
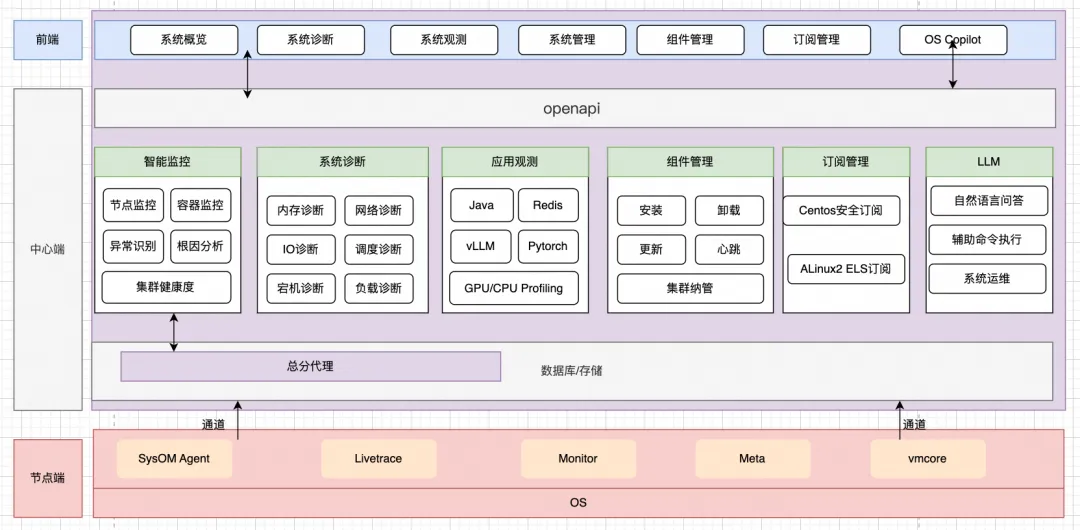
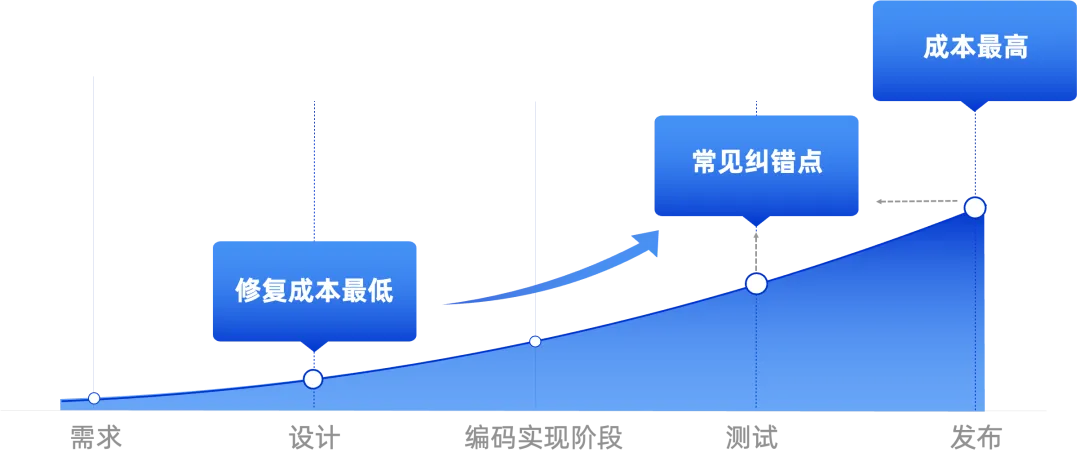
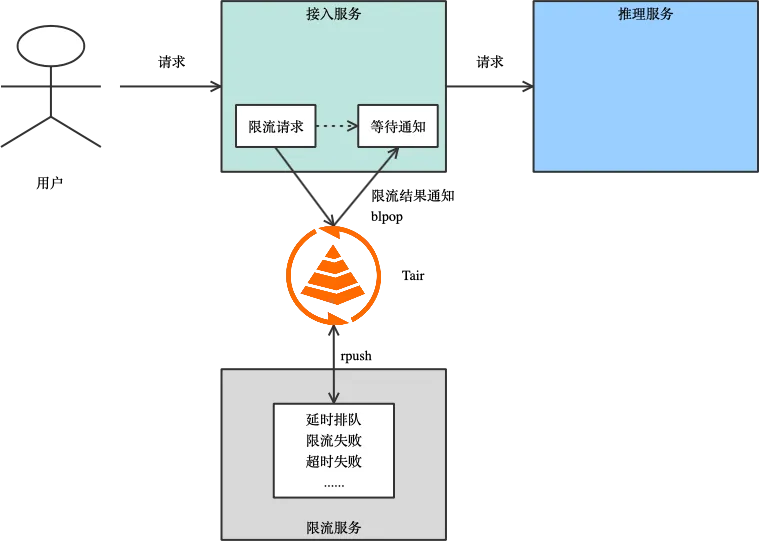
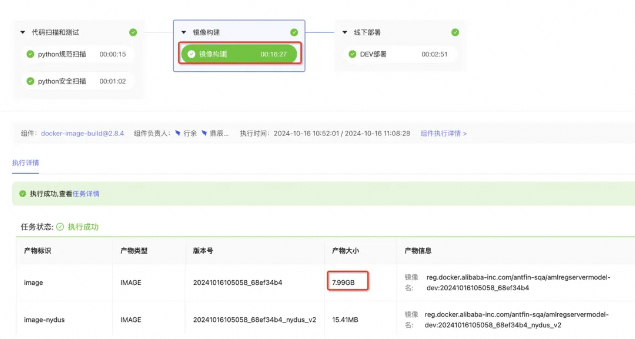
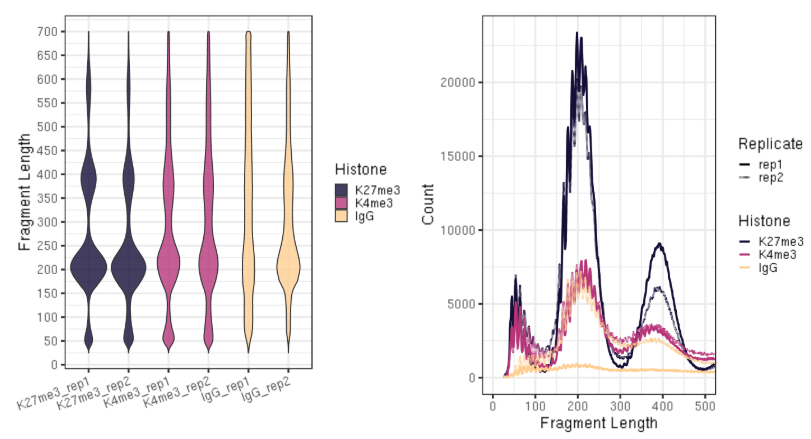
解决隐式内存占用难题

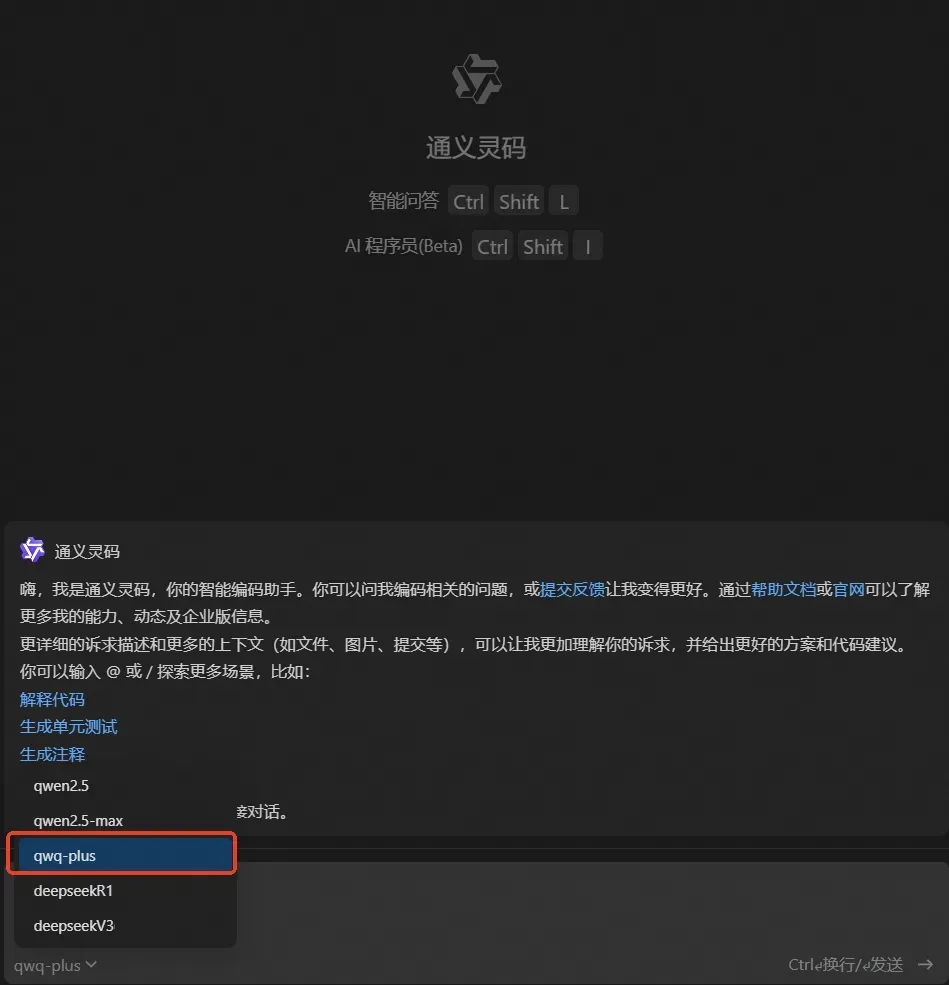

























你好,我是AI助理
可以解答问题、推荐解决方案等
