在Spark中,GBT(Gradient Boost Trees,提升树)函数用于实现机器学习中的提升树算法,目前仅支持二分类算法。笔者在实际工作中需要获得其预测的概率值,无奈该函数没有相应的方法。
经过笔者几天的奋斗,终于找到了解决之道。下面将分享在Spark中如何获取GBT二分类函数的概率值的思路。
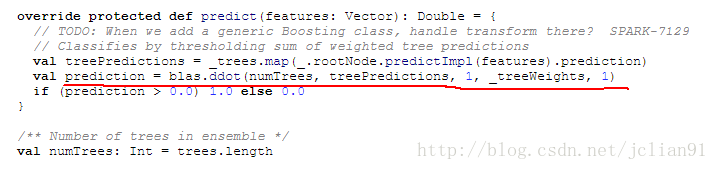
首先,查看GBT函数的Scala源代码,其中的predict函数如下:
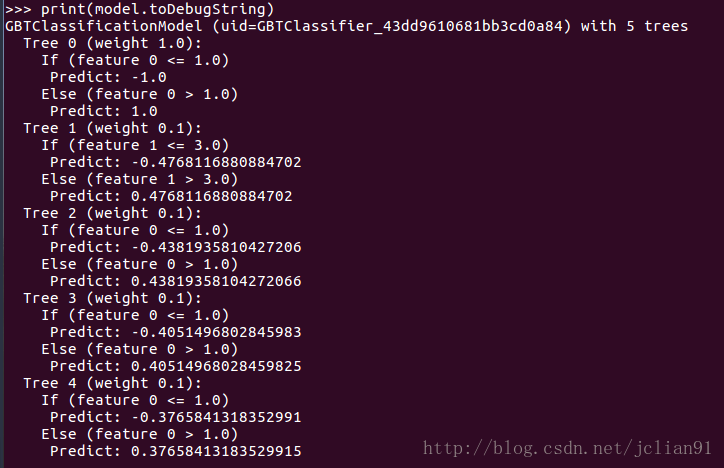
其中的prediction值是我们计算概率值所需要的,prediction的值为_treePredictions(向量)与_treeWeights(向量)的点积,numTrees为GBTClassifier所使用的树的数量。_treePredictions为每棵决策树的预测值组成的向量,_treeWeights为每颗树的权重组成的向量。
那么该如何计算_treePredictions与_treeWeights呢?
_treeWeights的计算可直接调用GBTClassifier中的treeWeights方法,输出的数据类型为list。以下为例子:(该例子的数据集和GBT测试代码见附录)
接下来讲述_treePredictions的计算。
首先可以利用toDebugString方法可以知道每棵决策树的具体情形,以下为例子:
利用trees方法可知道决策树的情形,trees方法输出为list.
取该list的下标,可以获得每颗树的模型,类型为pyspark.ml.regression.DecisionTreeRegressionMdel.
这样就可以利用DecisionTreeRegressionMdel的transfrom(data)得到每棵决策树的预测值,其中data为测试数据集。
最后,我们利用以下公式就能得到GBT函数预测的概率值:



其中,其中prediction为Scala源代码中的prediction值,它的计算方法如上所述.
当probability > 0.5时,分类为1,否则为0.
这样,我们就能在Spark中获取GBT二分类函数的概率值了。读者可以结合以上的计算思路和实际工作,自己来编写预测概率值的代码啦~~
附录1:Spark的GBTClassifier的scala源代码网址: https://fossies.org/linux/spark/mllib/src/main/scala/org/apache/spark/ml/classification/GBTClassifier.scala
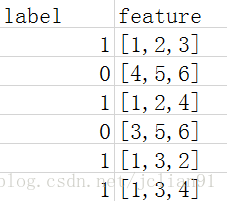
附录2:测试数据集:
附录3:测试代码:
from pyspark.ml.linalg import Vectors from pyspark.ml.feature import StringIndexer from pyspark.ml.classification import GBTClassifier df = spark.createDataFrame([(1.0,Vectors.dense(1,2,3)), (0.0,Vectors.dense(4,5,6)), (1.0,Vectors.dense(1,2,4)), (0.0,Vectors.dense(3,5,6)), (1.0,Vectors.dense(1,3,2)), (1.0,Vectors.dense(1,3,4)),], ["label", "features"]) stringIndexer = StringIndexer(inputCol="label", outputCol="indexed") si_model = stringIndexer.fit(df) td = si_model.transfrom(df) gbt = GBTClassifier(maxIter=5, maxDeth=2, labelCol="indexed", seed=42) model = gbt.fit(td)
参考网址:
1.spark如何获得分类概率: http://blog.csdn.net/seu_yang/article/details/52118683
2.Predicting probabilities of classes in case of Gradient Boosting Trees in Spark using the tree output: https://stackoverflow.com/questions/37303855/predicting-probabilities-of-classes-in-case-of-gradient-boosting-trees-in-spark