ParisGabriel
每天坚持手写 一天一篇 决定坚持几年 为了梦想为了信仰
 开局一张图
开局一张图
表字段重命名(change)
alter table 表名 change 原名 新名 数据类型;
SQL查询
执行顺序:
3. select ...聚合函数 from 表名
1. where ...
2. group by...
4. having...
5. order by...
6. limit...
group by 语句
作用:给查询结果进行
分组
注意:
1.
group by之后的
字段必须要为
select之后的
字段名
2.
如果select之后的字段和group by 之后的
字段不一致,则
必须对
字段
进行聚合处理(聚合函数)
having 语句
作用:对查询结果
进一步筛选
注意:
1.
having语句通常和
group by联合使用,
过滤由
group by语句
返回的记录集
2.
where只能操作表中
实际存在的
字段,
having by可操作由聚合函数生成的显示列
distinct
作用:不显示字段
重复值
注意:
1.distinct和from之间
所有字段都相同
才会去重
2.distinct
不能对任何字段做聚合
处理
运算符:
+ - * / %
## sudo apt-get install python3-pip 安装pip3
## sudo pip3 install pymysql 安装mysql
约束:
1.作用:
保证数据的
完整性、
一致性、
有效性
2.约束分类
1.默认约束(
default)
插入字段时
不给该字段
赋值 则
使用默认值
2.非空约束(
not NULL)
不允许该字段值有NULL记录
sex enum(“M”,"F","S") not null defaulf "S"
索引
定义:
对数据库表色一列或多列的
值进行排序的一种
结构
(Btree方式)
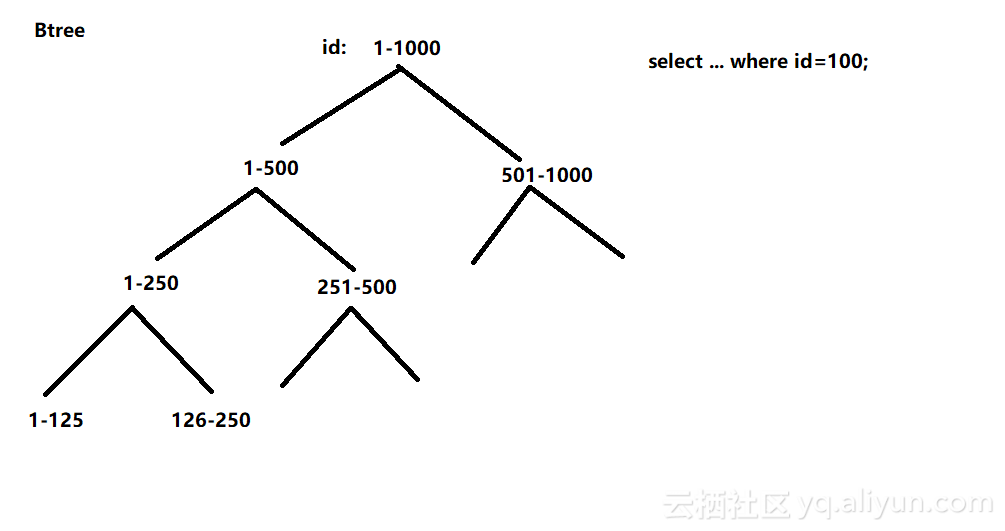
优点:
加快数据的
检索速度
缺点:
1.需要
占用物理存储空间
2.当对表中数据更新时,索引需要
动态维护。
降低
数据
维护速度
占用系统资源
运行时间检测:
开启:set profiling=1;
关闭:set profiling=0;
查询MySQL变量:show variables like profiling;
查询执行记录:show profilings;
字段创建索引:
create index name on t1(字段名);
索引的分类:
1.普通索引(index)
使用规则:
1.可设置多个字段
2.字段值
无约束
3.key标志:
MUL
创建index
创建表时创建
create table(....
...
index(字段名),
index(字段名2)...)
已有表添加index
create index 索引名 on 表名(字段名);
查看索引:
1.desc 表名; key:MUL
2.show index from 表名
3.show index from\G;
删除索引:
drop index 索引名 on 表名;
2.唯一索引(unique)
使用规则:
1.可以设置多个字段
2.约束:字段值不允许重复,但
可以为NULL
3.key标志:
UNI
创建unique:
1.创建表时创建
unique(字段名),..
2.已有表
create unique index 索引名 on 表名(字段名);
查看、删除
和普通索引一致
3.主键索引(primary key)
自增属性(
auto_increment,
配合主键一起
使用)
使用规则:
1.
只能有一个主键字段
2.
约束:不允许重复,且
不能为NULL
3.key标志:
PRI
4.
通常设置记录编号字段
id,能
唯一锁定一条
记录
创建primary key
创建表时:
1.
id int primary key auto_increment,
2.
起始值:表()
auto_inctement=10000;
已有表:
alter table 表名 add primary key(id);
添加:alter table 表名 modify id int auto_inctement;
删除:
1.删除自增属性(modify)
alter table 表名 modify id int;
2.删除主键索引
alter table 表名 drop primary key;
4.外键索引........
算法全是
btree 节省时间都一样 不同的是约束不同
这里btree 算法 有人说btree就是btree 不是二叉树 但是我觉得就是二叉树 没什么区别
根据数据量的大小 提升速度 快能达到几百倍的提速
数据导入:
作用:
把文件系统的内容导入到数据库
语法:
load data infile “文件名”
into table 表名
fields terminated by “分隔符”
lines terminated by “\n”;
步骤:
1.
数据库中
创建对应的
表
2.
把文件拷贝到数据库的
默认搜索路径中
1.查看默认路径
show variables like “secure_file_priv”;
/var/lib/mysql-files/
2.拷贝文件
sudo cp ~/scoretable.csv /var/lib/mysql-files/
3.把表导入到数据库
数据导出:
作用:
数据库中表的记录导出到系统文件里
语法:
select ... from 表名
into outfile “/var/lib/mysql-files/文件名”
fields terminated by “分隔符”
lines terminated by “\n”;
步骤:
1.直接执行导出命令
2.自动创建文件
3.默认导出到默认搜索路径
文件权限:
rwx
rw-
rw- 1 tarena tarena
所有者 所属组
rwx:tarena用户
rw-:同组其他用户
rw-:其他组的用户(mysql)
r: 4
w: 2
x: 1
最高权限:7
查看权限:ls -l 文件名
修改文件权限:
chmod 644 文件名
Excel表格如何
转化为
CSV文件
打开Excel文件 -> 另存为 -> CSV(逗号分隔)
更改文件
编码格式
用记事本/编辑器 打开,文件->另存为->选择编码
导入示例:
3、将scoretable.csv文件导入到数据库的表中
1、在数据库中创建对应的表
create table scoretab(
id int,
name varchar(15),
score float(5,2),
number bigint,
class char(7)
);
2、把文件拷贝到数据库的默认搜索路径中
1、查看默认搜索路径
show variables like "secure_file_priv";
/var/lib/mysql-files/
2、拷贝文件
sudo cp ~/scoretable.csv /var/lib/mysql-files/
3、执行数据导入语句
load data infile "/var/lib/mysql-files/scoretable.csv"
into table scoretab
fields terminated by ","
lines terminated by "\n";
导出示例:
把MOSHOU库下的sanguo表英雄的姓名、攻击值、国家导出来,sanguo.txt
select name,gongji,country from MOSHOU.sanguo
into outfile "/var/lib/mysql-files/sanguo.txt"
fields terminated by " "
lines terminated by "\n";
将mysql库下的user表中 user、host两个字段的值导出到 user.txt
select user,host from mysql.user
into outfile "/var/lib/mysql-files/user.txt" fields terminated by " "
lines terminated by "\n";
查询
$ sudo -i
$ cd /var/lib/mysql-files/
$ ls
$ cat sanguo.txt

