一、概念
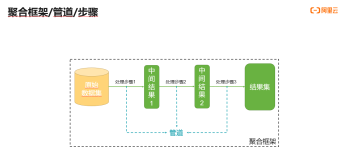
使用聚合框架可以对集合中的文档进行变换和组合。基本上,可以用多个构件创建一个管道(pipeline),用于对一连串的文档进行处理。这些构件包括筛选(filtering)、投射(projecting)、分组(grouping)、排序(sorting)、限制(limiting)和跳过(skipping)。
二、聚合函数
db.driverLocation.aggregate( {"$match":{"areaCode":"350203"}}, {"$project":{"driverUuid":1,"uploadTime":1,"positionType":1}}, {"$group":{"_id":{"driverUuid":"$driverUuid","positionType":"$positionType"},"uploadTime":{"$first":{"$year":"$uploadTime"}},"count":{"$sum":1}}}, {"$sort":{"count":-1}}, {"$limit":100}, {"$skip":50} )
管道操作符是按照书写的顺序依次执行的,每个操作符都会接受一连串的文档,对这些文档做一些类型转换,最后将转换后的文档作为结果传递给下一个操作符(对于最后一个管道操作符,是将结果返回给客户端),称为流式工作方式。
大部分操作符的工作方式都是流式的,只要有新文档进入,就可以对新文档进行处理,但是"$group" 和 "$sort" 必须要等收到所有的文档之后,才能对文档进行分组排序,然后才能将各个分组发送给管道中的下一个操作符。这意味着,在分片的情况下,"$group" 或 "$sort"会先在每个分片上执行,然后各个分片上的分组结果会被发送到mongos再进行最后的统一分组,剩余的管道工作也都是在mongos(而不是在分片)上运行的。
不同的管道操作符可以按任意顺序组合在一起使用,而且可以被重复任意多次。例如,可以先做"$match",然后做"$group",然后再做"$match"(与之前的"$match"匹配不同的查询条件)。
$fieldname"语法是为了在聚合框架中引用fieldname字段。
- 筛选(filtering)—> $match
用于对文档集合进行筛选,之后就可以在筛选得到的文档子集上做聚合。例如,如果想对Oregon(俄勒冈州,简写为OR)的用户做统计,就可以使用{$match : {"state" :"OR"}}。"$match"可以使用所有常规的查询操作符("$gt"、"$lt"、"$in"等)。有一个例外需要注意:不能在"$match"中使用地理空间操作符。
通常,在实际使用中应该尽可能将"$match"放在管道的前面位置。这样做有两个好处:一是可以快速将不需要的文档过滤掉,以减少管道的工作量;二是如果在投射和分组之前执行"$match",查询可以使用索引。
- 投射(projecting)—> $project
这个语法与查询中的字段选择器比较像:可以通过指定 {"fieldname" : 1} 选择需要投射的字段,或者通过指定 { "fieldname":0 } 排除不需要的字段。执行完这个"$project"操作之后,结果集中的每个文档都会以{"_id" : id, "fieldname" :"xxx"}这样的形式表示。这些结果只会在内存中存在,不会被写入磁盘。
还可以对字段进行重命名:db.users.aggregate({"$project" : {"userId" : "$_id", "_id" : 0}}),在对字段进行重命名时,MongoDB并不会记录字段的历史名称。
- 分组(grouping)—> $group
如果选定了需要进行分组的字段,就可以将选定的字段传递给"$group"函数的"_id"字段。对于上面的例子:我们选择了driverUuid 和 positionType 当作我们分组的条件(当然只选择一个字段也是可以的)。分组过后,文档的 driverUuid 和 positionType 组成的对象就变成了文档的唯一标识(_id)。
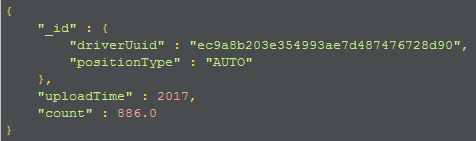
"count":{"$sum":1} 是为分组内每个文档的"count"字段加1。注意,新加入的文档中并不会有"count"字段;这"$group"创建的一个新字段。
- 排序(sorting)—> $sort
排序方向可以是1(升序)和 -1(降序)。
可以根据任何字段(或者多个字段)进行排序,与在普通查询中的语法相同。如果要对大量的文档进行排序,强烈建议在管道的第一阶段进行排序,这时的排序操作可以使用索引。否则,排序过程就会比较慢,而且会占用大量内存。
- 限制(limiting)—> $limit
$limit会接受一个数字n,返回结果集中的前n个文档。
- 跳过(skipping)—> $skip
$skip也是接受一个数字n,丢弃结果集中的前n个文档,将剩余文档作为结果返回。在“普通”查询中,如果需要跳过大量的数据,那么这个操作符的效率会很低。在聚合中也是如此,因为它必须要先匹配到所有需要跳过的文档,然后再将这些文档丢弃。
- 拆分(unwind)—> $unwind
可以将数组中的每一个值拆分为单独的文档。
例如文档:{ "_id" : 1, "item" : "ABC1", sizes: [ "S", "M", "L"] }
聚合运算:db.inventory.aggregate( [ { $unwind : "$sizes" } ] )
结果:
{ "_id" : 1, "item" : "ABC1", "sizes" : "S" }
{ "_id" : 1, "item" : "ABC1", "sizes" : "M" }
{ "_id" : 1, "item" : "ABC1", "sizes" : "L" }
Spring Data MongoDB 中使用聚合函数:
/** * db.driverLocation.aggregate( * {"$match":{"areaCode":"350203"}}, * {"$project":{"driverUuid":1,"uploadTime":1,"positionType":1}}, * {"$group":{"_id":{"driverUuid":"$driverUuid","positionType":"$positionType"},"uploadTime":{"$first":{"$year":"$uploadTime"}},"count":{"$sum":1}}}, * {"$sort":{"count":-1}}, * {"$limit":100}, * {"$skip":50} * ) */ @Test public void test04(){ //match Criteria criteria = Criteria.where("350203").is("350203"); AggregationOperation matchOperation = Aggregation.match(criteria); //project AggregationOperation projectionOperation = Aggregation.project("driverUuid", "uploadTime", "positionType"); //group AggregationOperation groupOperation = Aggregation.group("driverUuid", "positionType") .first(DateOperators.dateOf("uploadTime").year()).as("uploadTime") .count().as("count"); //sort Sort sort = new Sort(Sort.Direction.DESC, "count"); AggregationOperation sortOperation = Aggregation.sort(sort); //limit AggregationOperation limitOperation = Aggregation.limit(100L); //skip AggregationOperation skipOperation = Aggregation.skip(50L); Aggregation aggregation = Aggregation.newAggregation(matchOperation, projectionOperation, groupOperation, sortOperation, limitOperation, skipOperation); AggregationResults<Object> driverLocation = mongoOperations.aggregate(aggregation, "driverLocation", Object.class); List<Object> mappedResults = driverLocation.getMappedResults(); }
三、聚合管道操作符
MongoDB提供了很多的操作符用来文档聚合后字段间的运算或者分组内的统计,比如上文提到的$sum、$first、$year 等。MongoDB提供了包括分组操作符、数学操作符、日期操作符、字符串表达式 等等 一系列的操作符...
- 分组操作符
类似 SQL中分组后的操作,只适用于分组后的统计工作,不适用于单个文档。
- {"$sum" : value} 对于分组中的每一个文档,将value与计算结果相加。
- {"$avg" : value} 返回每个分组的平均值
- {"$max" : expr} 返回分组内的最大值。
- {"$min" : expr} 返回分组内的最小值。
- {"$first" : expr} 返回分组的第一个值,忽略后面所有值。只有排序之后,明确知道数据顺序时这个操作才有意义。
- {"$last" : expr} 与"$first"相反,返回分组的最后一个值。
- {"$addToSet" : expr} 针对数组字段, 如果当前数组中不包含expr ,那就将它添加到数组中。在返回结果集中,每个元素最多只出现一次,而且元素的顺序是不确定的。
- {"$push" : expr} 针对数组字段,不管expr是什么值,都将它添加到数组中。返回包含所有值的数组。
- 数学操作符
适用于单个文档的运算。
- {"$add" : [expr1[, expr2, ..., exprN]]} 这个操作符接受一个或多个表达式作为参数,将这些表达式相加。
- {"$subtract" : [expr1, expr2]} 接受两个表达式作为参数,用第一个表达式减去第二个表达式作为结果。
- {"$multiply" : [expr1[, expr2, ..., exprN]]} 接受一个或者多个表达式,并且将它们相乘。
- {"$divide" : [expr1, expr2]} 接受两个表达式,用第一个表达式除以第二个表达式的商作为结果。
- {"$mod" : [expr1, expr2]} 接受两个表达式,将第一个表达式除以第二个表达式得到的余数作为结果。
- 字符串表达式
适用于单个文档的运算。
- {$substr" : [expr, startOffset, numToReturn]} 其中第一个参数expr必须是个字符串,这个操作会截取这个字符串的子串(从第startOffset字节开始的numToReturn字节,注意,是字节,不是字符。在多字节编码中尤其要注意这一点)expr必须是字符串。
- {"$concat" : [expr1[, expr2, ..., exprN]]} 将给定的表达式(或者字符串)连接在一起作为返回结果。
- {"$toLower" : expr} 参数expr必须是个字符串值,这个操作返回expr的小写形式。
- {"$toUpper" : expr} 参数expr必须是个字符串值,这个操作返回expr的大写形式。
- 逻辑表达式
适用于单个文档的运算,通过这些操作符,就可以在聚合中使用更复杂的逻辑,可以对不同数据执行不同的代码,得到不同的结果。
- {$cmp" : [expr1, expr2]} 比较expr1和expr2。如果expr1等于expr2,返回0;如果expr1 < expr2,返回一个负数;如果expr1 > expr2,返回一个正数。
- {"$strcasecmp" : [string1, string2]} 比较string1和string2,区分大小写。只对 ASCII 组成的字符串有效。
- {"$eq"/"$ne"/"$gt"/"$gte"/"$lt"/"$lte" : [expr1, expr2]} 对expr1和expr2执行相应的比较操作,返回比较的结果(true或false)。
- {"$and" : [expr1[, expr2, ..., exprN]]} 如果所有表达式的值都是true,那就返回true,否则返回false。
- {"$or" : [expr1[, expr2, ..., exprN]]} 只要有任意表达式的值为true,就返回true,否则返回false。
- {"$not" : expr} 对expr取反。
- {"$cond" : [booleanExpr, trueExpr, falseExpr]} 如果booleanExpr的值是true,那就返回trueExpr,否则返回falseExpr。
- {"$ifNull" : [expr, replacementExpr]} 如果expr是null,返回replacementExpr,否则返回expr。
- 日期表达式
适用于单个文档的运算,只能对日期类型的字段进行日期操作,不能对非日期类型字段做日期操作。
- {$year: "$date" } 返回日期的年份部分
- {$month: "$date" } 返回日期的月份部分
- {$dayOfMonth: "$date" } 返回日期的天部分
- {$hour: "$date" } 返回日期的小时部分
- {$minute: "$date" } 返回日期的分钟部分
- {$second: "$date" } 返回日期的秒部分
- {$millisecond: "$date" } 返回日期的毫秒部分
- {$dayOfYear: "$date" } 一年中的第几天
- {$dayOfWeek: "$date" } 一周中的第几天,between 1 (Sunday) and 7 (Saturday).
- {$week: "$date" } 以0到53之间的数字返回一年中日期的周数。周从星期日开始,第一周从一年中的第一个星期天开始。一年中第一个星期日之前的日子是在第0周。
可参考:https://docs.mongodb.com/manual/reference/operator/aggregation/
四、结语
应该尽量在管道的开始阶段(执行"$project"、"$group"或者"$unwind"操作之前)就将尽可能多的文档和字段过滤掉。管道如果不是直接从原先的集合中使用数据,那就无法在筛选和排序中使用索引。如果可能,聚合管道会尝试对操作进行排序,以便能够有效使用索引。
MongoDB不允许单一的聚合操作占用过多的系统内存:如果MongoDB发现某个聚合操作占用了20%以上的内存,这个操作就会直接输出错误。允许将输出结果利用管道放入一个集合中是为了方便以后使用(这样可以将所需的内存减至最小)。
这篇文章主要摘录自《MongoDB权威指南第二版》,Mongo系列的最后一篇文章了,最近学MongoDB学得头都有点大了,准备换个方向学学了...共勉!