神经网络和深度学习技术是当今大多数高级智能应用的基础。在本文,来自阿里巴巴搜索部门的高级算法专家孙飞博士将简要介绍神经网络的演变,并讨论该领域的最新发展。本文主要围绕以下五个方面:
- 神经网络的演化;
- 感知机模型;
- 前馈神经网络;
- 反向传播;
- 深度学习基础知识;
1.神经网络的演变
在我们深入研究神经网络的历史发展之前,让我们首先介绍神经网络的概念。神经网络主要是一种计算模型,它以简化的水平模拟人类大脑的运作。这种类型的模型使用大量计算神经元,这些神经元通过加权连接层连接。每层神经元都能够执行大规模并行计算并在它们之间传递信息。
下面的时间表显示了神经网络的演变:
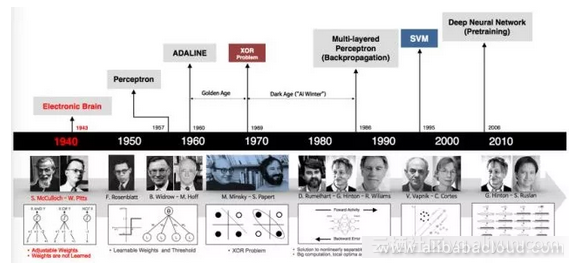
神经网络的起源甚至可以追溯到计算机本身的发展之前,第一个神经网络出现在20世纪40年代。本文将通过一些历史来帮助每个人更好地理解神经网络的基础知识。
第一代神经网络神经元作为验证者:这些神经元的设计者只是想确认他们可以构建用于计算的神经网络。但,这些网络不能用于训练或学习,它们只是充当逻辑门电路。它们的输入和输出是二进制的,权重是预定义的。
神经网络发展的第二阶段发生在20世纪50年代和60年代:这涉及Roseblatt关于感知机模型的开创性工作和Herbert关于学习原理的工作。
2.感知机模型
我们上面提到的感知机模型和神经元模型相似但有一些关键差异。感知机模型中的激活算法可以是中断算法或S形算法,并且其输入可以是实数向量而不是神经元模型使用的二进制向量。与神经元模型不同,感知机模型能够学习。接下来,我们将讨论感知机模型的一些特殊特性。
我们可以将输入值(x1...xn)视为N维空间中的坐标,而wTx-w0=0是N维空间中的超平面。显然,如果wTx-w0<0,则该点低于超平面,而如果wTx-w0> 0,则该点落在超平面之上。
感知机模型对应于分类器的超平面,并且能够分离N维空间中的不同类型的点。看下图,我们可以看到感知机模型是线性分类器:

感知机模型能够轻松地对AND,OR和NOT等基本逻辑运算进行分类。
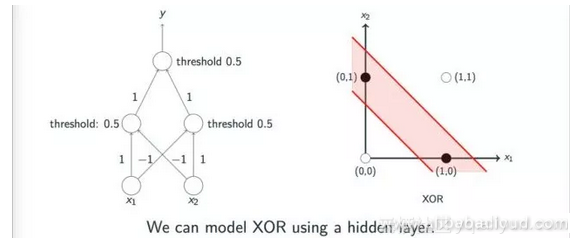
我们可以通过感知机模型对所有逻辑运算进行分类吗?答案当然不是。例如,通过单个线性感知机模型很难对异或运算进行分类,这是神经网络在第一个峰值之后很快进入开发的低点的主要原因之一。包括明斯基在内的一些大牛就感知机模型的主题讨论了这个问题。然而,很多人在这个问题上误解了作者。
实际上,像明斯基这样的作者指出,可以通过多层感知机模型实现异或运算;然而,由于学术界缺乏有效的方法来研究当时的多层感知机模型,神经网络的发展已经进入了第一个低点。
下图直观地显示了多层感知机模型如何实现异或操作:
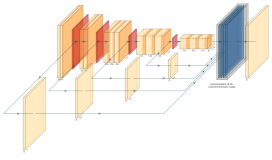
3.前馈神经网络
进入20世纪80年代,由于感知机模型神经网络的表达能力局限于线性分类任务,神经网络的发展开始进入多层感知机阶段。而经典的多层神经网络是前馈神经网络。
从下图中可以看出,它涉及输入层,具有未定义数量的节点的隐藏层和输出层。
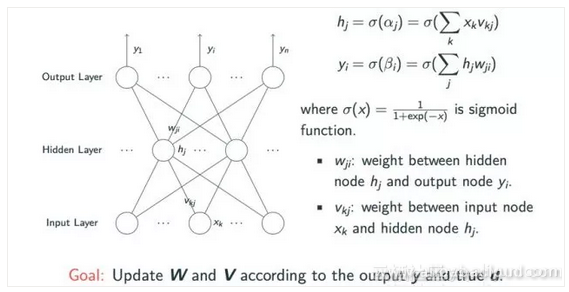
我们可以通过多层感知机模型表达任何逻辑运算,但这引入了三层之间的加权学习问题。当xk从输入层传输到隐藏层上的加权vkj,然后通过像sigmoid这样的激活算法时,我们可以从隐藏层中检索相应的值hj。同样,我们可以使用类似的操作使用hj值从输出层导出yi节点值。为了学习,我们需要来自w和v矩阵的加权信息,以便我们最终可以获得估计值y和实际值d。
如果你对机器学习有基本的了解,你就会明白为什么我们使用梯度下降来学习模型。将梯度下降应用于感知机模型的原理相当简单,如下图所示。首先,我们必须确定模型的损失。
该示例使用平方根损失并寻求缩小模拟值y与实际值d之间的差距。为了方便计算,在大多数情况下,我们使用根关系E=1/2(dy)^2 = 1/2(df(x))^2。
根据梯度下降原理,加权更新周期的比率为:wj←wi+α(d-f(x))f'(x)xi,其中α是我们可以手动调整的学习率。

4.反向传播
我们如何学习多层前馈神经网络中的所有参数?顶层的参数非常容易获得,我们可以通过比较计算模型输出的估计值和实际值之间的差异并使用梯度下降原理来获得参数结果来实现参数。当我们尝试从隐藏层获取参数时,问题出现了。即使我们可以计算模型的输出,我们也无法知道预期值是什么,因此我们无法有效地训练多层神经网络。这个问题长期困扰着研究人员,它导致20世纪60年代以后神经网络的发展不足。
后来,在70年代,科学家独立地引入了反向传播算法的想法。这种算法背后的基本思想实际上非常简单,即使当时没有办法根据隐藏层的预期值进行更新,也可以通过从隐藏层传递的错误来更新隐藏层和其他层之间的权重。在计算梯度时,由于隐藏层中的所有节点都与输出层上的多个节点相关,因此前一层上的所有层都被累积并一起处理。
反向传播的另一个优点是我们可以同时对同一层上的节点执行梯度和加权,因为它们是不相关的。我们可以用伪代码表示反向传播的整个过程如下:

接下来,我们来谈谈反向传播神经网络的一些其他特性。反向传播实际上是一个链规则,它可以很容易地推广任何具有映射的计算。根据梯度函数,我们可以使用反向传播神经网络来生成局部优化解决方案,但不是全局优化解决方案。然而,从一般的角度来看,反向传播算法产生的结果通常是令人满意的优化解决方案。下图是反向传播算法的直观表示:
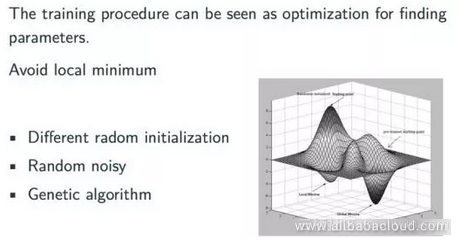
在大多数情况下,反向传播神经网络将在范围内找到最小的可能值;但是,如果我们离开那个范围,我们可能会发现更好的价值。在实际应用中,有许多简单有效的方法可以解决这类问题,例如,我们可以尝试不同的随机初始化方法。而且,在实践中,在现代深度学习领域中经常使用的模型中,初始化方法对最终结果具有显着影响。迫使模型离开优化范围的另一种方法是在训练期间引入随机噪声或使用遗传算法来防止训练模型停止在非理想的优化位置。
反向传播神经网络是一种优秀的机器学习模型,在谈到机器学习时,我们不禁注意到机器学习过程中经常遇到的基本问题,即过度拟合的问题。过度拟合的一个常见表现是,在训练期间,即使模型的损失不断下降,测试组中的损失和错误也会增加。有两种典型方法可以避免过度拟合:
- 提前停止:我们可以提前分离验证组,并在训练期间针对此已经验证的组进行运行。然后我们可以观察到模型的损失,如果损失已经在验证组中停止但仍然在训练组中下降,那么我们可以提前停止训练以防止过度拟合。
- 正则化:我们可以在神经网络中为权重添加规则。目前流行的dropout方法涉及随机丢弃一些节点或侧面。我们可以将这种方法视为正则化的一种形式,在防止过度拟合方面非常有效。
尽管神经网络在20世纪80年代非常流行,但不幸的是,它们在20世纪90年代进入了发展的另一个低谷。许多因素促成了这一低估区。例如,支持向量机,它是20世纪90年代的流行模型,在各种主要会议上登台亮相,并在各种领域得到应用。支持向量机具有出色的统计学习理论,易于直观理解。它们也非常有效并产生近乎理想的结果。
在这种转变中,支持向量机背后的统计学习理论的兴起对神经网络的发展施加了不小的压力。另一方面,从神经网络本身的角度来看,即使你可以使用反向传播网络在理论上训练任何神经网络,在实际应用中,我们注意到随着神经网络中层数的增加,难度训练网络成倍增长。例如,在20世纪90年代初,人们注意到在具有相对大量层的神经网络中,通常会看到梯度损失或梯度爆炸。
例如,梯度损失的一个简单例子是神经网络中的每个层都是S形结构层,因此在反向传播期间它的损失被链接成S形梯度。当一系列元素串在一起时,如果其中一个渐变非常小,则渐变将变得越来越小。实际上,在传播一层或两层之后,该梯度消失。梯度损失导致深层中的参数停止变化,使得很难获得有意义的结果。这是多层神经网络很难训练的原因之一。
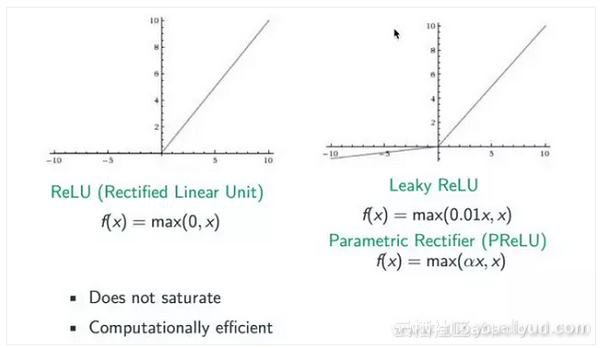
学术界已经深入研究了这个问题,并得出结论,处理它的最简单方法是改变激活算法。在开始时,我们尝试使用整流激活算法,因为S形算法是一种索引方法,很容易引起梯度损失问题。另一方面,整流取代了sigmoid函数并替换了max(0,x)。从下图中我们可以看出,估计值大于0的梯度为1,这可以防止梯度消失的问题。但是,当估计值低于0时,我们可以看到梯度再次为0,因此ReLU算法必须是不完美的。后来,出现了许多改进的算法,包括Leaky ReLU和Parametric Rectifier(PReLU)。当估计x小于0时,我们可以将其转换为类似0的系数。
随着神经网络的发展,我们后来提出了许多方法来解决在结构层面上传递梯度的问题。例如,Metamodel、LSTM模型和现代图像分析使用多种跨层链接方法来更容易地传播渐变。
请继续关注本文的第二部分。
以上为译文。
本文由阿里云云栖社区组织翻译。
文章原标题《all-you-need-to-know-about-neural-networks-part-1》,
作者:Leona Zhang 译者:虎说八道,审校:。
文章为简译,更为详细的内容,请查看原文。