去年做过一个项目,需要每日对上千个Android内存泄漏(OOM)时core dump出的hprof文件进行分析,希望借助海量数据来快速定位内存泄漏的原因。最终的分析结果是一个类森林,因为时隔较远,只找到下面这个截图了。

点击打开折叠的项目,会看到该类的每个属性,类有多少个实例,占用的大小等等信息,树的深度可以达到10^2级别。重点是项目需要实时,每个hprof文件解析出来的节点达到5w+,千万级节点已经由mapreduce进行过一次汇聚计算才出库,在展示时,依然需要一次实时计算,当点击项目时,需要快速将该类下所有的子孙节点占用的字节大小累加到该节点,因此对森林要有很高的查询效率。
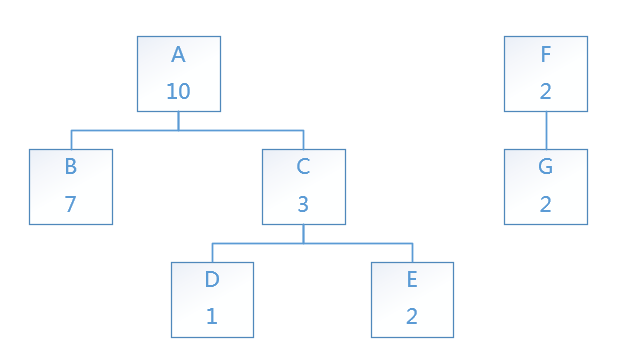
好的查询效率取决于好的存储机构,众所周知,多级目录树有如下三种存储方法,这里主要讲解这三种方式,并对其做了一些修改。这里使用同一个森林为模型(字母为节点名称,数字为节点权重)
邻接列表
这种方式最为开发人员熟知,每一个节点持有父节点的引用。为了更好的处理森林,抽象一个不存在的0节点,森林中所有树挂在改节点下,将森林转换为一颗树来处理。
改方法的SQL如下
1 CREATE TABLE node1 ( 2 id INT AUTO_INCREMENT PRIMARY KEY , 3 name VARCHAR(12) NOT NULL, 4 num INT NOT NULL DEFAULT 0 COMMENT '节点下叶子的数量、节点权重(可认为分类下产品数量)', 5 p_id INT NOT NULL DEFAULT 0 COMMENT '0表示根节点' 6 );
此方法结构简单,更新也简单,但是在查询子孙节点时,效率低下,不能满足项目需求,因为这种方式过于简单,这里就不写该结构的查询更新删除SQL了。
进阶邻接列表
该方法仅仅需要在邻接列表的基础上,添加path_key(search_key)字段,该字段存储从根节点到节点的标识路径,这里依然抽象一个不存在的0节点。
该结构SQL表示如下:
1 CREATE TABLE node2 ( 2 id INT AUTO_INCREMENT PRIMARY KEY , 3 name VARCHAR(12) NOT NULL , 4 num INT NOT NULL DEFAULT 0 COMMENT '节点下叶子的数量、节点权重(可认为分类下产品数量)', 5 p_id INT NOT NULL DEFAULT 0 COMMENT '0表示根节点', 6 search_key VARCHAR(128) DEFAULT '' COMMENT '用来快速搜索子孙的key,存储根节点到该节点的路径', 7 level INT DEFAULT 0 COMMENT '层级' 8 );
重点在于search_key字段
插入测试数据
1 INSERT INTO node2(id,name, num, p_id,search_key) VALUES 2 (1,'A',10,0,'0-1'), 3 (2,'B',7,1,'0-1-2'), 4 (3,'C',3,1,'0-1-3'), 5 (4,'D',1,3,'0-1-3-4'), 6 (5,'E',2,3,'0-1-3-5'), 7 (6,'F',2,0,'0-6'), 8 (7,'G',2,6,'0-6-7');
查询森林中的根节点
1 # 查询森林的根节点 2 SELECT * FROM node2 WHERE p_id = 0 AND search_key LIKE '0-%' AND level = 0;
查询节点A的所有子孙节点
1 # SELECT * FROM node2 WHERE search_key LIKE '{A.search_key}%'; 2 SELECT * FROM node2 WHERE search_key LIKE '0-1-%';
更新某个节点的权值,只需要一次select与一次update操作
1 # 例如,更新节点C的权重 2 UPDATE node2,( SELECT sum(num) AS sum FROM node2 WHERE search_key LIKE '0-1-3-%') rt SET num = rt.sum WHERE id=3;
有节点权重累加时,将所有父辈权重再加1,只需要将该节点的search_key以'-' 切分,得到的就是所有父辈的id(0除外)。例如,将节点D的权重+1,这里使用where locate,实际更好是先将search_key split之后使用where in查询
1 UPDATE node2,(SELECT search_key FROM node2 WHERE id = 4) rt SET num=num+1 WHERE locate(id,rt.search_key);
删除某个节点,比如删除B节点
假设删除节点子孙全部清理
1 DELETE FROM node2 WHERE search_key LIKE '0-1-2%';
假设子节点不清除 ,将子孙节点挂到父辈节点下,则需要更新儿子节点的search_key、p_id、level字段
1 # UPDATE node2, SET p_id = {B.p_id} 2 UPDATE node2 SET p_id = 1 AND search_key = concat('0-1-',id); 3 # 删除 4 DELETE FROM node2 WHERE id=2;
方式2仅仅添加了一个路径字段,使得查询变的简单,并且更新也容易,在节点深度有限的情况下,个人认为第二种方式是比较优的选择。
先序树结构
先序树即按照先序遍历的方式,给节点分配左右值,第一次到达该节点时,设置左值,第二次到达该节点,设置右值,每走一步,序号加1。这里以一段php代码来生成第一张图片中的森林的先序树结构
1 <?php 2 /** 3 * Created by PhpStorm. 4 * User: samlv 5 * Date: 2017/2/23 6 * Time: 16:44 7 */ 8 9 $forest = array( 10 array( 11 'name' => 'A', 12 'num' => 10, 13 'childs' => array( 14 array( 15 'name' => 'B', 16 'num' => 7, 17 'childs' => array() 18 ), 19 array( 20 'name' => 'C', 21 'num' => 3, 22 'childs' => array( 23 array( 24 'name' => 'D', 25 'num' => 1, 26 'childs' => array() 27 ), 28 array( 29 'name' => 'E', 30 'num' => 2, 31 'childs' => array() 32 ) 33 ) 34 ) 35 ) 36 ), 37 array( 38 'name' => 'F', 39 'num' => 2, 40 'childs' => array( 41 array( 42 'name' => 'G', 43 'num' => 2, 44 'childs' => array() 45 ) 46 ) 47 ) 48 ); 49 50 function pre_order(& $forset,$level){ 51 static $i = 1; 52 static $tree_id = 1; 53 foreach($forset as & $node){ 54 $node['lft'] = $i ++ ; 55 if(!empty($node['childs'])){ 56 pre_order($node['childs'],$level + 1); 57 } 58 $node['rgt'] = $i ++ ; 59 echo "{$node['lft']} | {$node['name']} | {$node['rgt']} \n"; 60 //echo "insert into node3 (tree_id, name, num, lft, rgt, level) VALUE ($tree_id,'{$node['name']}',{$node['num']},{$node['lft']},{$node['rgt']},$level); \n"; 61 if($node['lft'] === 1){ 62 // 遍历新的树 63 $i = 1; 64 $tree_id ++; 65 } 66 } 67 } 68 69 pre_order($forest,1);
运行结果
C:\xampp\php\php.exe D:\www\php-all\sp.php
2 | B | 3
5 | D | 6
7 | E | 8
4 | C | 9
1 | A | 10
2 | G | 3
1 | F | 4
将结果解析成图片如下
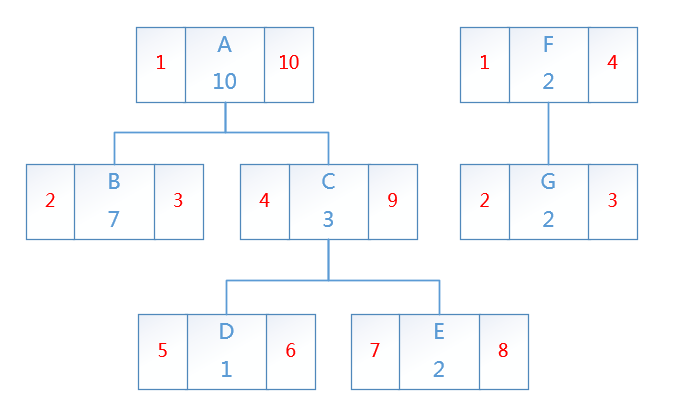
我后续以这段代码生成了SQL insert代码。用来存储该森林的SQL如下
1 CREATE TABLE node3 ( 2 id INT AUTO_INCREMENT PRIMARY KEY , 3 tree_id INT NOT NULL COMMENT '为保证对某一棵的操作不影响森林中的其他书', 4 name VARCHAR(12) NOT NULL , 5 num INT NOT NULL DEFAULT 0 COMMENT '节点下叶子的数量、节点权重(可认为分类下产品数量)', 6 lft INT NOT NULL , 7 rgt INT NOT NULL , 8 level INT DEFAULT 0 9 ); 10 insert into node3 (tree_id, name, num, lft, rgt, level) VALUE (1,'B',7,2,3,2); 11 insert into node3 (tree_id, name, num, lft, rgt, level) VALUE (1,'D',1,5,6,3); 12 insert into node3 (tree_id, name, num, lft, rgt, level) VALUE (1,'E',2,7,8,3); 13 insert into node3 (tree_id, name, num, lft, rgt, level) VALUE (1,'C',3,4,9,2); 14 insert into node3 (tree_id, name, num, lft, rgt, level) VALUE (1,'A',10,1,10,1); 15 insert into node3 (tree_id, name, num, lft, rgt, level) VALUE (2,'G',2,2,3,2); 16 insert into node3 (tree_id, name, num, lft, rgt, level) VALUE (2,'F',2,1,4,1);
这里加入了一个tree_id字段,用来保证对一棵树内的更新操作,不会影响到别的树,有利于提高效率。
对该结构的操作可以非常复杂,这里说两种基本的单元操作。
append操作,待加入节点不带子节点
remove操作,待删除节点没有子节点
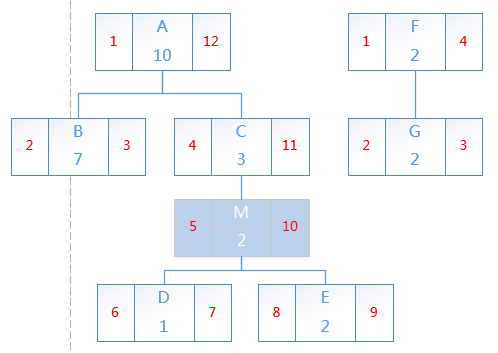
首先来看append操作,我想在节点C下添加一个M节点,如图
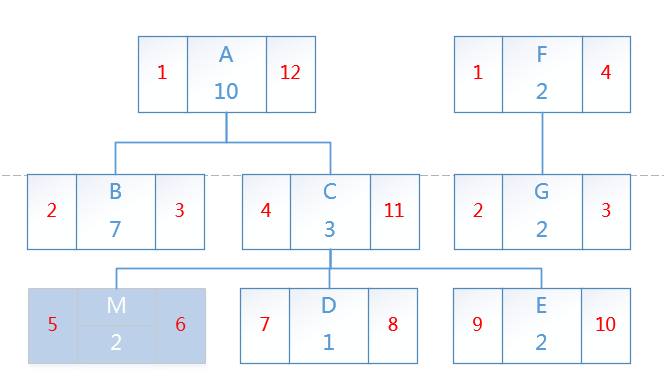
仔细看可以发现,在已有一个节点下append一个节点M的话,M的左右值应该连续的,按照先序遍历的顺序,只需要将走在其后的节点的左右值分别+2,并且M节点的父节点的右值必然也要+2。下面以一个mysql function来实现append过程
1 DROP FUNCTION IF EXISTS append_node; 2 CREATE FUNCTION append_node(param_name VARCHAR(12), param_num INT, param_p_id INT, param_tree_id INT) 3 returns INT 4 BEGIN 5 DECLARE p_lft INT; 6 DECLARE p_rgt INT; 7 DECLARE p_level INT; 8 DECLARE ret INT; 9 10 SELECT lft,rgt,level INTO p_lft,p_rgt,p_level FROM node3 WHERE tree_id = param_tree_id AND id=param_p_id ; 11 # 比前一个节点左值大的需要加2 12 UPDATE node3 SET lft = lft + 2 WHERE tree_id = param_tree_id AND lft > p_lft; 13 # 按照先序遍历规则,在一个节点M下添加节点之后,节点M的右值必然也要加2 14 UPDATE node3 SET rgt = rgt + 2 WHERE tree_id = param_tree_id AND rgt >= p_rgt; 15 INSERT INTO node3 (tree_id,name, num, lft, rgt, level) 16 VALUE (param_tree_id,param_name,param_num,p_lft + 1,p_rgt + 1,p_level + 1); 17 SELECT LAST_INSERT_ID() INTO ret; 18 RETURN ret; 19 END; 20 21 # 在节点C下添加节点M,已知节点C的id为4,tree_id为1。 22 select append_node('M', 7, 4, 1);
除了append操作之外,还可以有insert操作,如下图
其实insert操作可以看做是append 与 delete或者update结合的操作,不一定要一步到位,可以由单元操作来组成。
至于remove操作,则恰好是append操作的反向操作,需要将被删除节点后面的节点的左右值-2。最后进行delete操作。另外,删除要分两种情况,就是子孙丢弃与子孙不丢弃。