Linux虚拟文件系统剖析:
文件打开、读、写逻辑
perftrace@gmail.com
1 Linux文件系统剖析:文件打开操作
本文主要通过分析linux系统中的文件打开逻辑,来掌握linux虚拟文件系统相关的数据结构、函数等知识点,将之前的各个点的知识串联成一个整体。
系统中给所有文件系统不但依赖VFS,而且依靠VFS系统协同工作。使用VFS可以利用标准的Unix系统调用对不同的文件系统,甚至不同介质上的文件系统进行读写操作。
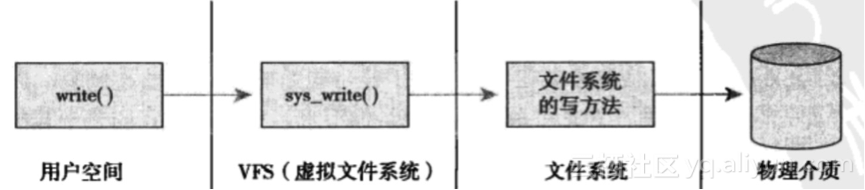
Unix使用了四种和文件系统相关的传统抽象概念:文件、目录项、索引节点和安装点。
VFS中共有四个主要对象类型分别是:
l  超级块对象,代表一个具体的已安装文件系统,操作对象为super_operations
l  索引节点对象,代表一个具体文件,操作对象为inode_operations
l  目录项对象,代表一个目录项,是路径的一个组成部分,操作对象为dentry_operations
l  文件对象,代表由进程打开的文件,操作对象为file_operations
不存在目录对象。
涉及的数据结构在文中会逐一出现。下面我们从上层应用开始来看下linux系统打开一个文件的逻辑过程。
1.1 应用触发
使用一个C程序如下:
#include <unistd.h>
#include <stdio.h>
#include <sys/mman.h>
#include <fcntl.h>
#include <stdlib.h>
int
main ()
{
int i, f;
FILE *fp;
char string[24];
fp = fopen ("test.dat", "w+");
sprintf (string, "helloworld\n");
fwrite (string, 11, 1, fp);
fclose (fp);
}
直接使用gcc编译,#gcc -g -o io io.c
这里我们看到在应用中使用了函数fopen(库函数),该函数来负责打开文件。
这个函数在linux中就是 glibc 。其官方下载链接是:https://www.gnu.org/software/libc/sources.html。
1.2 内核入口
使用strace ./io后,可以发现会调用系统调用open来实现文件的打开。
……
open("test.dat", O_RDWR|O_CREAT|O_TRUNC, 0666) = 3
……
这个系统调用才是内核中的函数,该函数定义在如下:
SYSCALL_DEFINE3(open, const char __user *, filename, int, flags, umode_t, mode)
{
if (force_o_largefile())
flags |= O_LARGEFILE;
return do_sys_open(AT_FDCWD, filename, flags, mode);
}
这个是系统调用,会调用do_sys_open函数。
在do_sys_open函数中,会通过函数build_open_flags来设置需要打开文件的flags(其结构体为open_flags),接着通过函数get_unused_fd_flags获取一个可用的fd,此函数调用alloc_fd()函数从fd_table中获取一个可用fd,并做些简单初始化得到一个文件描述符。接着调用do_filp_open函数获取file对象。最后通过fd_install,建立文件描述符和file之间的关联,即安装在进程的fd数组中。
其中关键的函数是do_filp_open,需要根据文件名字进行搜索,如果不存在需要进行文件创建。这里相关数据结构是ext4_dir_inode_operations,不同的文件系统会有不同的数据结构,从而指定不同的函数。
另外对应的ext4文件系统inode_operations操作如下:
const struct inode_operations ext4_dir_inode_operations = {
.create = ext4_create,
.lookup = ext4_lookup,
.link = ext4_link,
.unlink = ext4_unlink,
.symlink = ext4_symlink,
.mkdir = ext4_mkdir,
.rmdir = ext4_rmdir,
.mknod = ext4_mknod,
.tmpfile = ext4_tmpfile,
.rename = ext4_rename2,
.setattr = ext4_setattr,
.getattr = ext4_getattr,
.listxattr = ext4_listxattr,
.get_acl = ext4_get_acl,
.set_acl = ext4_set_acl,
.fiemap = ext4_fiemap,
};
在ext4文件系统中的查找会调用函数ext4_lookup函数,如果是需要创建文件则会调用ext4_create函数。
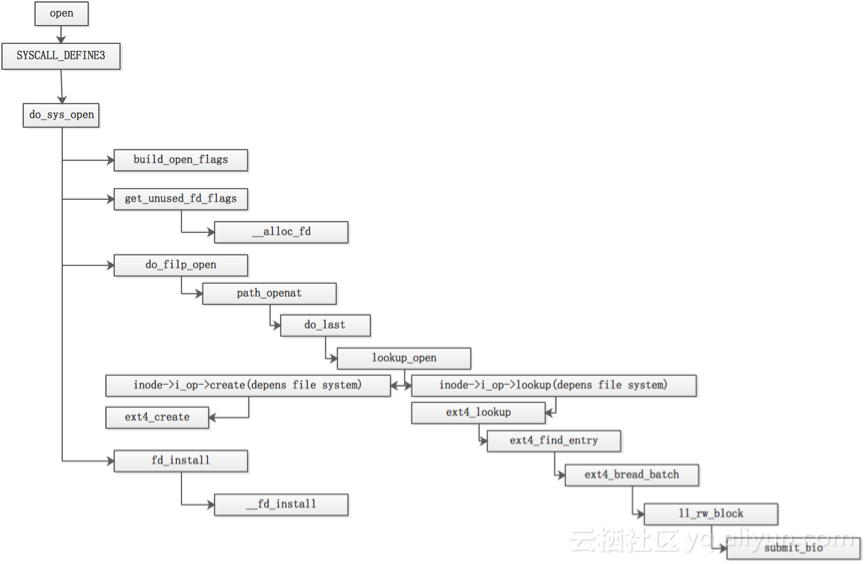
1.3 逻辑流程
逻辑流程如下图,到submit_bio后会调用generic_make_request从而进入块层:
1.4 参考
2 Linux文件系统剖析:文件读操作
下面我们来看下系统的文件读操作,内核版本基于4.17.2。
内核中的读文件基于页的,内核总是一次传送几个完整的数据页。如果数据不在RAM 中,内核会分配一个新页框,并使用文件适当部分填充并放入到页高速缓存,最后把所需读字节复制到进程地址空间中。
我们从系统调用read开始,其系统调用实现如下,相比之前版本使用了ksys_read函数进行重新封装。
SYSCALL_DEFINE3(read, unsigned int, fd, char __user *, buf, size_t, count)
{
return ksys_read(fd, buf, count);
}
ksys_read函数如下:
ssize_t ksys_read(unsigned int fd, char __user *buf, size_t count)
{
struct fd f = fdget_pos(fd);
ssize_t ret = -EBADF;
if (f.file) {
loff_t pos = file_pos_read(f.file);
ret = vfs_read(f.file, buf, count, &pos);
if (ret >= 0)
file_pos_write(f.file, pos);
fdput_pos(f);
}
return ret;
}
file_pos_read和file_pos_write是读写文件中读写位置。fdget_pos和fdput_pos是锁相关操作。然后调用了vfs_read函数,该函数是read的具体实现,也是虚拟文件系统读的总开始,很多关于文件系统的监控点都会设置在此函数上。
再来看下vfs_read函数,其定义如下,入参分别是文件句柄的file结构,用户空间缓存,读取数量和读取位置。
ssize_t vfs_read(struct file *file, char __user *buf, size_t count, loff_t *pos)
{
ssize_t ret;
if (!(file->f_mode & FMODE_READ))
return -EBADF;
if (!(file->f_mode & FMODE_CAN_READ))
return -EINVAL;
if (unlikely(!access_ok(VERIFY_WRITE, buf, count)))
return -EFAULT;
ret = rw_verify_area(READ, file, pos, count);
if (!ret) {
if (count > MAX_RW_COUNT)
count = MAX_RW_COUNT;
ret = __vfs_read(file, buf, count, pos);
if (ret > 0) {
fsnotify_access(file);
add_rchar(current, ret);
}
inc_syscr(current);
}
return ret;
}
先通过函数rw_verify_area做一些入参的基本检测,如读写位置是否为负,或者读的数量超过文件自身字节数上限,如果该函数执行出错就直接就退出读操作了。如果要读取数量大于系统最大读取数量,则设置读取数量为系统的值。
然后调用__vfs_read函数。读写成功后会通过fsnotify_access来通知文件被读取,以及调用add_rchar来增加当前进程读取字节数,通过函数inc_syscr来增加进程的系统调用次数。主要的核心是__vfs_read函数。
1.5 __vfs_read
那么主要来看下__vfs_read函数。其定义如下:
ssize_t __vfs_read(struct file *file, char __user *buf, size_t count,
loff_t *pos)
{
if (file->f_op->read)
return file->f_op->read(file, buf, count, pos);
else if (file->f_op->read_iter)
return new_sync_read(file, buf, count, pos);
else
return -EINVAL;
}
代码不长,先是使用file的f_op函数集,ext4则是结构体ext4_ ,定义如下,
const struct file_operations ext4_file_operations = {
.llseek = ext4_llseek,
.read_iter = ext4_file_read_iter,
.write_iter = ext4_file_write_iter,
.unlocked_ioctl = ext4_ioctl,
#ifdef CONFIG_COMPAT
.compat_ioctl = ext4_compat_ioctl,
#endif
.mmap = ext4_file_mmap,
.mmap_supported_flags = MAP_SYNC,
.open = ext4_file_open,
.release = ext4_release_file,
.fsync = ext4_sync_file,
.get_unmapped_area = thp_get_unmapped_area,
.splice_read = generic_file_splice_read,
.splice_write = iter_file_splice_write,
.fallocate = ext4_fallocate,
};
非文件系统的操作函数集如下def_blk_fops,在没有文件系统的时候会使用此处的函数:
const struct file_operations def_blk_fops = {
.open = blkdev_open,
.release = blkdev_close,
.llseek = block_llseek,
.read_iter = blkdev_read_iter,
.write_iter = blkdev_write_iter,
.mmap = generic_file_mmap,
.fsync = blkdev_fsync,
.unlocked_ioctl = block_ioctl,
#ifdef CONFIG_COMPAT
.compat_ioctl = compat_blkdev_ioctl,
#endif
.splice_read = generic_file_splice_read,
.splice_write = iter_file_splice_write,
.fallocate = blkdev_fallocate,
};
此外xfs文件系统的操作函数集如下:
const struct file_operations xfs_file_operations = {
.llseek = xfs_file_llseek,
.read_iter = xfs_file_read_iter,
.write_iter = xfs_file_write_iter,
.splice_read = generic_file_splice_read,
.splice_write = iter_file_splice_write,
.unlocked_ioctl = xfs_file_ioctl,
#ifdef CONFIG_COMPAT
.compat_ioctl = xfs_file_compat_ioctl,
#endif
.mmap = xfs_file_mmap,
.mmap_supported_flags = MAP_SYNC,
.open = xfs_file_open,
.release = xfs_file_release,
.fsync = xfs_file_fsync,
.get_unmapped_area = thp_get_unmapped_area,
.fallocate = xfs_file_fallocate,
.clone_file_range = xfs_file_clone_range,
.dedupe_file_range = xfs_file_dedupe_range,
};
在4.17.2内核中,其read函数并没有定义,所以调用new_sync_read函数。
new_sync_read函数如下,
static ssize_t new_sync_read(struct file *filp, char __user *buf, size_t len, loff_t *ppos)
{
struct iovec iov = { .iov_base = buf, .iov_len = len };
struct kiocb kiocb;
struct iov_iter iter;
ssize_t ret;
init_sync_kiocb(&kiocb, filp);
kiocb.ki_pos = *ppos;
iov_iter_init(&iter, READ, &iov, 1, len);
ret = call_read_iter(filp, &kiocb, &iter);
BUG_ON(ret == -EIOCBQUEUED);
*ppos = kiocb.ki_pos;
return ret;
}
函数中kiocb表示io control block. 用来跟踪记录IO操作的完成状态,iov_iter用来从用户和内核之间传递数据用,该结构在内核中很多地方有用到,例如网络子系统。通过init_sync_kiocb来初始化kiocb.如下:
static inline void init_sync_kiocb(struct kiocb *kiocb, struct file *filp)
{
*kiocb = (struct kiocb) {
.ki_filp = filp,
.ki_flags = iocb_flags(filp),
.ki_hint = file_write_hint(filp),
};
}
iov_iter_init用来初始化iov_iter。
接着就是调用call_read_iter函数,如下,其实就是调用ext4_file_operations中的 ext4_file_read_iter。
static inline ssize_t call_read_iter(struct file *file, struct kiocb *kio,
struct iov_iter *iter)
{
return file->f_op->read_iter(kio, iter);
}
我们来看下ext4_file_read_iter函数,
static ssize_t ext4_file_read_iter(struct kiocb *iocb, struct iov_iter *to)
{
if (unlikely(ext4_forced_shutdown(EXT4_SB(file_inode(iocb->ki_filp)->i_sb))))
return -EIO;
if (!iov_iter_count(to))
return 0; /* skip atime */
#ifdef CONFIG_FS_DAX
if (IS_DAX(file_inode(iocb->ki_filp)))
return ext4_dax_read_iter(iocb, to);
#endif
return generic_file_read_iter(iocb, to);
}
函数ext4_forced_shutdown会获取ext4超级块的信息,来检测下相关flag中的EXT4_FLAGS_SHUTDOWN位.然后函数iov_iter_count检测下iov_iter的成员count变量。
然后判断内核是否配置了CONFIG_FS_DAX(Direct access),以及文件的打开方式是否是直接访问设备,这个直接影响访问是否绕过pagecache.如果配置了CONFIG_FS_DAX,且文件打开方式指定了直接访问,那么则调用ext4_dax_read_iter函数。否则调用generic_file_read_iter函数。因为CONFIG_FS_DAX默认系统是不设置的,并不是常用的配置项,而且就算配置在函数ext4_dax_read_iter中还会判断inode是否支持直接访问,否则还是会调用函数generic_file_read_iter。而如果是xfs文件系统则调用函数xfs_file_buffered_aio_read,继而调用generic_file_read_iter函数。
下面来我们来看下generic_file_read_iter函数。
1.6 generic_file_read_iter
generic_file_read_iter函数是文件系统的读路径。该函数比较长不列出来了,可以自行观察mm/filemap.c.
该函数是会先根据iocb中打开文件的flag来判断是否是Direct IO,如果是则进入到Direct IO分支,判断上次写操作是否需要filemap_write_and_wait_range函数同步,确保读到的数据是最新的,然后调用mapping->a_ops->direct_IO来访问数据,其中dirct_IO是address_space_operations函数集指定的函数,在ext4中是ext4_direct_IO。
static const struct address_space_operations ext4_aops = {
.readpage = ext4_readpage,
.readpages = ext4_readpages,
.writepage = ext4_writepage,
.writepages = ext4_writepages,
.write_begin = ext4_write_begin,
.write_end = ext4_write_end,
.set_page_dirty = ext4_set_page_dirty,
.bmap = ext4_bmap,
.invalidatepage = ext4_invalidatepage,
.releasepage = ext4_releasepage,
.direct_IO = ext4_direct_IO,
.migratepage = buffer_migrate_page,
.is_partially_uptodate = block_is_partially_uptodate,
.error_remove_page = generic_error_remove_page,
};
相关数据结构之间的关系如下:
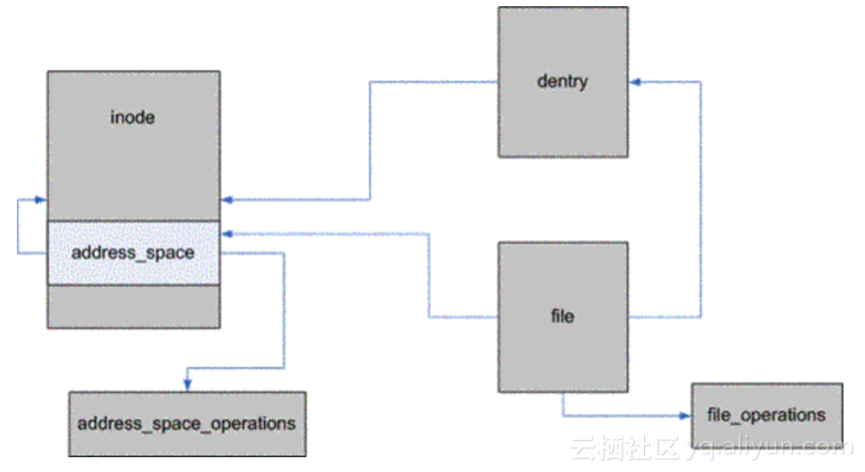
不同的文件系统有不同的直接IO读函数,再看一个xfs文件系统是noop_diret_IO.
const struct address_space_operations xfs_address_space_operations = {
.readpage = xfs_vm_readpage,
.readpages = xfs_vm_readpages,
.writepage = xfs_vm_writepage,
.writepages = xfs_vm_writepages,
.set_page_dirty = xfs_vm_set_page_dirty,
.releasepage = xfs_vm_releasepage,
.invalidatepage = xfs_vm_invalidatepage,
.bmap = xfs_vm_bmap,
.direct_IO = noop_direct_IO,
.migratepage = buffer_migrate_page,
.is_partially_uptodate = block_is_partially_uptodate,
.error_remove_page = generic_error_remove_page,
};
默认的操作函数集是def_blk_aops
static const struct address_space_operations def_blk_aops = {
.readpage = blkdev_readpage,
.readpages = blkdev_readpages,
.writepage = blkdev_writepage,
.write_begin = blkdev_write_begin,
.write_end = blkdev_write_end,
.writepages = blkdev_writepages,
.releasepage = blkdev_releasepage,
.direct_IO = blkdev_direct_IO,
.is_dirty_writeback = buffer_check_dirty_writeback,
};
如果不是直接IO则调用generic_file_buffered_read。
1.7 generic_file_buffered_read
该函数是通用文件读路径。循环在内存中寻找所读取内容是否在内存中缓存,如果cache命中失败,使用
page_cache_async_readahead/page_cache_sync_readahead会从磁盘中读取页,并进行预读。此外,还要判断页是否是最新,以免读到脏数据;如果非最新则需要调用address_space_operations中readpage函数进行读操作获取最新页,读页的函数最后都会调用submit_bio,将。
此外,如果内存已经没有page cache,则需要调用函数page_cache_alloc来进行分类page并加入到page_cache_lru,最后通过copy_page_to_iter将内存中数据复制到用户空间。
最后通过函数file_accessed来更新文件访问时间。
这个函数也是后续需要进一步关注的地方。
1.8 逻辑流程
这个读逻辑流程如下图所示:
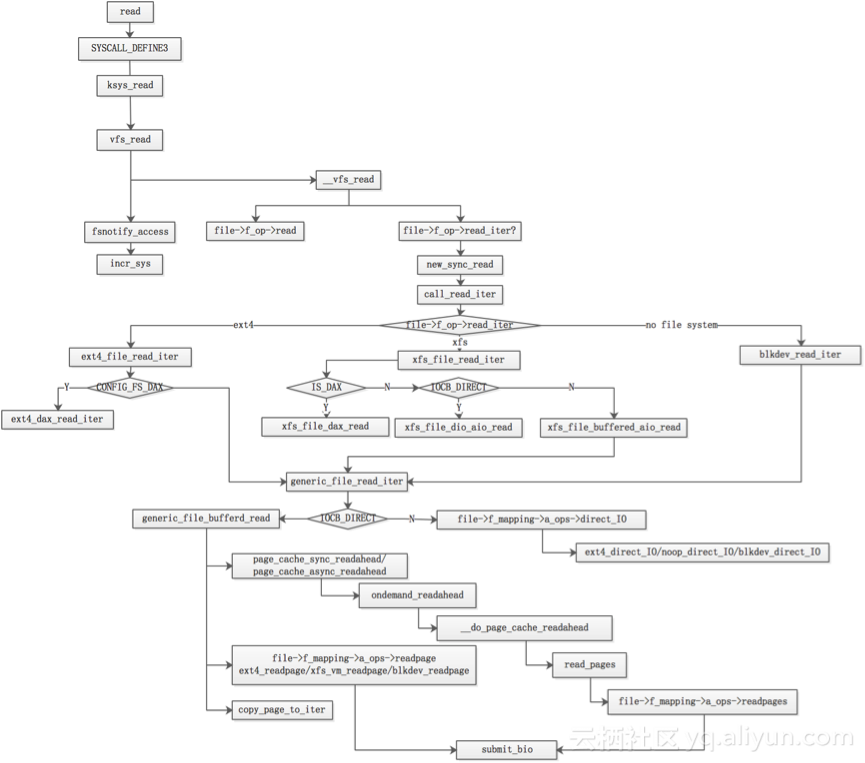
读逻辑的高清图如下:
https://github.com/kernel-z/filesystem/blob/master/vfs_read.png
3 Linux文件系统剖析:文件写操作
从上篇中我们了解了文件系统的读操作,虽然在内核代码中非常复杂,但是变成逻辑流程图后还是非常直观的。读操作中主要是针对有page cahce的,直接读的逻辑并未详尽展示,本文的写操作也遵循此逻辑。一方面让逻辑更加清晰明了,另一方面是让篇章更有侧重点,而不会出现顾此失彼。
下面我们来看下系统的文件读操作,内核版本基于4.17.2。
1.9 系统调用入口
和系统中的读操作一样,系统的写操作也是从系统调用write开始,其系统调用如下:
SYSCALL_DEFINE3(write, unsigned int, fd, const char __user *, buf,
size_t, count)
{
return ksys_write(fd, buf, count);
}
其逻辑同读操作基本是一致的,此处也是调用ksys_write函数,该函数如下,逻辑同读操作并无二:
ssize_t ksys_write(unsigned int fd, const char __user *buf, size_t count)
{
struct fd f = fdget_pos(fd);
ssize_t ret = -EBADF;
if (f.file) {
loff_t pos = file_pos_read(f.file);
ret = vfs_write(f.file, buf, count, &pos);
if (ret >= 0)
file_pos_write(f.file, pos);
fdput_pos(f);
}
return ret;
}
1.10 vfs_write
函数接着是调用vfs_write,如下,会做一些写之前的检测,最后会更新进程中的静态统计:
ssize_t vfs_write(struct file *file, const char __user *buf, size_t count, loff_t *pos)
{
ssize_t ret;
if (!(file->f_mode & FMODE_WRITE))
return -EBADF;
if (!(file->f_mode & FMODE_CAN_WRITE))
return -EINVAL;
if (unlikely(!access_ok(VERIFY_READ, buf, count)))
return -EFAULT;
ret = rw_verify_area(WRITE, file, pos, count);
if (!ret) {
if (count > MAX_RW_COUNT)
count = MAX_RW_COUNT;
file_start_write(file);
ret = __vfs_write(file, buf, count, pos);
if (ret > 0) {
fsnotify_modify(file);
add_wchar(current, ret);
}
inc_syscw(current);
file_end_write(file);
}
return ret;
}
__vfs_write函数的调用如下,函数中会使用file_operations中实现的函数,先判断是否有.write函数,如果没有则判断时候有.write_iter函数,如果有则调用new_sync_write函数。
ssize_t __vfs_write(struct file *file, const char __user *p, size_t count,
loff_t *pos)
{
if (file->f_op->write)
return file->f_op->write(file, p, count, pos);
else if (file->f_op->write_iter)
return new_sync_write(file, p, count, pos);
else
return -EINVAL;
}
在new_sync_write函数中,会初始化kiocb,并调用函数call_write_iter。
call_write_iter函数会调用file->f_op->write_iter,不同文件系统有不同对应的函数,数据结构体如上篇读中多列。Ext4为函数ext4_write_iter,xfs文件系统为xfs_file_write_iter,无文件系统默认的操作为blkdev_write_iter。根据不同的文件系统出现分支。
1.11 __generic_file_write_iter
在ext4_write_iter函数中,会调用函数__generic_file_write_iter,该函数会将数据写到文件中。该函数中判断IOCB_DIRECT,如果是直接写的最后需要调用filemap_write_and_wait_range函数将page cache中的页刷入到磁盘,并无效化映射的页。
如果不是IOCB_DIRECT,则直接调用generic_perform_write函数。
1.12 generic_perform_write
该函数是ext4文件系统和裸设备写操作的核心,在generic_perform_write函数中,会循环的调用iov_iter_copy_from_user_atomic函数,将数据从用户层复制到内核。其中内核接收用户层数据的时候,使用了结构体iov_iter,代码如下:
struct iov_iter {
int type;//迭代器类型
size_t iov_offset;// 第一个iovec中,第一个字节的偏移
size_t count;
union {
const struct iovec *iov;
const struct kvec *kvec;
const struct bio_vec *bvec;
struct pipe_inode_info *pipe;
};
union {
unsigned long nr_segs;
struct {
int idx;
int start_idx;
};
};
};
iov_iter结构体其实是iovec的迭代器,iovec描述了在物理内存或虚拟内存中分散的缓存buffer。通过iov_iter迭代器可以一次进行数据传输的处理非常高效。
struct iovec
{
void __user *iov_base; /* BSD uses caddr_t (1003.1g requires void *) */
__kernel_size_t iov_len; /* Must be size_t (1003.1g) */
};
iov_iter结构体从2007年的2.6.24引入,已逐渐成为处理用户层缓存的标准方法。具体可以参考链接。
不过在执行iov_iter_copy_from_user_atomic函数执行会调用a_ops->write_begin来将数据读入到缓存中,执行完毕后需要将页标记为脏,因为并没有直接刷入到磁盘,这是和直接IO存在差异的地方。
最后结束后,需要调用函数generic_write_sync,如果是IOCB_DSYNC需要调用函数vfs_fsync_range来同步写。
1.13 XFS文件系统写
xfs文件系统与ext4和裸设备存在较大差异,其核心函数是iomap_file_buffered_write。该函数引入的一个参数是操作函数结构体iomap_ops如下,指定了两个函数:
const struct iomap_ops xfs_iomap_ops = {
.iomap_begin = xfs_file_iomap_begin,
.iomap_end = xfs_file_iomap_end,
};
这两个函数类似在ext4文件系统中的a_ops->write_begin和a_ops->write_end。
xfs_file_iomap_begin会根据IS_DAX(inode),如果不是直接IO,则直接调用函数xfs_file_iomap_begin_delay,然后通过函数iomap_write_actor(调用iov_iter_copy_from_user_atomic)将数据从用户态复制到内核态。
最后刷IO是在file结构体对象释放时候,调用file_operations中指定的.release函数, Ext4文件系统对应的release函数是ext4_release,xfs文件系统对应的release函数是xfs_file_release, 通用块对应的release函数是blkdev_close。Release函数会触发调用aops->write_pages,最后都会调用submit_bio函数。
这样不会每次io都提交一个请求给块设备,在可扩展性方面得到了较大的提升。
1.14 逻辑流程
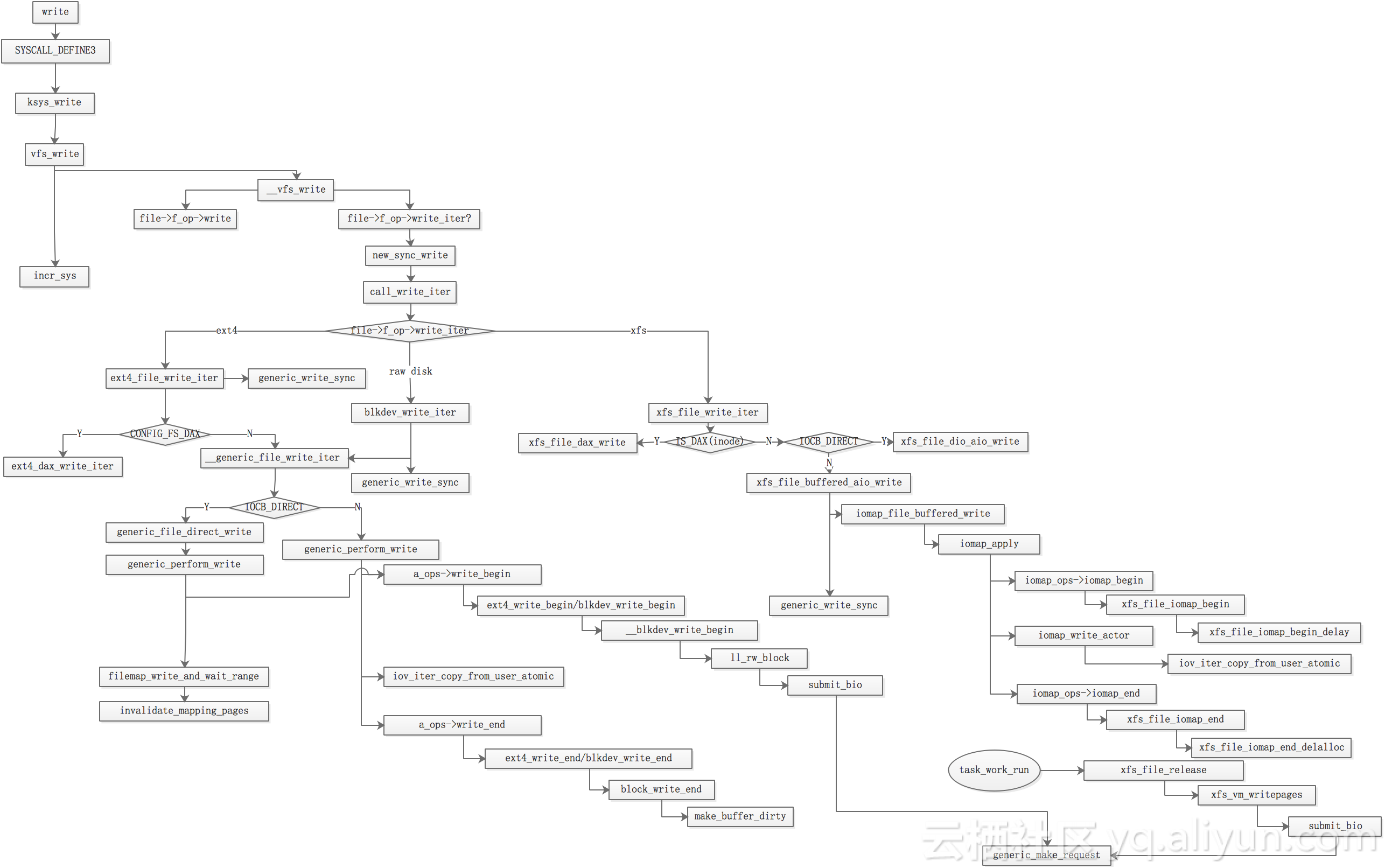
高清图链接如下:
https://github.com/kernel-z/filesystem/blob/master/vfs_write.png
4 小结
本篇基于内核4.17.2, 将linux虚拟文件系统的打开、读和写整体逻辑梳理了一下,主要的函数均已提炼,此外还具体列出了ext4, xfs和裸设备的相关函数。
不过文中并没有展开直接IO的逻辑,另外关于内核代码的细节并没有详细展开,主要是考虑到任何一个细节部分都有大文章可以写,而本篇偏重逻辑和流程。关于其他细节例如缓存具体实现机制、IO合并、拆分、阻塞控制等,后续会有更详细的文章来进行补充。
5 参考
XFS:the filesystem of the future?

{kind=link}
{kind=link}