一、线性回归算法的简介
线性回归是利用数理统计中回归分析,来确定两种或两种以上变量间相互依赖的定量关系的一种统计分析方法,运用十分广泛。其表达形式为y = w'x+e,e为误差服从均值为0的正态分布。
回归分析中,只包括一个自变量和一个因变量,且二者的关系可用一条直线近似表示,这种回归分析称为一元线性回归分析。如果回归分析中包括两个或两个以上的自变量,且因变量和自变量之间是线性关系,则称为多元线性回归分析。
本文主要介绍线性回归算法的演绎推导,关于线性回归的详细介绍请参阅线性回归在百度百科中的介绍。
线性回归算法是机器学习中的基础算法,所以对于想要学习机器学习的读者来说,最好完全理解该算法。
二、线性回归算法的演绎推导
假设,在银行中申请行用卡的额度与如下两个参数有关,即年龄和工资,有一申请人的资料如下图,那么知道一个人的年龄和工资该如何预测出他所能申请信用卡的额度呢?
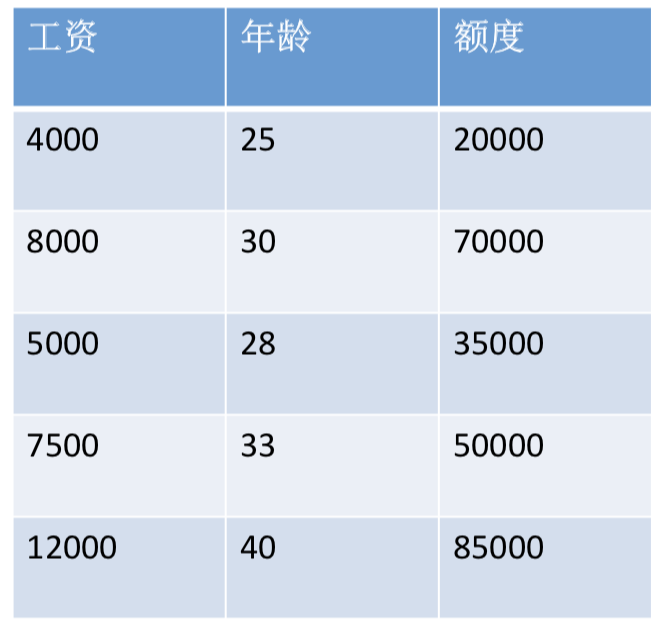
对于一个线性关系,我们使用y=ax+b表示,但在这种关系中y只受一个x的影响,二者的关系可用一条直线近似表示,这种关系也叫一元线性回归。而在本例中,设额度为h,工资和年龄分别为x1和x2,则可以表示成下式,![]() ,在这种关系中结果收到多个变量的影响,称为多元线性回归分析。
,在这种关系中结果收到多个变量的影响,称为多元线性回归分析。
我们将上式中的θ和x分别表示成两个一维矩阵[θ0 θ1 θ2]和[x0 x1 x2],则可将上式化为![]() (令x0=1)。
(令x0=1)。
而实际结果不可能完全符合我们的计算结果,所以两者之间必定存在误差,假设对于第i个样本,存在如下关系,![]() ,其中
,其中![]() 为真实误差。
为真实误差。
误差![]() 独立并且具有相同的分布(通常认为是均值为0的高斯分布)。
独立并且具有相同的分布(通常认为是均值为0的高斯分布)。
所以可以得到下式:
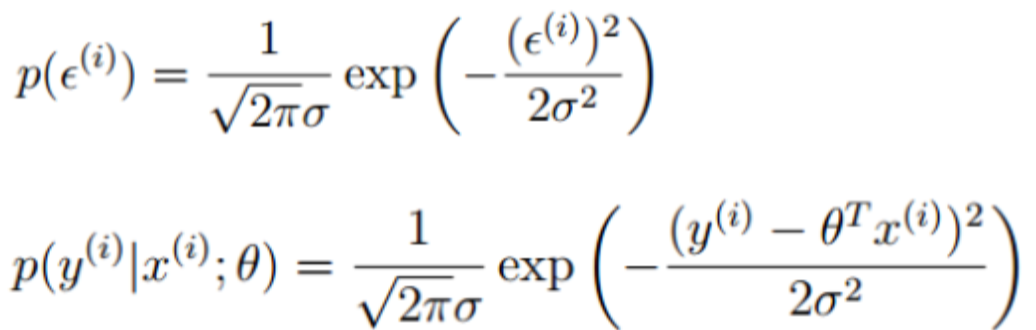
那么,如果存在大量的样本,我们就可以通过![]() 和
和![]() 做关于θ的参数估计,
做关于θ的参数估计,
求似然函数如下:
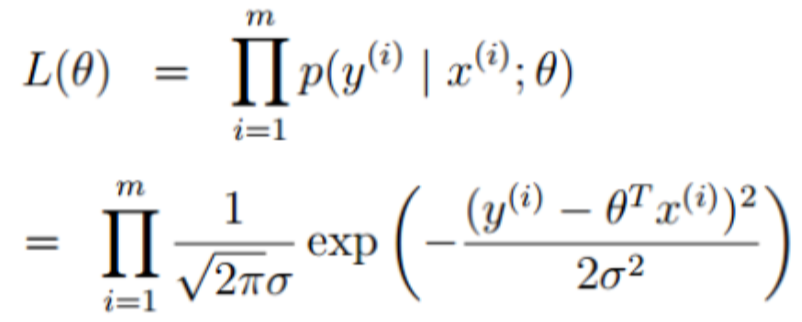
对上式求对数:
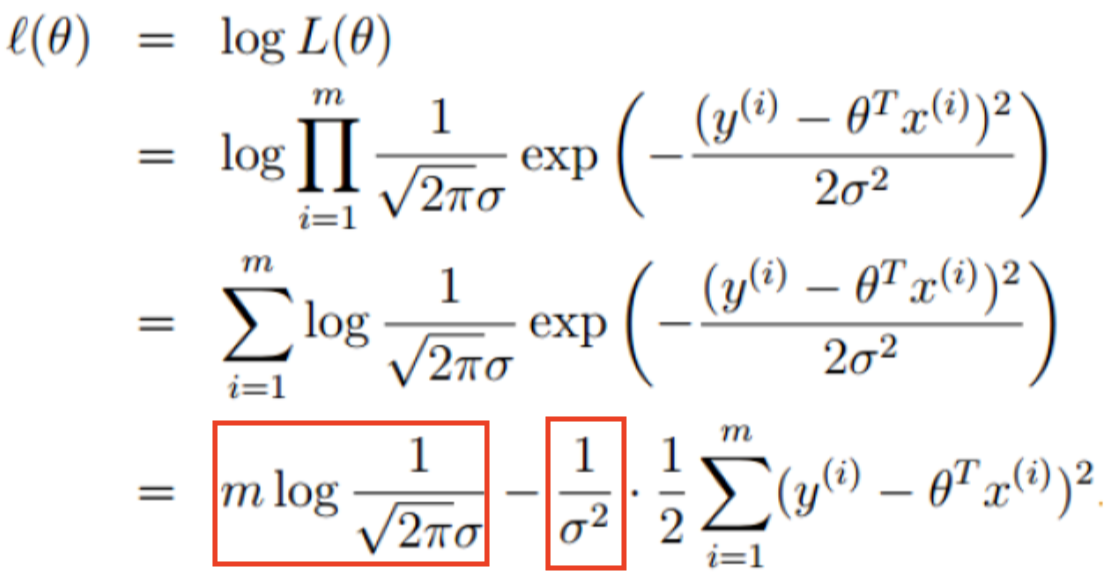
对上式求导,使其值为0,便可求得θ的最大似然估计。
在上式中,被标记的两部分都是常数,前一部分求导后为零,后一部分为一个因数,不会影响最终结果。所以,对于最终结果,只需让未被标记的部分求导后为0。所以使:
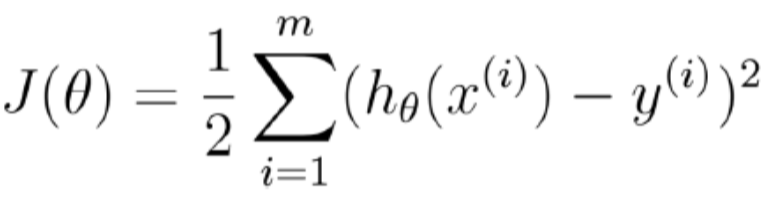 ,
,
将上式化简,并对θ求偏导:
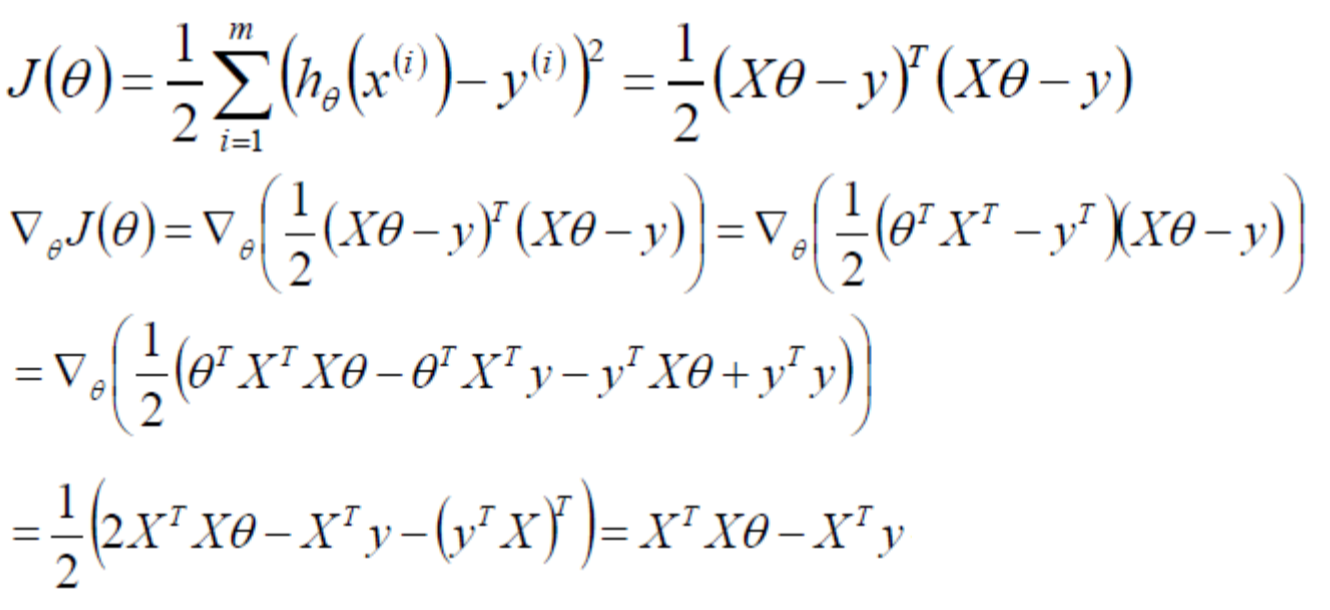
将求导的结果设值为0,便可求得θ的最大似然估计(最小二乘法),
![]()
得到θ后,我们即通过样本训练出了一个线性回归模型,便可使用![]() 对结果未知的数据进行预测。
对结果未知的数据进行预测。
PS: 读者只需理解改算法的推导过程即可,对于数据的计算,编程解决即可,无需手动计算(对于多维矩阵的计算量相当大,而且很容易算错 ( ̄▽ ̄)")。
