2017云栖大会POLARDB专场,阿里云资深技术专家曹伟带来POLARDB云数据库分布式存储引擎揭秘的演讲。本文主要从计算和存储分离的优势谈起,然后说明控制平面与数据平面分离,接着分享了划时代的技术,包括零拷贝、并行副本等,最后解释了面向数据库优化的智能存储。
以下是精彩内容整理:
计算和存储分离的优势
如何把过去MySQL从单机磁盘数据库,演进成基于共享存储、集成数据库的核心组建Polar store。我们把三副本分布式的存储系统,做得延迟和本地SSD磁盘一样快,这就是核心的武器。那么,我们怎么做一个又快又稳定的分布式存储系统。
为什么做POLARDB时会选择把MySQL本地SSD单机数据库改造成一个基于共享存储集成数据库,在做了七年RDS之后选择做这件事。怎么去做一个高性能的分布式存储系统,同时让它稳定,我们为什么不用已有分布式存储系统,因为我们要在稳定系统和存储系统当中加入对数据库的理解优化,让它成为一个为数据库定制和优化的智能存储。
我们过去单机做数据库有一个很头疼的问题,怎么先做容量的预测,每台机器SSD容量的预测和迁移。在“双11”之前,我们一般会把核心用户的机器、数据库打散操作,把每个用户买每台数据库容量降低到60%以下,我们很担心“双11”那天大量数据进来,把机器塞满之后弄不出去。我需要预留40%-50%的SSD容量在那儿放着,存不了数据,就是为了避免突然的流量高峰把机器用满了,然后就要开始做迁移。
存储池化
在存储池化之后,我能用好每一块盘,为什么呢?因为今天的池子不再是单机十几T、几T,拥有的是几PB的大池子。在大池子当中加机器就OK了,整个大池子可以保持85%,90%左右。把存储池化之后,我们有一个大盘子了,就能把资源用得更好,TCO会下降。
计算存储硬件分离优化
过去做数据库的时候,每年很头疼的一件事情是定义明年新机型是什么,内存和存储的平易怎么控制,权衡之间的比例一直是很头疼的事情。
当我把计算的机型、数据库机型和存储机型分离之后,就能很好的进行优化。数据库的机型不需要再带SSD,存储机型不需要很好的CPU,也不需要很大的内存,但会有很多盘,单机存储力度可以很高。
数据库快速迁移能力
没有不坏的硬件,包括供电、机器、风扇、温度,硬件坏了之后,我们怎么把恢复时间指标往下降,保证用户可用时间往上走。在机器坏了的时候怎么能快速恢复,把数据库弄到一个好的机器上去跑,这个能力很重要,RDS的SLA是99.95%,这个时间很难保证。今天一份存储的成本给多个数据库节点也是我们获得的关键能力。
软件定义存储能力更强
为什么过去不这么做呢?过去分布式存储太慢,分布式存储都还停留在HTD的延时,你得到的延迟是几个毫秒,我们接受不了。因为数据库是非常敏感的。软件定义存储和普通机器上硬件SSD相比拥有更强的能力,比如单个盘可以任意扩容,可以从10TB扩容到100TB,100TB对于本级SSD来说很难达到,因为SSD的制造工艺也有瓶颈,能够放下的颗粒也是有限的,随机而来的单机SSD密度是有限的。
还有数据快照技术,我们在存储引入了分布式数据库快照技术做数据库的备份,完美解决了数据库备份。我可以在5分钟之内对100T数据库完成备份,还可以一个备份在5分钟之内挂载上去,成为一个新的实例,这些技术用传统的单机数据库是无法解决的。我们今天存储层做了一个Thin-provisioning技术,按需分配,拥有它后,有可能就可以按你使用的存储资源付钱了。
控制平面与数据平面分离
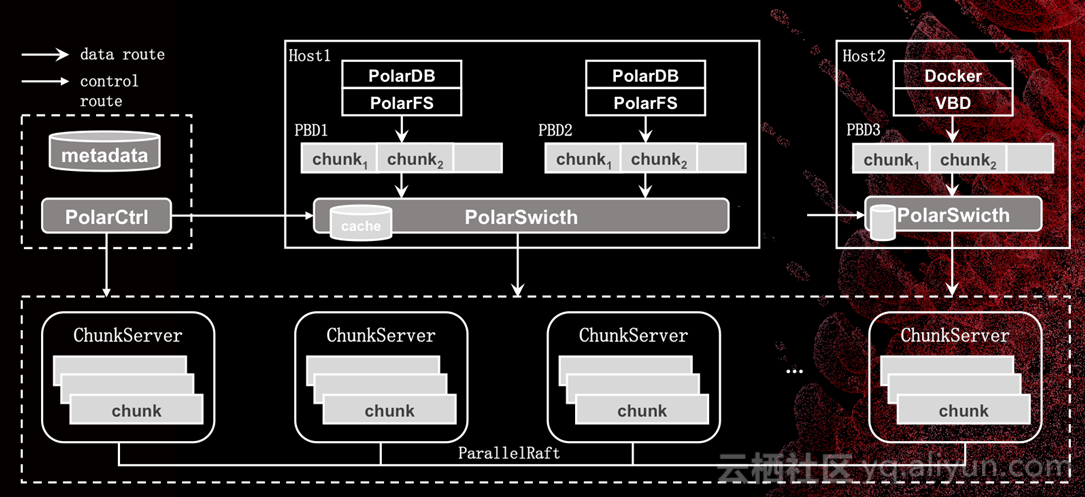
这样一个强大的分布式存储系统是怎么构建的呢?我们借鉴了SDN的经验,用控制平面与数据平面分离的思想在设计系统。简单来说,存储所有的复杂逻辑,比如故障怎么处理,副本策略如何,全都会在微服务实现的控制集群当中,数据平面非常高效的实现。
划时代技术,超高性能、超低延迟
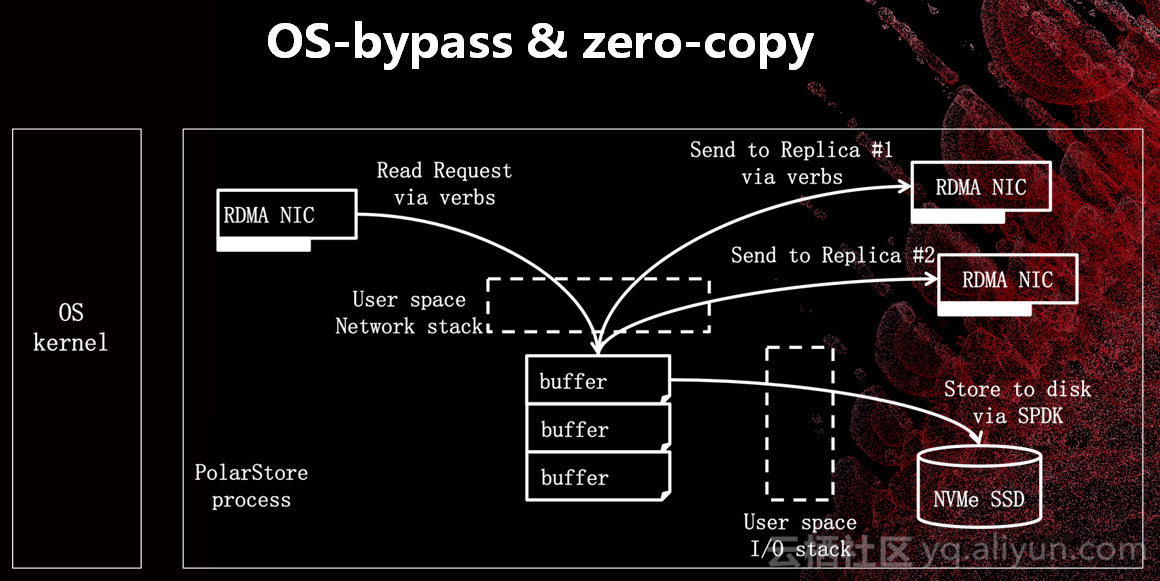
我们一些核心技术点如图,首先直接操作裸的RDMA网卡,自己实现一套完整网络协议栈和OR协议栈。零拷贝技术RDMA&SPDK、用户态文件系统和并行同步技术,我们紧贴着RDMA,在RDMA网络栈基础上实现了ParallelRaft。
我们是真正的零拷贝,别人的不是零拷贝。当RDMA网卡收到请求之后,会直接把请求操作写到物理机内存地址上去,直接用了很大的区域做这件事。网卡一旦写入内存之后,这个内存就一直使用下去,永远不拷贝,这就是零拷贝。启动系统时会把物理内存注册到网卡当中去,网卡会直接操作物理内存到CPU说知道有这个物理内存到了之后,我们就一直拿物理内存用DMA发给磁盘,用RDMA再发给远程网卡一直使用下去,再也没有拷贝过了。这件事情如果不是自己写RO协议栈或者网络协议栈不可能办到。
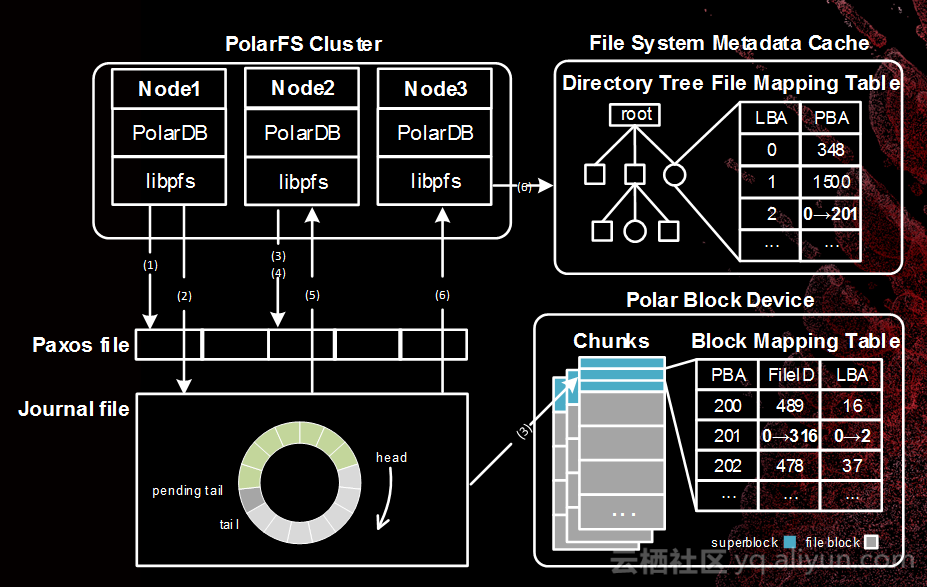
POLARDB当中使用的文件系统是PolarFS文件系统。这个文件系统是一个libpfs形式直接嵌入到数据库当中,数据库拿着lib操作后面的存储。也会在文件系统内部维护,让整个硬件在最合理的模式下工作,这是我们的设计思想。
ParallelRaft并行副本技术是传统的复制协议。我们的思路就是乱序带来并发,乱序带来极高的性能,乱序做正确就是我们的挑战,提出了一套专业的ParallelRaft技术解决这个问题。
面向数据库优化的智能存储
面向数据库优化的智能存储,包括防止DB脑裂写坏数据、Group Commit批量I/O写入优化、保证Page原子写入,避免doubleWrite开销、RedoLog高优先级写入。数据库的配置是大于10k的,一个16kb的页面如果出现部分显示成功,部分显示失败,就会出现数据损坏。
MySQL当中怎么做呢,它是用了DoubleWrite的方法做,先写到一个正确的地方,然后再放回来。相当于I/O带宽高了2倍,我们支持Page原子写入。脑裂问题,假如两个节点,一个在杭州,一个在上海。杭州和上海之间网络断开之后,两个节点都认为自己是主节点,一般做法是一主一备,两个节点都会写坏数据。我们通常做法是一定要写进去合并,再恢复到单机状态。我们在Polar store当中对数据库做了写保护,防止DB写入时脑裂,假如出现脑裂,存储借助三副本技术,可以随时授权进行仲裁,只保证一个人写的。