在上一篇文章里忽略了一点。
CAP 定理有一个缺陷,这个缺陷可以帮助我们“部分”摆脱
分布式困境。
总的来说,CAP 定理本身是完备的,但它并没有描述一个分布式系统何时产生分区,以及分区会持续多长时间。理论其实只限制:在分区发生的
时间内,系统只能在一致性(C)和可用性(A)之间二选一。
因此,分布式系统完全可以在没有出现分区时保证 C 和 A,而在出现分区后,放弃一些 A 或者 C 然后通过人工操作消除分区,让系统恢复到分区前的状况。
这样说太复杂了。用
说
人话 的方式就是:
※ 当没有故障时,系统正常处理请求并且返回一致的结果。
※ 出现故障后,首先把所有请求切换到正常机器,故障机器下线。
※ 接着人工恢复故障机器上的数据,保证数据一致性。
※ 最后让机器重新上线,恢复系统正常容量。
基本上(请忽略一些细节),这就是主备同步的数据库集群在故障恢复时的做法。
这里的思路是,既然 CAP 特性在一个时间点不可能同时满足,那我们可以在这个时间点暂时放弃 A 或者 C,然后在另一个时间点再设法恢复。只要恢复的速度足够快,用户就能够忍受暂时的不一致或者不可用。

“Twitter 只是暂时不可用,最终会恢复可用。”
沿着这个思路,业界产生了一些理论,其中最著名的是 BASE。
BASE, 最终一致性
这个理论由
Basically
Available,
Soft state,
Eventual consistency 组成。核心的概念是 Eventual consistency ——最终一致性。它局部的放弃了 CAP 理论中的“完全”一致性,提供了更好的可用性和分区容忍度。
Basically Available
基本可用, 或者说部分可用。由于分布式系统的节点故障是常见的,业务必须接受这种不可用,并且做出选择:是访问另一个节点忍受数据的临时不一致,还是等待节点恢复并忍受业务上的部分不可用。
Soft state
把所有节点的数据 (数据 = 状态) 都看作是缓存(Cache)。适当的调整业务,使业务可以忍受数据的临时不一致,并保证这种不一致是无害的,可以被最终用户理解。
Eventual consistency
放弃在任何时刻、从任何节点都能读到完全一致的数据。允许数据的临时不一致,并通过异步复制、重试和合并消除数据的临时不一致。
注意 在分布式系统中,写入和读取可能发生在不同的节点上。最终一致带来的问题是,业务在写入后立即读取,很可能读不到刚刚写入的数据。因此需要一个附加约束:
RYW (
Read-Your-Writes)
consistency
RYW consistency 是弱化的因果一致性(Causal consistency),它保证业务在会话中一定能读到上一次写入的数据。会话可以看作是同一个连接,或者是同一个 HTTP Session。例如:用户刚刚创建了一个订单,在提交后他可以立刻查看这个订单,这就是 RYW 一致性。
ACID 与 BASE
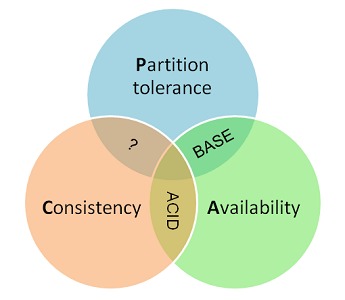
BASE 这个缩写有些拼凑的痕迹。那是因为作者认为它的含义与 ACID 恰好相反。
在英文词典里,ACID 代表
酸(Acid),而 BASE 代表
碱(Base)。就像这两个单词在化学中的含义一样 —— ACID 与 BASE 位于 CAP 理论的两端,代表了分布式系统的两种选择。
传统数据库用 ACID 保护业务数据的一致性。它明确的要求:事务必须保证数据从上一个一致性状态进入下一个一致性状态,事务的结束和数据的一致性之间没有时差。
从 CAP 定理我们可以知道:正是 ACID 要求的这种“
强”一致性,使得事务系统只能选择 C-A 或者 C-P。第一个选择实际上是单机的传统数据库,第二个选择是后面将要介绍的强一致性的数据复制集群。
而 BASE 代表了另一种选择:
放弃一致性 来保证分布式系统的高可用。与 ACID 的做法相反:业务需要接受和处理数据的不一致,并且保证这些不一致不会破坏业务约束 —— 这需要设计者对可能产生的数据不一致和业务约束非常了解,并且带来了更高的复杂度。
选择
高可用 的价值在于:很多场景下系统不可用就意味着对外停止服务,对用户的影响和商业风险远远比“系统仍然可用但是要过一会才能看到数据”来得严重。在一些场景下,用户或许根本不在乎过一会才能看到数据,例如
银行跨行转账。但是,如果银行告诉用户无法进行跨行转账,那么就会有很多用户质疑或投诉银行的服务了。
上面的 CAP 拼图里还剩下一个区域。前面讨论过的 ACID 理论占据了 C-A 区域,代表根本无法容忍分区的传统单机数据库。本文介绍的 BASE 理论位于 A-P 区域,代表部分放弃一致性、追求高可用的现代业务系统。
因此在这幅拼图里还剩下 C-P:能够在分布式环境下
保证数据一致性 的理论。
下一篇准备介绍这一部分理论。敬请期待。
