指定位置的元素
C:获取功能
ListIterator listIterator() : List 集合特有的迭代器
D:迭代器功能
Object remove(int index) :根据索引删除元素 ,返回被删除的元素E:修改功能
Object set(int index,Object element) :根据索引修改元素,返回被修
饰的元素
(3) List 集合的特有遍历功能
A:由 size()和 get()结合。
B:代码演示
List list =newArrayList(); // 创建集合对象
list.add('hello');
list.add('world');
list.add('Java'); // 创建并添加元素
Iterator it = list.iterator();
while (it.hasNext()) {
String s =(String) it.next();
System. out .println(s);
}
System. out .println("----------");
for( int x=0; x<list.size(); x++)
{ String s =(String) list.get(x);
System. out .println(s);
}1.列表迭代器的特有功能
可以逆向遍历,但是要先正向遍历,所以无意义,基本不使用。
2.并发修改异常
A:出现的现象
迭代器遍历集合,集合修改集合元素
B:原因
迭代器是依赖于集合的,而集合的改变迭代器并不知道。
C:解决方案
a:迭代器遍历,迭代器修改 (ListIterator)
元素添加在刚才迭代的位置
b: 集合遍历,集合修改 (size() 和 get())
元素添加在集合的末尾
3.常见数据结构
A:栈先进后出
B:队列先进先出
C:数组查询快,增删慢
D:链表查询慢,增删快
4. List 的子类特点 ( 面试题 )
ArrayList
底层数据结构是数组,查询快,增删慢。线程不安全,效率高。
Vector
底层数据结构是数组,查询快,增删慢。线程安全,效率低。
LinkedList
底层数据结构是链表,查询慢,增删快。线程不安全,效率高。
如何使用
分析:
要安全吗 ?
要: Vector( 即使要,也不使用这个 )
List<String> list2 = Collections.synchronizedList(new ArrayList<String>())
不要: ArrayList 或者 LinkedList
查询多; ArrayList 增删多: LinkedList
(什么都不知道,就用 ArrayList)
(5) LinkedList 的特有功能:
A:添加功能
public void addFirst(Object e) public void addLast(Object e)
B:获取功能
public Object getFirst() public Obejct getLast()
C:删除功能
public Object removeFirst() public Object removeLast()
Set 集合
1.Set 集合的特点
无序 ,唯一
2.HashSet 集合
A:底层数据结构是哈希表 (是一个元素为链表的数组 )
B:哈希表底层依赖两个方法: hashCode() 和 equals() 执行顺序:
首先比较哈希值是否相同
相同:继续执行 equals()方法
返回 true :元素重复了,不添加返回 false:直接把元素添加到集合
不同:就直接把元素添加到集合
C:如何保证元素 唯一性 ?
由 hashCode()和 equals() 保证的
D:开发的时候,代码非常的简单,自动生成即可。
E:HashSet存储字符串并遍历
F:HashSet存储自定义对象并遍历 (对象的成员变量值相同即为同一个元素 )
3.TreeSet 集 合
能够对元素按照某种规则进行排序。
TreeSet 集合的特点:排序和唯一排序有两种方式
A:自然排序
B:比较器排序
A:底层数据结构是红黑树 (是一个自平衡的二叉树 )
B:保证元素的排序方式
a:自然排序 (元素具备比较性 )
让元素所属的类实现 Comparable 接口
@Override
publicint compareTo(Student s) {
// return 0;
// return 1;
// return -1;
这里返回什么,其实应该根据我的排序规则来做
按照年龄排序
int num = this .age-s.age; //主要条件
//年龄相同的时候,还得去看姓名是否也相同
//如果年龄和姓名都相同,才是同一个元素
int num2 = num == 0; //次要条件
this.name.compareTo(s.name) : num;
return num2;
}次要条件
//年龄相同的时候,还得去看姓名是否也相同
//如果年龄和姓名都相同,才是同一个元素
int num2 = num == 0; //次要条件
this.name.compareTo(s.name) : num;
return num2;
}b: 比较器排序 (集合具备比较性 )
让集合构造方法接收 Comparator 的实现类对象
代码:
TreeSet<Student> ts = newTreeSet <Student>(newComparator<Student>(){
@Override
publicint compare(Student s1, Student s2) {
// 姓名长度
int num = s1.getName().length() - s2.getName().length();
// 姓名内容
int num2 = num == 0 ? s1.getName().compareTo(s2.getName())
: num;
// 年龄
int num3 = num2 == 0 ? s1.getAge() - s2.getAge() : num2; return num3;
}
4.LinkedHashSet
底层数据结构由哈希表和链表组成。
哈希表保证元素的唯一性。
链表保证元素有序。 (存储和取出是一致 )
泛型(一般是在集合中使用)
(1)泛型概述
是一种把明确类型的工作推迟到创建对象或者调用方法的时候才去明确的特殊的类型。
(2)格式:
<数据类型 >
注意:该数据类型只能是引用类型。
(3)好处:
A:把运行时期的问题提前到了编译期间 B:避免了强制类型转换
C:优化了程序设计,解决了黄色警告线问题,让程序更安全
(4)泛型的前世今生
A:泛型的由来
Object 类型作为任意类型的时候,在向下转型的时候,会隐含一个转型问题
B:泛型类
C:泛型方法
D:泛型接口
E:泛型高级通配符
? extends E
? super E
//泛型如果明确的写的时候,前后必须一致
Collection<Object> c1 =new ArrayList<Object>();
// Collection<Object> c2 = new ArrayList<Animal>();
// Collection<Object> c3 = new ArrayList<Dog>();
// Collection<Object> c4 = new ArrayList<Cat>();
// ? 表示任意的类型都是可以的
Collection<?> c5 =new ArrayList<Object>();
Collection<?> c6 = new ArrayList<Animal>();
Collection<?> c7 =new ArrayList<Dog>();
Collection<?> c8 =new ArrayList<Cat>();

Map
(1)Map:是一种集合、一个接口;可以一对一对往里放数据,map中的数据是有关联关系的,以键值对的形式组织映射关系
Map 特点
* 1:存放的是键值对(夫妻对)
* 2:键是无序的不能重复(Set)
* 3:值是可以重复的(List)
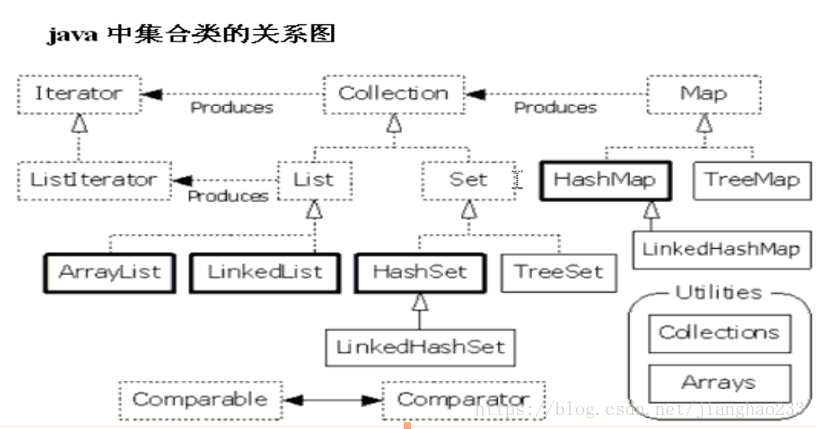
Map 和 Collection 的区别 ?
A:Map 存储的是键值对形式的元素,键唯一,值可以重复。夫妻对
B:Collection 存储的是单独出现的元素, 子接口 Set 元素唯一, 子接口 List 元素可重复。光棍
Map 接口功能概述
A:添加功能
V put(K key,V value) :添加元素。
如果键是第一次存储,就直接存储元素,返回 null
如果键不是第一次存在,就用值把以前的值替换掉,返回以前的值
B:删除功能
void clear() :移除所有的键值对元素
V remove(Object key) :根据键删除键值对元素,并把值返回
C:判断功能
boolean containsKey(Object key) :判断集合是否包含指定的键
boolean containsValue(Object value): 判断集合是否包含指定的值
boolean isEmpty() :判断集合是否为空
D:获取功能
Set<Map.Entry<K,V>> entrySet(): 获取所有键值对集合
V get(Object key) :根据键获取值
Set<K> keySet(): 获取集合中所有键的集合
Collection<V> values() :获取集合中所有值的集合E:长度功能
int size() :返回集合中的键值对的对数(map 的长度)
示例:
public class MapDemo {
public static void main(String[] args) {
Map<String,String> map = new HashMap<String,String>();
String value = map.put("杨过", "小龙女");
System.out.println(value);
/*value = map.put("杨过", "黄蓉");
System.out.println(value);*/
map.put("郭靖", "黄蓉");
// map.put("杨过", "黄蓉");
map.put("段誉", "王语嫣");
Set<Entry<String, String>> entrySet = map.entrySet();
for(Entry<String, String> entry : entrySet){
String key = entry.getKey();
String value2 = entry.getValue();
System.out.println("key:" + key + ",value:" + value2);
}
Set<String> keySet = map.keySet();
for(String key : keySet){
String value3 = map.get(key);
System.out.println("key:" + key + ",value:" + value3);
}
输出:

2.Map 集合的遍历
A:键找值
a:获取所有键的集合
b: 遍历键的集合 ,得到每一个键c:根据键到集合中去找值
B:键值对对象找键和值
a:获取所有的键值对对象的集合
b: 遍历键值对对象的集合,获取每一个键值对对象c:根据键值对对象去获取键和值
代码体现:

问题:
1:Hashtable 和 HashMap 的区别 ?
- Hashtable: 线程安全,效率低。不允许 null 键 和 null 值
- HashMap: 线程不安全,效率高。允许 null 键 和 null 值
- LinkedHashMap 可以保证存储顺序与取出顺序一致
2.TreeMap :可排序 A:TreeMap<String,String> B:TreeMap<Student,String>
示例:
package com.hd.map;
import java.util.HashMap;
import java.util.HashSet;
import java.util.Map;
import java.util.Map.Entry;
import java.util.Set;
public class MapDemo2 {
public static void main(String[] args) {
MyMap<String,Integer> myMap = new MyMap<>();
myMap.put("数学", 150);
myMap.put("语文", 149);
myMap.put("英语", 151);
myMap.put("理综", 300);
Set<MyMap.Entry<String,Integer>> entrySet = myMap.entrySet();
for(MyMap.Entry<String,Integer> entry : entrySet){
String key = entry.getKey();
Integer value = entry.getValue();
System.out.println("key:" + key + ",value:" + value);
}
}
}
class MyMap<K,V>{
private Map<K,V> map = new HashMap<K,V>(); //泛型
public void put(K key,V value){
map.put(key, value);
}
public Set<Entry<K,V>> entrySet(){
Set<Entry<K,V>> set = new HashSet<Entry<K,V>>();
Set<K> keySet = map.keySet();
for(K key : keySet){
V value = map.get(key);
Entry<K,V> entry = new Entry<K,V>();
entry.setKey(key);
entry.setValue(value);
set.add(entry);
}
return set;
}
public static class Entry<K,V>{
private K key;
private V value;
public K getKey() {
return key;
}
public V getValue() {
return value;
}
public void setKey(K key) {
this.key = key;
}
public void setValue(V value) {
this.value = value;
}
}
}
输出: