摘要:Storm的编程模型是一个有向无环图,决定了storm的spout接收到外部系统的请求后,spout并不能得到bolt的处理结果并将结果返回给外部请求。所以也就决定了storm无法提供对外部系统的同步调用功能。
最近新的黑名单项目需要在storm实时计算平台上提供对外部系统请求调用的同步响应(也就是让storm支持同步调用而不是回调),而Storm的编程模型是一个有向无环图,也就决定了storm的spout接收到外部系统的请求后,将请求数据分发给下游的bolt进行处理后,spout并不能得到bolt的处理结果并将结果返回给外部请求。
在传统也就是业界大部分应用场景storm对外部系统的调用都是采用回调的方式。本人之前参与的某4000万用户,日均1000万交易量的信用卡中心也是采用回调的方式。
原文和作者一起讨论:http://www.cnblogs.com/intsmaze/p/7602242.html

storm常见回调设计方案
首先jetty,tomcat等启动服务,接收外部系统的请求,将请求得到的数据发往kafka,activeMQ等消息队列中,就立马响应给外部系统。
然后storm实时平台去消息队列中拉取数据并进行分布式并行处理,然后将运算完的结果存入第三方存储介质(外部系统直接通过读取该介质获取结果)或者调用外部系统的接口将处理的结果推送出去(以回调的方式实现伪同步请求)。
目前的需求
这个时候当然就是去storm的官网去看看有没有对应的高级接口,果不其然看到了DRPC,熟悉RPC的就知道就是远程过程调用,就是向远程系统发送socket请求并得到远程系统处理的结果,那么DPRC也就是分布式远程过程调用而已,那么他就一定提供了同步请求响应的功能。
关于DRPC在文章末尾会简单演示一下,这里重点说下我对storm的DRPC的原理理解。上面我也说了storm的编程模型是一个有向无环图,从模型的角度来说是不可能支持同步请求的功能的。
自己如何基于storm实现同步调用
问题一:storm的计算模型的拓扑结构是一个有向无环图,处理的结果并不会返回给spout节点。
我可以让bolt将处理的结果存入redis,然后spout不断轮询去redis读取对应的结果并返回!
貌似可以,但是查看spout的调用源代码会发现,如果这样会导致spout的吞吐量下降,因为spout只有从redis轮询到当次请求的处理结果后才会在循环调用nextTuple()方法,当然在spout实现类中开启多线程后,貌似可以解决nextTuple方法阻塞(具体没有去想,因为本身这个方案不可行了,就没必须去掉头发了)storm的任务中再去开多线程是无效率的,还不如不选择storm技术。
问题二:spout节点启动的机器是不固定的,ip是会变化的,则对外部系统调用时ip的维护带来了麻烦,所以这种方案不可取。
public void nextTuple() {
获取请求的数据
collector.emit();
while(true)
{
去redis中读取该次请求的结果,读到则结束循环
}
}
方案二:抛开storm实时平台,单独开发一套中转程序,负责接收外部系统的请求,将外部请求的参数存入一个先进先出的队列中,阻塞等待storm处理的结果。storm拓扑的spout中创建socket去连接中转程序,中转程序从队列中拿出请求参数返回给spout。spout获取到请求参数后,将参数传给下游的bolt去计算,下游的最后一层bolt计算完也创建socke去连接中转程序并将结果发送给中转程序。中转程序获得bolt返回结果,存入某个地方,然后中转程序中阻塞的地方轮询得到结果后,就结束轮询响应给外部系统了。
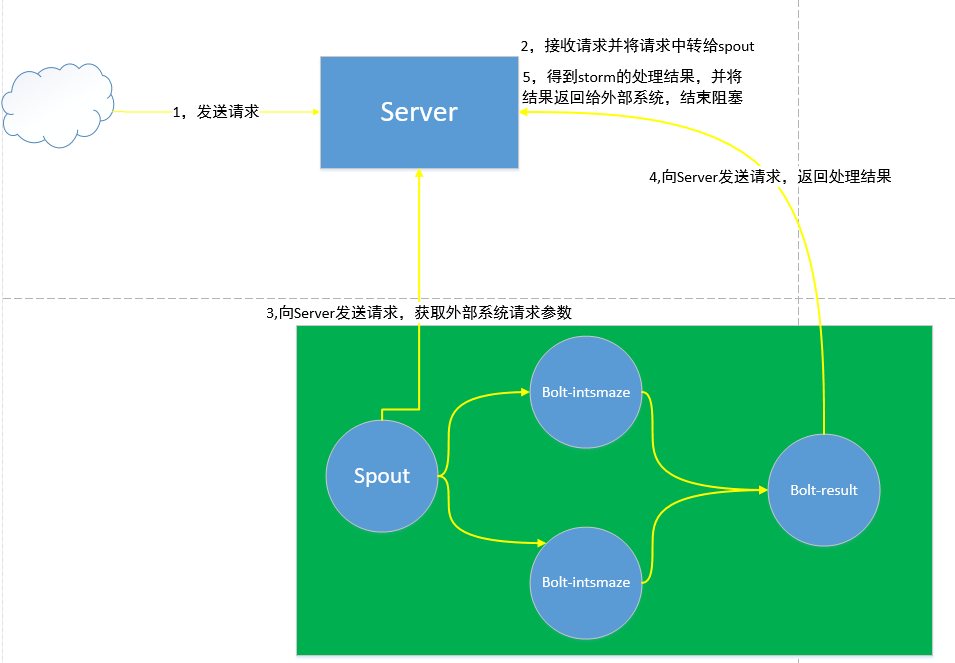
当然这只是一个简单的方案设计,具体还有很多细节设计以及考虑在我们的Server端,因为它要同时协调三个不同的程序的请求,并且能够根据以每一个请求自动聚合外部系统请求,spout请求,bolt请求为一组。
Storm的DRPC概述
storm的DRPC其实就实现外部系统同步调用storm实时平台的功能组件了。应该不需要我去从零开发了。接下来就看看storm的DPRC功能是否和我当初的想法是否一致!
官方话语:
分布式RPC(DRPC)背后的思想是将真正强大功能的计算与storm的计算并行化。Storm拓扑以一个函数参数的流作为输入,它向每个函数调用发出一个输出流的结果。
分布式RPC(DRPC)的真正目的是使用storm实时并行计算极端功能。Storm拓扑需要一个输入流作为函数参数,以一个输出流的形式发射每个函数调用的结果。。从一个客户端的角度来看,一个分布式RPC调用就像是一个常规的RPC调用。
分布式RPC工作流程如下图所示:
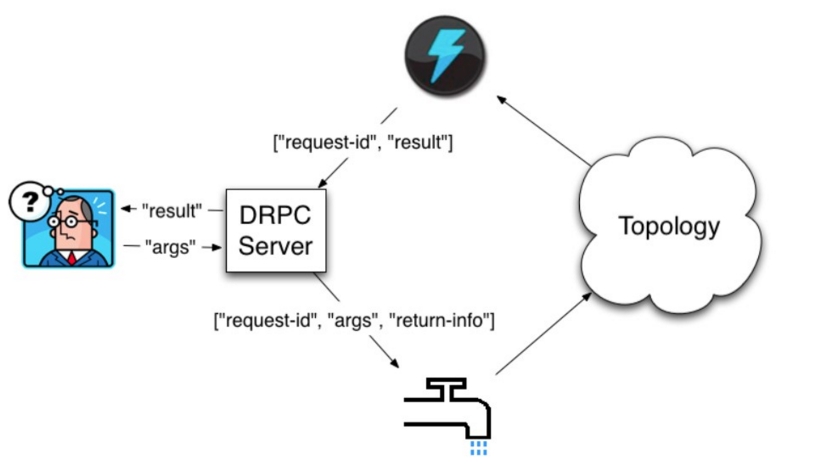
客户端程序会向启动的DRPC服务器发送要执行的函数名称和该函数的参数。具备DRPC功能的拓扑会使用一个DRPCSpout接收来自DRPC服务器传来的函数调用流。每个函数调用都用一个惟一的id标记在DRPC服务器上。拓扑计算好结果后会由一个名为ReturnResults的bolt去连接DRPC服务器给出对应函数调用id的结果,然后DRPC服务器根据ID找到等待中的客户端,为等待中的客户端消除阻塞,并发送结果给客户端。
从一个客户端的角度来看,一个分布式RPC调用就像是一个常规的RPC调用。
public class Client { public static void main(String[] args) throws TException, DRPCExecutionException { DRPCClient client = new DRPCClient("192.168.19.131", 3772); for (int i = 0; i < 10; i++) { System.out.println(i); String result = client.execute("method_name","param is intsmaze--"+i+"---"); System.out.println(result); } client.close(); } }
下一篇将会重点讲解如何运行storm的drpc示例,并剖析它的内部实现原理来验证是否和本文的猜想一致。
