Avro是Hadoop生态圈的一部分,由Hadoop的创始人Doug Cutting牵头开发,当前最新版本1.8.2。Avro是一个数据序列化系统,设计用于支持大批量数据交换的应用。它的主要特点有:
- Rich data structures.
- A compact, fast, binary data format.
- A container file, to store persistent data.
- Remote procedure call (RPC).
- Simple integration with dynamic languages. Code generation is not required to read or write data files nor to use or implement RPC protocols. Code generation as an optional optimization, only worth implementing for statically typed languages.
本文分享的主要是用Avro1.8.2版本,下载地址为https://mirrors.tuna.tsinghua.edu.cn/apache/avro/,语言为py3.
用Python3操作Avro:
1.创建avsc文件,如province.avsc:
{"namespace": "example.avro",
"type": "record",
"name": "User",
"fields": [
{"name": "province", "type": "string"},
{"name": "abbreviation", "type": ["string", "null"]},
{"name": "capital_city", "type": ["string", "null"]},
{"name": "area", "type": ["float", "null"]}
]
}type表示Avro的数据类型为recode类型,fields为字段说明,该avsc有四个字段:province字段,数据类型为string;abbreviation字段,数据类型为string或null;capital_city字段,数据类型为string或null;area字段,数据类型为float或null。
2.编写python3代码操作Avro,如下:
# -*- coding: utf-8 -*-
import avro.schema
from avro.datafile import DataFileReader, DataFileWriter
from avro.io import DatumReader, DatumWriter
schema = avro.schema.Parse(open("/home/vagrant/province.avsc").read())
writer = DataFileWriter(open("/home/vagrant/provinces.avro", "wb"), DatumWriter(), schema)
writer.append({"province": "北京市", "abbreviation": "京", "capital_city":"北京", "area":1.68})
writer.append({"province": "上海市", "abbreviation": "沪", "capital_city":"上海", "area":0.63})
writer.append({"province": "天津市", "abbreviation": "津", "capital_city":"天津", "area":1.13})
writer.append({"province": "重庆市", "abbreviation": "渝", "capital_city":"重庆", "area":8.23})
writer.append({"province": "黑龙江省", "abbreviation": "黑", "capital_city":"哈尔滨", "area":45.48})
writer.append({"province": "吉林省", "abbreviation": "吉", "capital_city":"长春", "area":18.74})
writer.append({"province": "辽宁省", "abbreviation": "辽", "capital_city":"沈阳", "area":14.59})
writer.append({"province": "内蒙古", "abbreviation": "蒙", "capital_city":"呼和浩特", "area":118.3})
writer.append({"province": "河北省", "abbreviation": "冀", "capital_city":"石家庄", "area":18.77})
writer.append({"province": "新疆", "abbreviation": "新", "capital_city":"乌鲁木齐", "area":166})
writer.append({"province": "甘肃省", "abbreviation": "甘", "capital_city":"兰州", "area":45.44})
writer.append({"province": "青海省", "abbreviation": "青", "capital_city":"西宁", "area":72.23})
writer.append({"province": "陕西省", "abbreviation": "陕", "capital_city":"西安", "area":20.56})
writer.append({"province": "宁夏", "abbreviation": "宁", "capital_city":"银川", "area":6.64})
writer.append({"province": "河南省", "abbreviation": "豫", "capital_city":"郑州", "area":16.7})
writer.append({"province": "山东省", "abbreviation": "鲁", "capital_city":"济南", "area":15.38})
writer.append({"province": "山西省", "abbreviation": "晋", "capital_city":"太原", "area":15.63})
writer.append({"province": "安徽省", "abbreviation": "皖", "capital_city":"合肥", "area":13.97})
writer.append({"province": "湖北省", "abbreviation": "鄂", "capital_city":"武汉", "area":18.59})
writer.append({"province": "湖南省", "abbreviation": "湘", "capital_city":"长沙", "area":21.18})
writer.append({"province": "江苏省", "abbreviation": "苏", "capital_city":"南京", "area":10.26})
writer.append({"province": "四川省", "abbreviation": "川", "capital_city":"成都", "area":48.14})
writer.append({"province": "贵州省", "abbreviation": "黔", "capital_city":"贵阳", "area":17.6})
writer.append({"province": "云南省", "abbreviation": "滇", "capital_city":"昆明", "area":38.33})
writer.append({"province": "广西省", "abbreviation": "桂", "capital_city":"南宁", "area":23.6})
writer.append({"province": "西藏", "abbreviation": "藏", "capital_city":"拉萨", "area":122.8})
writer.append({"province": "浙江省", "abbreviation": "浙", "capital_city":"杭州", "area":10.2})
writer.append({"province": "江西省", "abbreviation": "赣", "capital_city":"南昌", "area":16.7})
writer.append({"province": "广东省", "abbreviation": "粤", "capital_city":"广州", "area":18})
writer.append({"province": "福建省", "abbreviation": "闽", "capital_city":"福州", "area":12.13})
writer.append({"province": "台湾省", "abbreviation": "台", "capital_city":"台北", "area":3.6})
writer.append({"province": "海南省", "abbreviation": "琼", "capital_city":"海口", "area":3.4})
writer.append({"province": "香港", "abbreviation": "港", "capital_city":"香港", "area":0.1101})
writer.append({"province": "澳门", "abbreviation": "澳", "capital_city":"澳门", "area":0.00254})
writer.close()
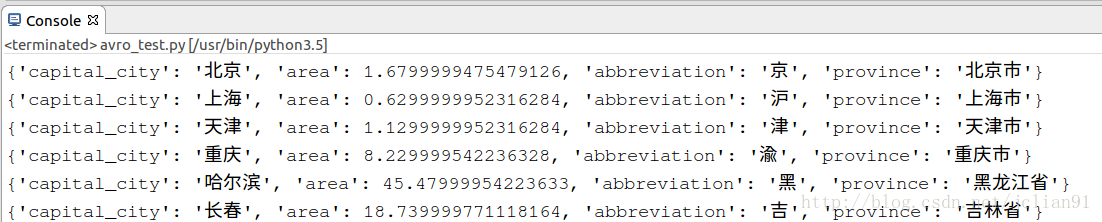
reader = DataFileReader(open("/home/vagrant/provinces.avro", "rb"), DatumReader())
for user in reader:
print(user)
reader.close()运行结果如下:
同时,会生成/home/vagrant/provinces.avro文件.
接下来我们在Hive中操作Avro文件。
首先需要将province.avsc和provinces.avro文件放在hdfs端
hdfs dfs -put ~/province.avsc /user/hive/warehouse/
hdfs dfs -put ~/provinces.avro /user/hive/warehouse/进入hive,创建provinces表,表的结构由province.avsc描述。
hive> CREATE TABLE provinces
> ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.avro.AvroSerDe'
> STORED AS INPUTFORMAT
> 'org.apache.hadoop.hive.ql.io.avro.AvroContainerInputFormat'
> OUTPUTFORMAT
> 'org.apache.hadoop.hive.ql.io.avro.AvroContainerOutputFormat'
> TBLPROPERTIES (
> 'avro.schema.url'='hdfs:///user/hive/warehouse/province.avsc');查看province表格:
hive> desc provinces;
OK
province string
abbreviation string
capital_city string
area float 从hdfs端导入数据:
load data inpath 'hdfs:///user/hive/warehouse/provinces.avro' overwrite into table provinces;查看provinces.avro数据
hive> select * from provinces;
OK
北京市 京 北京 1.68
上海市 沪 上海 0.63
天津市 津 天津 1.13
重庆市 渝 重庆 8.23
黑龙江省 黑 哈尔滨 45.48
吉林省 吉 长春 18.74
辽宁省 辽 沈阳 14.59
内蒙古 蒙 呼和浩特 118.3
河北省 冀 石家庄 18.77
新疆 新 乌鲁木齐 166.0
甘肃省 甘 兰州 45.44
青海省 青 西宁 72.23
陕西省 陕 西安 20.56
宁夏 宁 银川 6.64
河南省 豫 郑州 16.7
山东省 鲁 济南 15.38
山西省 晋 太原 15.63
安徽省 皖 合肥 13.97
湖北省 鄂 武汉 18.59
湖南省 湘 长沙 21.18
江苏省 苏 南京 10.26
四川省 川 成都 48.14
贵州省 黔 贵阳 17.6
云南省 滇 昆明 38.33
广西省 桂 南宁 23.6
西藏 藏 拉萨 122.8
浙江省 浙 杭州 10.2
江西省 赣 南昌 16.7
广东省 粤 广州 18.0
福建省 闽 福州 12.13
台湾省 台 台北 3.6
海南省 琼 海口 3.4
香港 港 香港 0.1101
澳门 澳 澳门 0.00254本次分享到此结束,欢迎大家批评和交流~~
参考网址:
1.Avro Documentation: http://avro.apache.org/docs/current/
2.Hive AvroSerDe: https://cwiki.apache.org/confluence/display/Hive/AvroSerDe
3.avro总结: http://langyu.iteye.com/blog/708568