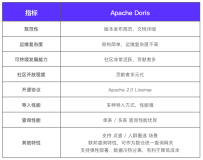
本文说明如何设计一个 ETL 作业以便将在线关系数据库里的数据,加载到阿里云的Greenplum 数据库中,如何调度和监控该ETL 作业的日常运行。
本文使用的软件是开源ETL 工具软件 Kettle 5.x,以及基于Kettle的傲飞数据整合平台,该平台可以用来Kettle作业的调度、监控等功能、并可以完成数据源管理等功能。
软件下载安装
1. Java 1.6 或 1.7
2. 傲飞数据整合平台的下载地址(包含了 Kettle和服务端):http://pan.baidu.com/s/1cmSPEe
解压缩即可安装,平台的安装配置方法见下载文档内的《傲飞数据整合平台使用说明书》
3. 安装 Mysql 数据库 5.1 或以上版本,并以 UTF-8 编码新建一个数据库 etl_platform,
上述软件都要事先安装部署到阿里 ECS 上。
ETL 作业配置
服务端配置
资源库配置
资源库是Kettle 里保存作业的数据库。首先登陆傲飞数据整合平台(默认用户名,密码 admin/admin),在傲飞数据整合平台的【资源库管理】里,新创建一个资源库,资源库的数据库名称使用事先创建的 etl_platform 数据库,注意数据库地址要用外网的ip地址,因为将来kettle 客户端会连接该ip 地址。
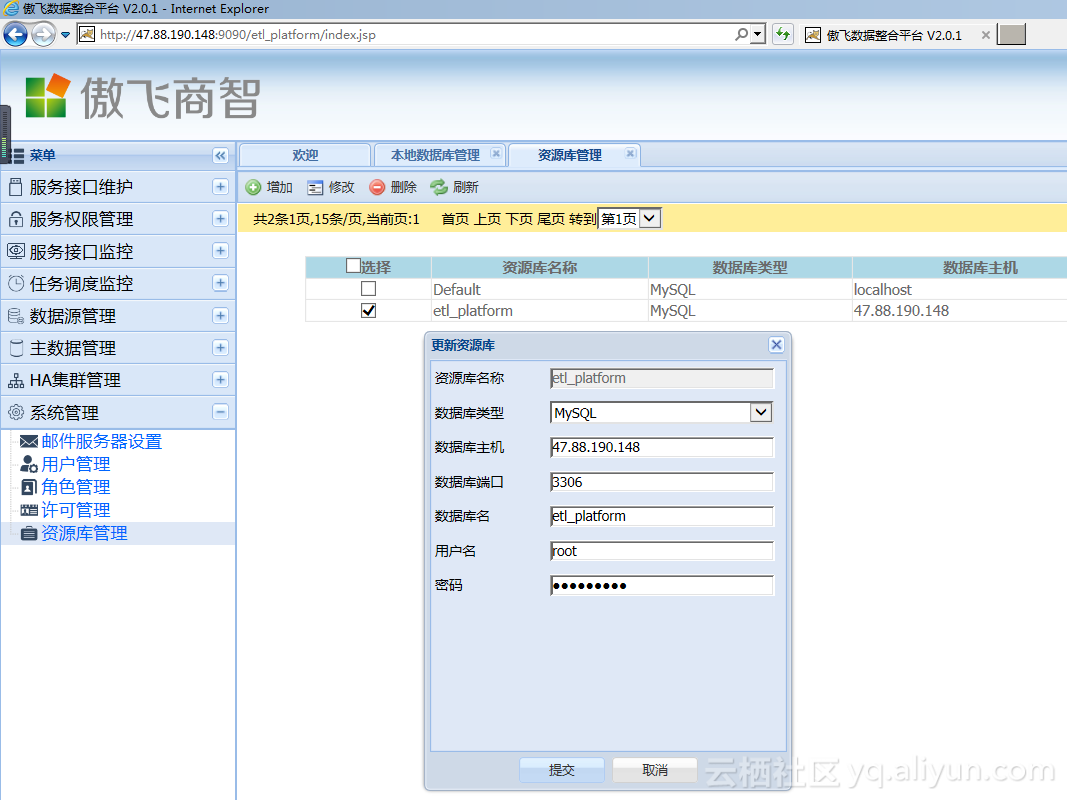
数据库配置
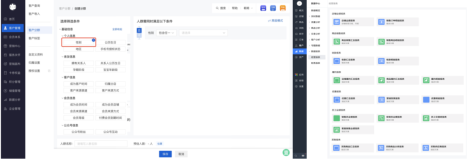
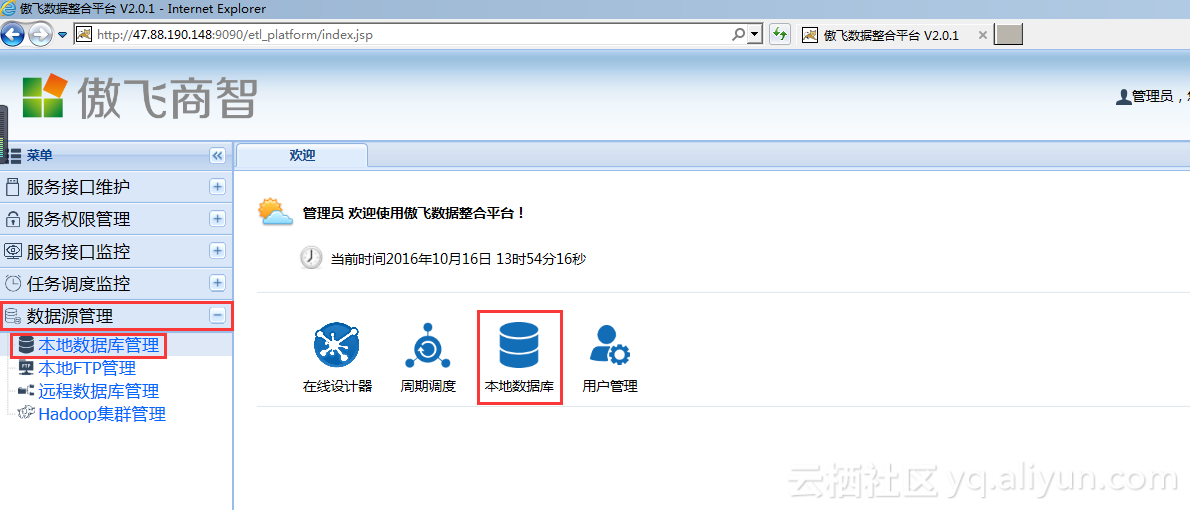
选择主窗口左侧菜单的【数据源管理】里的【本地数据库管理】,或者直接在登陆首页中选择【本地数据库】快捷图标。如下图:
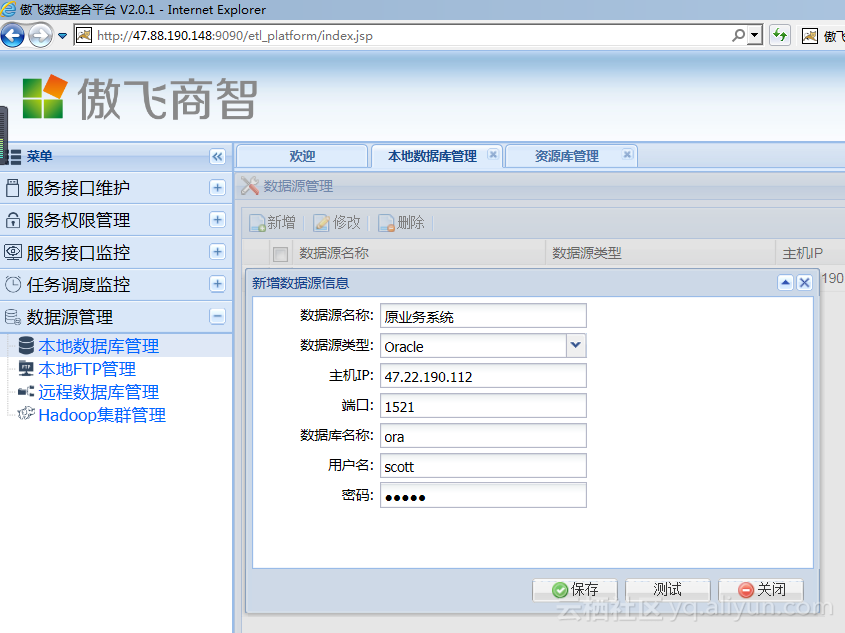
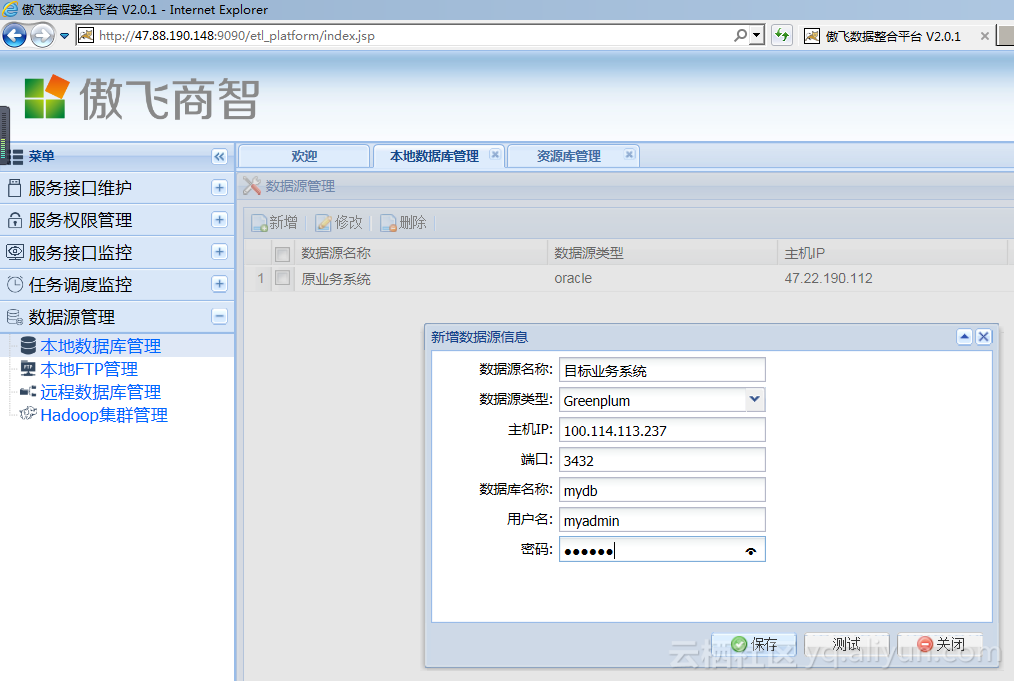
选择【新增】,在【新增数据源信息】窗口中设置两个数据源,一个是原数据源,另一个是要加载到的阿里云Greenplum 数据源,数据源配置参考如下图所示:
客户端设置
登陆
双击spoon.bat 文件,启动spoon,在登陆窗口中输入傲飞数据整合平台的URL ,用户名和密码,如下图:
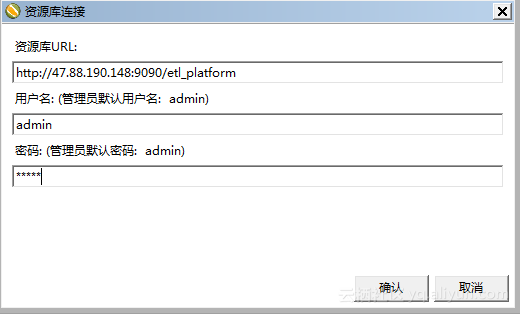
选择资源库
如果登陆成功,会出现【资源库连接】选择框,这里选择我们刚创建的资源库,如下图:
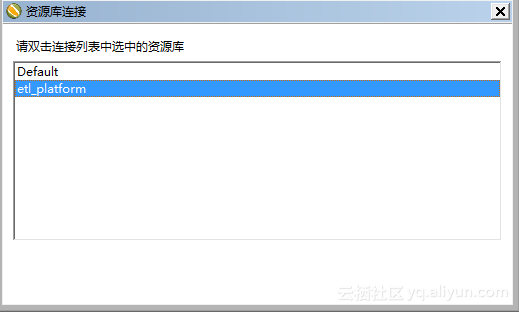
设计转换
进入资源库后,在设计窗口中选择【文件】->【新建】->【转换】,如下图:
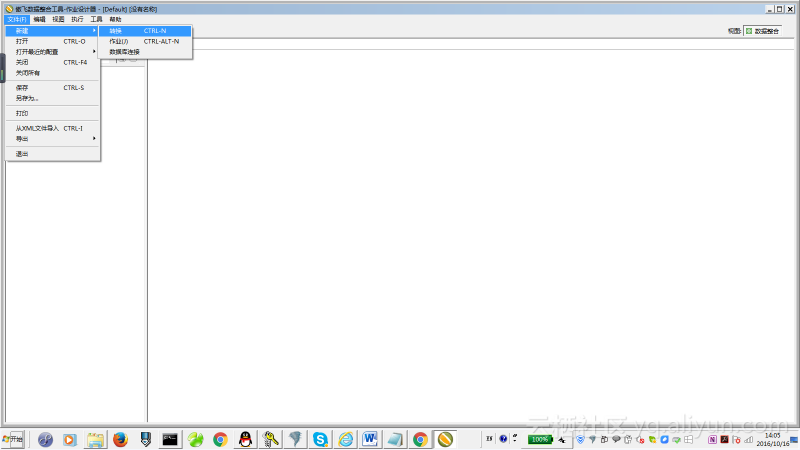
SQL 方式加载
如果要使用SQL 方式加载,要拖拽【表输入】步骤和【表输出】步骤到画布上,并连线(按住Shift键,同时移动鼠标),在表输入步骤中配置SQL 语句,在表输出步骤中配置输出表的名称即可,如下图:
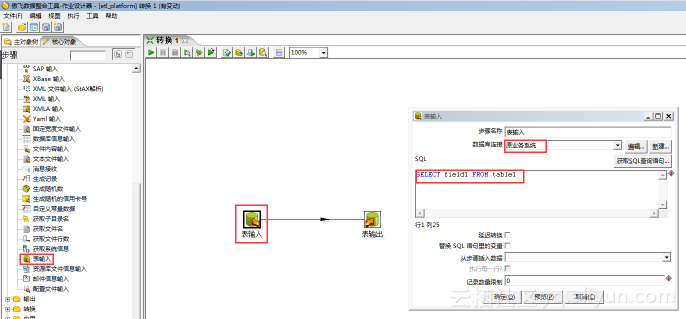
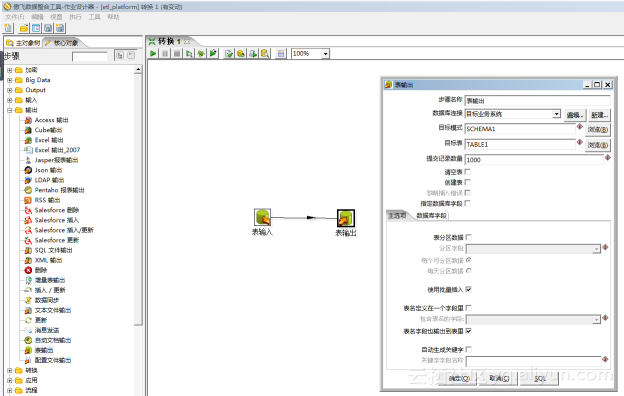
如果需要在输入和输出之间做各种数据格式转换,数据清洗,拆分,组合等各种操作,要使用Spoon 设计器里提供的各种步骤(连数成金论坛有 Kettle 培训课程)
使用Copy 方式加载
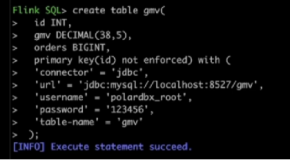
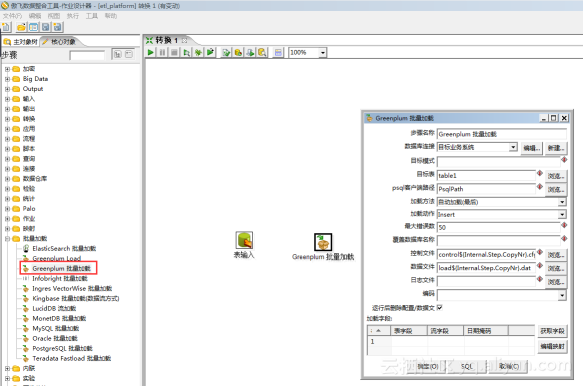
当大量数据时,可以使用 【Greenplum 批量加载】步骤完成加载,Greenplum 批量加载使用了Copy 命令方式加载,加载速度比SQL 方式快。【Greenplum 批量加载】步骤的配置如下图所示:
使用OSS 方式加载
OSS 是阿里云对象存储服务(Object Storage Service,简称OSS),是阿里云对外提供的海量,安全,低成本,高可靠的云存储服务。目前Kettle 对OSS的支持还在开发中。 不过目前用户也可以手动将文件上传到 OSS 服务中,使用类似下面的SQL 创建一个基于OSS的外部表。
1. create READABLE external table ossexample
2. (date text, time text, open float, high float,
3. low float, volume int)
4. location('oss://oss-cn-hangzhou.aliyuncs.com
5. filepath=osstest/example.csv id=XXX
6. key=XXX bucket=testbucket') FORMAT 'csv'
7. LOG ERRORS SEGMENT REJECT LIMIT 5;
关于OSS 的加载,请参考:https://help.aliyun.com/document_detail/35457.html
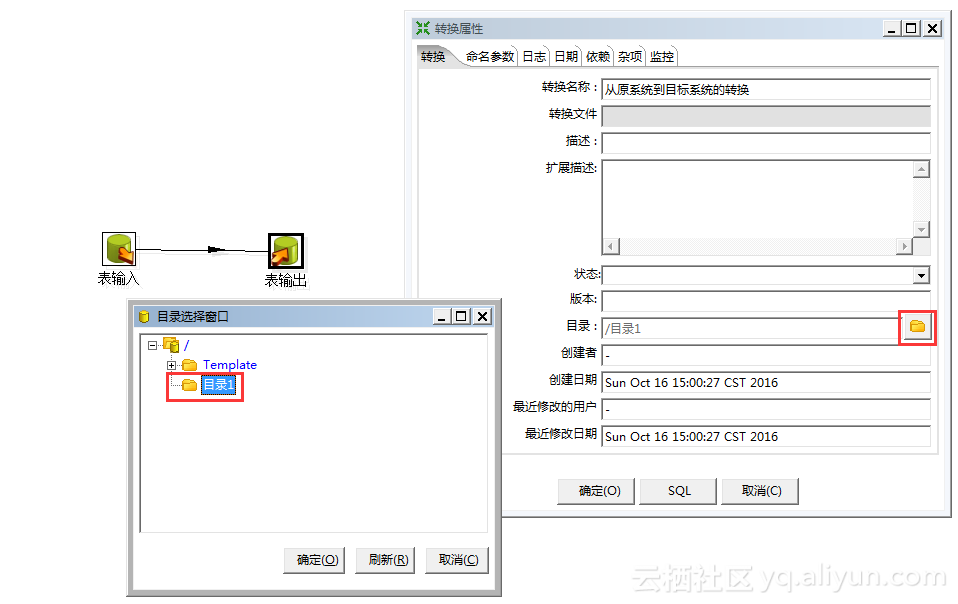
保存转换:
选择【文件】->【另存为】 ,在【转换属性】窗口中,设置转换名称:从原系统到目标系统的转换,在【目录】输入框选择要保存的资源库目录,如下图
点【确定】后,把作业保存到资源库中。
注意:
如果客户端长时间不操作,服务端会自动断开和客户端的连接。 此时从客户端保存到服务端时可能报告数据库连接错误。如果发生此类错误,只需先资源库连接,再重新连接资源库即可。
调度
在【周期调度】里选择【增加普通调度】选项,在【新增调度】窗口里选择作业“从原系统到目标系统的转换”,如下图:
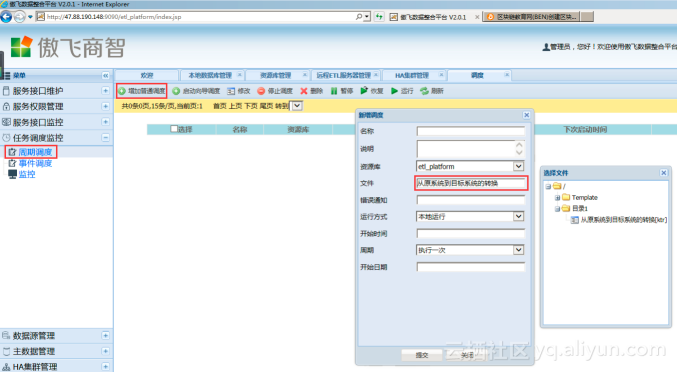
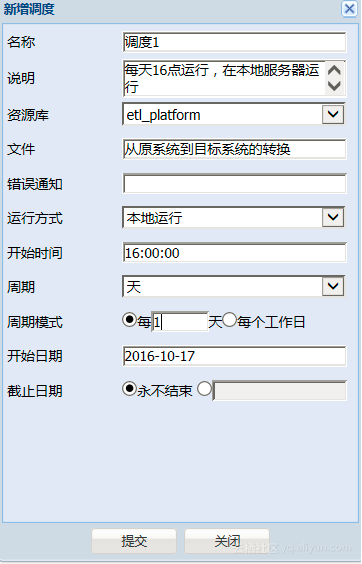
选择运行方式【本地运行】,并设置调度方式为每天的16:00 运行,如下图:
运行
新增加的调度可以按照设置好的调度方式运行,也可以通过点击【运行】按钮,手动运行,如下图:

监控

无论手工还是调度运行,在监控列表里都会有作业的运行状态,运行时间,错误日志等信息。
待续
关于如何将企业内网数据库里的数据,加载到阿里云的greenplum 中,下文继续。