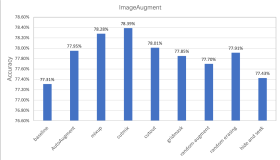
3D面部重建是一个非常困难的基本计算机视觉问题。目前的系统通常假设多个面部图像(有时来自同一主题)作为输入的可用性,并且必须解决许多方法学挑战,例如在大的面部姿势,表情和不均匀照明之间建立密集的对应。一般来说,这些方法需要复杂和低效的管道来建模和拟合。在这项工作中,我们提出通过在由2D图像和3D面部模型或扫描组成的适当数据集上训练卷积神经网络(CNN)来解决许多这些限制。我们的CNN只使用一个2D面部图像,不需要精确的对准,也不会形成图像之间的密集对应,适用于任意面部姿势和表情,并可用于重建整个3D面部几何(包括不可见部分(在训练期间)和拟合(测试期间)3D变形模型。我们通过一个简单的CNN架构来实现这一点,该架构对单个2D图像的3D面部几何体的体积表示进行直接回归。我们还展示了如何将面部地标定位的相关任务纳入拟议的框架,并有助于提高重建质量,特别是对于大姿势和面部表情的情况。
3D face reconstruction is a fundamental Computer Vision problem of extraordinary difficulty. Current systems often assume the availability of multiple facial images (sometimes from the same subject) as input, and must address a number of methodological challenges such as establishing dense correspondences across large facial poses, expressions, and non-uniform illumination. In general these methods require complex and inefficient pipelines for model building and fitting. In this work, we propose to address many of these limitations by training a Convolutional Neural Network (CNN) on an appropriate dataset consisting of 2D images and 3D facial models or scans. Our CNN works with just a single 2D facial image, does not require accurate alignment nor establishes dense correspondence between images, works for arbitrary facial poses and expressions, and can be used to reconstruct the whole 3D facial geometry (including the non-visible parts of the face) bypassing the construction (during training) and fitting (during testing) of a 3D Morphable Model. We achieve this via a simple CNN architecture that performs direct regression of a volumetric representation of the 3D facial geometry from a single 2D image. We also demonstrate how the related task of facial landmark localization can be incorporated into the proposed framework and help improve reconstruction quality, especially for the cases of large poses and facial expressions.
项目地址:https://github.com/AaronJackson/vrn
更多人工智能教程:http://www.buluo360.com