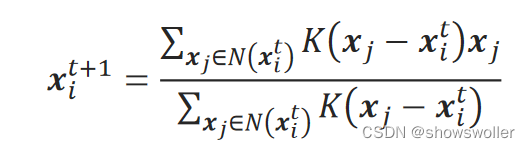Machine Learning
聚类的过程是将样本分类的过程,聚类属于无监督学习,资料中没有label,训练之前并不知道样本属于哪一个类别,需要借鉴经验值。
Kmeans聚类:
模型假设:数据的分布是K个$\sigma$相同的高斯分布的,每个分布里有$N_1,N_2,......N_k$个样本,其均值分别是$mu_1,mu_2,……mu_k$,那么每个样本属于自己对应那个簇的似然概率为:
$$ L = \prod_{j=1}^{K}\prod_{i=1}^{N_{j}}\frac{1}{2\sigma ^{2}}exp(-\frac{\left | \left | x_{i}-\mu _j \right | \right |^{2}}{2\sigma ^{2}}) $$
做对数变化,并取负值即可得到损失函数:
$$ J(\mu_1,\mu_2,...,\mu_K)= \frac{1}{2}\sum _{j=1}^{K}\sum _{i=1}^{N_{j}}(x_{i}-\mu_j)^{2} $$
损失函数求导得:
$$ \frac{\partial J}{\partial \mu_j} = \sum _{i=1}^{N_j}(x_j-\mu_j) =0 $$
即更新后最佳簇的中心为:
$$ \mu_j = \frac{\sum_{i=1}^{N_j}x_i}{N_j} $$
迭代过程
2.1.需要指定K值,需要得到簇的个数;
2.Kmeans 会随机给出K个质心;
3.开始迭代,根据距离计算新质心的位置;
4.质心的位置不发生变化,即迭代停止。
缺点:
- K值难确定
- 复杂度与样本呈线性关系
- 很难发现任意形状的簇
Kmeans聚类可视化
https://www.naftaliharris.com/blog/visualizing-k-means-clustering/
DBSCAN聚类:
基本概念 Density-Based Spatial Clustering of Applications with Noise
- 核心对象:若某个点的密度达到算法设定的阈值则其为核心点。(即r领域内点的数量不小于minPts)
- 邻域的距离阈值:设定的半径r
- 直接密度可达:若某点p在点q的r邻域内,且q是核心点则p-q 直接密度可达。
- 密度可达:若有一个点的序列$q_0,q_1,...,q_k$,对$q_i-q_{i-1}$是直接密度可达的,则称从$q_0到q_k$密度可达,这实际上是直接密度可达的"传播"。
- 密度相连:若从某核心点p出发,点q和点k都是密度
DBSCAN的算法就是我们先找到一个核心对象,从它出发,确定若干个直接密度可达的对象,再从这若干个对象出发,寻找它们直接密度可达的点,直至最后没有可添加的对象了,那么一个簇的更新就完成了。我们也可以说,簇其实就是所有密度可达的点的集合。
1.先找到一个核心对象,从它出发,确定若干个直接密度可达的对象
2.再从这若干个对象出发,寻找它们直接密度可达的点,直到最后没有可添加的对象
3.完成一个簇
DBSCAN聚类可视化:
https://www.naftaliharris.com/blog/visualizing-dbscan-clustering/
缺点:
- 高维数据有些困难
- 参数难以选择
- Sklearn中效率很慢
层次聚类
最初将每个对象看成一个簇,然后将这些簇根据某种规则被一步步合并,就这样不断合并直到达到预设的簇类个数。
合并规则:
- 最小距离:两个簇的样本对之间距离的最小值$d_min$「single-linkage算法」
- 最大距离:两个簇的样本对之间距离的最大值$d_max$「complete-linkage算法」
- 平均距离:两个簇的样本对之间距离的平均值$d_avg$「average-linkage算法」
其他聚类算法待学习,补充「未完待续」
参考资料:
https://blog.csdn.net/sinat_22594309/article/details/63253459
唐宇迪「机器学习课程」