0. 背景
用过ELK(Elasticsearch, Logstash, Kibana)的人应该都面临过同样的问题,Logstash虽然功能强大:支持许多的input/output plugin、强大的filter功能。但是确内存占用会非常大。还有种情况(我就是orz...),在Logstash 5.2+版本中,input plugin使用Log4j,必须使用filebeat,并且只支持log4j 1.x版本。了解到filebeat已经支持filter和不少的output plugin,果断转投fielbeat阵营。
1. 简介
Filebeat官方介绍是这样的:
Filebeat is a log data shipper for local files. Installed as an agent on your servers, Filebeat monitors the log directories or specific log files, tails the files, and forwards them either to Elasticsearch or Logstash for indexing.
Here’s how Filebeat works: When you start Filebeat, it starts one or more prospectors that look in the local paths you’ve specified for log files. For each log file that the prospector locates, Filebeat starts a harvester. Each harvester reads a single log file for new content and sends the new log data to libbeat, which aggregates the events and sends the aggregated data to the output that you’ve configured for Filebeat.
翻译成中文大意就是:
Filebeat是一个日志数据收集工具,在服务器上安装客户端后,filebeat会监控日志目录或者指定的日志文件,追踪读取这些文件(追踪文件的变化,不停的读),并且转发这些信息到elasticsearch或者logstarsh中存放。
以下是filebeat的工作流程:当你开启filebeat程序的时候,它会启动一个或多个探测器(prospectors)去检测你指定的日志目录或文件,对于探测器找出的每一个日志文件,filebeat启动收割进程(harvester),每一个收割进程读取一个日志文件的新内容,并发送这些新的日志数据到处理程序(spooler),处理程序会集合这些事件,最后filebeat会发送集合的数据到你指定的地点。
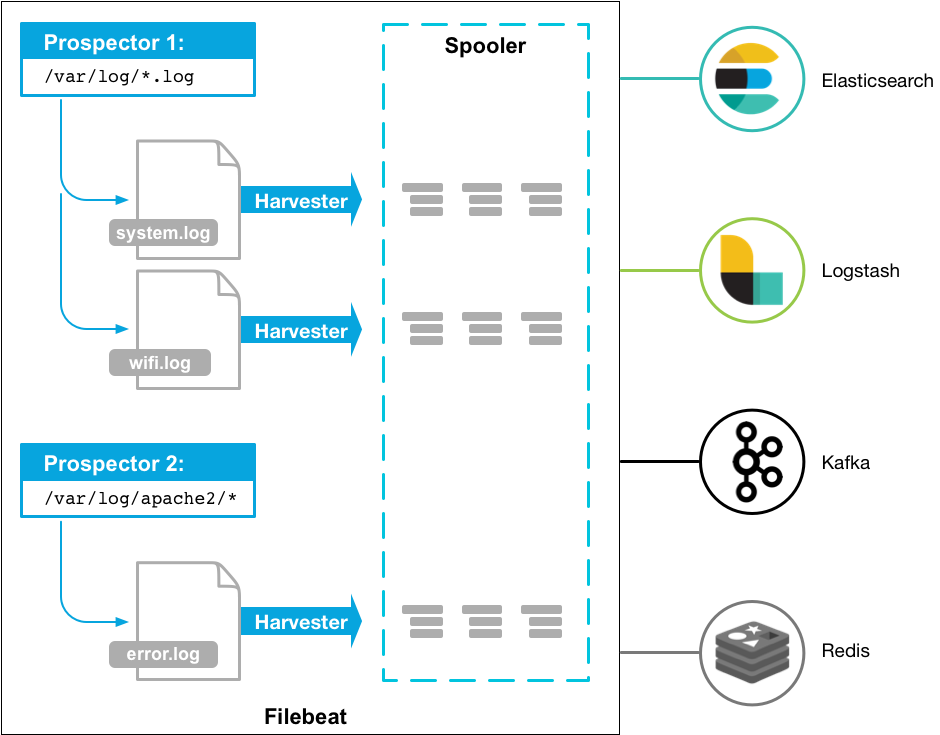
更关于探测器(prospectors)和收割进程(harvester)信息,请查看官网How Filebeat works.
1.2 核心功能
1.2.1 性能稳健,不错过任何检测信号
无论在任何环境中,随时都潜伏着应用程序中断的风险。Filebeat 能够读取并转发日志行,如果出现中断,还会在一切恢复正常后,从中断前停止的位置继续开始。
1.2.2 Filebeat 不会让通道过载
考虑到数据量较大,Filebeat 使用压力敏感协议向 Logstash 或 Elasticsearch 发送数据。如果 Logstash 正在繁忙地处理数据,它会告知 Filebeat 减慢读取速度。拥塞解决后,Filebeat 将恢复初始速度并继续输送数据。
1.2.3 不需要重载管道
当将数据发送到 Logstash 或 Elasticsearch 时,Filebeat 使用背压敏感协议,以考虑更多的数据量。如果 Logstash 正在忙于处理数据,则可以让 Filebeat 知道减慢读取速度。一旦拥堵得到解决,Filebeat 就会恢复到原来的步伐并继续运行。

1.2.4 输送至 Elasticsearch 或 Logstash。在 Kibana 中实现可视化。
Filebeat 是 Elastic Stack 的一部分,因此能够与 Logstash、Elasticsearch 和 Kibana 无缝协作。无论您要使用 Logstash 转换或充实日志和文件,还是在 Elasticsearch 中随意处理一些数据分析,亦或在 Kibana 中构建和分享仪表板,Filebeat 都能轻松地将您的数据发送至最关键的地方。
2. 性能
运行环境:
| OS | 内存 | CPU | Filebeat版本 | Logstash版本 |
|---|---|---|---|---|
| CentOS | 32g | 6核Intel(R) Xeon(R) CPU E5-2620 v3 @ 2.40GHz | 6.1 | 5.6.5 |
- Logstash内存占用
[root@dde /]# cat /proc/20085/status /proc/20085/status | grep -i vm
VmPeak: 9837428 kB
VmSize: 9835376 kB
VmLck: 0 kB
VmHWM: 798364 kB
VmRSS: 798360 kB
VmData: 9677292 kB
VmStk: 88 kB
VmExe: 4 kB
VmLib: 16520 kB
VmPTE: 2568 kB
VmSwap: 0 kB
VmPeak: 9837428 kB
VmSize: 9835376 kB
VmLck: 0 kB
VmHWM: 798364 kB
VmRSS: 798360 kB
VmData: 9677292 kB
VmStk: 88 kB
VmExe: 4 kB
VmLib: 16520 kB
VmPTE: 2568 kB
VmSwap: 0 kB- Filebeat内存占用
[root@dde /]# cat /proc/22207/status /proc/22207/status | grep -i vm
VmPeak: 452796 kB
VmSize: 410180 kB
VmLck: 0 kB
VmHWM: 16008 kB
VmRSS: 16008 kB
VmData: 376332 kB
VmStk: 88 kB
VmExe: 24764 kB
VmLib: 1804 kB
VmPTE: 184 kB
VmSwap: 0 kB
VmPeak: 452796 kB
VmSize: 410180 kB
VmLck: 0 kB
VmHWM: 16008 kB
VmRSS: 16008 kB
VmData: 376332 kB
VmStk: 88 kB
VmExe: 24764 kB
VmLib: 1804 kB
VmPTE: 184 kB
VmSwap: 0 kBLogstash因为是运行是JVM中的,可以看到Logstash内存占用比Filebeat大的多。
3. 安装
Filebeat官方提供了以下几种安装方式: (deb for Debian/Ubuntu, rpm for Redhat/Centos/Fedora, mac for OS X, docker for any Docker platform, and win for Windows).
- deb:
curl -L -O https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-6.1.2-amd64.deb
sudo dpkg -i filebeat-6.1.2-amd64.deb- rpm:
curl -L -O https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-6.1.2-x86_64.rpm
sudo rpm -vi filebeat-6.1.2-x86_64.rpm- mac
curl -L -O https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-6.1.2-darwin-x86_64.tar.gz
tar xzvf filebeat-6.1.2-darwin-x86_64.tar.gz- docker:
docker pull docker.elastic.co/beats/filebeat:6.1.2- windows:
1.下载zip包,地址。
2.解压到:C:\Program Files。
3.重命名文件夹为以下格式:filebeat-<version>-windows。
4.以管理员身份运行Shell。
5.使用如下命令,讲Filebeat安装为一个Windows Service:
PS > cd 'C:\Program Files\Filebeat'
PS C:\Program Files\Filebeat> .\install-service-filebeat.ps14. 配置
Elastic提供了一个配合ELK(Elasticsearch + Logstash + Kibana)的快速配置方式,不过我们不需要配合ELK使用Filebeat。直接配置filebeat根目录下filebeat.yml文件:
filebeat.prospectors:
- type: log
enabled: true
paths:
- /var/log/*.log
#- c:\programdata\elasticsearch\logs\*需要配合elasticsearch使用时,增加以下配置:
output.elasticsearch:
hosts: ["192.168.1.42:9200"]需要配合kibana使用时,增加以下配置:
setup.kibana:
host: "localhost:5601"- Output
Filebeat现在已经支持丰富的output类型:
- Elasticsearch
- Logstash
- Kafka
- Redis
- File
- Console
- Output codec
- Cloud
output到kafka的配置类似:
output.kafka:
# initial brokers for reading cluster metadata
hosts: ["kafka1:9092", "kafka2:9092", "kafka3:9092"]
# message topic selection + partitioning
topic: '%{[fields.log_topic]}'
partition.round_robin:
reachable_only: false
required_acks: 1
compression: gzip
max_message_bytes: 1000000当事件的大小超过max_message_bytes的值的时候,会被直接丢弃不处理,所以要尽量控制filebeat产生的事件小于max_message_bytes的值。
上面示例中字段含义如下:enable: 该output是否生效;hosts:kafka broker集群地址;topic: kafka接收事件的topic;partition: kafka output的partioning 策略,可能值为:random, round_robin, hash。默认为hash;官方关于这几个可选值解释如下:
random.group_events:
Sets the number of events to be published to the same partition, before the partitioner selects a new partition by random. The default value is 1 meaning after each event a new partition is picked randomly.
round_robin.group_events:
Sets the number of events to be published to the same partition, before the partitioner selects the next partition. The default value is 1 meaning after each event the next partition will be selected.
hash.hash:
List of fields used to compute the partitioning hash value from. If no field is configured, the events key value will be used.
hash.random:
Randomly distribute events if no hash or key value can be computed.
required_acks: kafka broker ACK可靠级别: 0=不需要响应, 1=等待本地commit, -1=等待所有的 replicascommit. 默认值为 1.
Note: 如果设置为0,kafka将没有ACK返回,也许会有消息丢失或者错误。
5.运行
sudo ./filebeat -e -c filebeat.ymlFilebeat目前已经支持Docker和Kubernetes。
5.1 Docker
(1)pull image
docker pull docker.elastic.co/beats/filebeat:6.1.2
(2) run image
docker run \
-v ~/filebeat.yml:/usr/share/filebeat/filebeat.yml \
docker.elastic.co/beats/filebeat:6.1.2(3) Configuration
FROM docker.elastic.co/beats/filebeat:6.1.2
COPY filebeat.yml /usr/share/filebeat/filebeat.yml
USER root
RUN chown filebeat /usr/share/filebeat/filebeat.yml
USER filebeat5.2 Kubernetes
(1)Deploy manifests
curl -L -O https://raw.githubusercontent.com/elastic/beats/6.1/deploy/kubernetes/filebeat-kubernetes.yaml
(2)Setting
- name: ELASTICSEARCH_HOST
value: elasticsearch
- name: ELASTICSEARCH_PORT
value: "9200"
- name: ELASTICSEARCH_USERNAME
value: elastic
- name: ELASTICSEARCH_PASSWORD
value: changeme(3)Deploy
kubectl create -f filebeat-kubernetes.yaml
check status
$ kubectl --namespace=kube-system get ds/filebeat
NAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE-SELECTOR AGE
filebeat 32 32 0 32 0 <none> 1m
