1.NetDh框架开始的需求场景
需求场景:
1.之前公司有不同.net项目组,有的项目是用SqlServer做数据库,有的项目是用Oracle,后面也有可能会用到Mysql等,而且要考虑后续扩展成主从库、多库的需求。(其实不管有没有这个需求,Dapper的封装应当像NetDb框架里封装的那样使用);
2.涉及日志操作类的设计,需要记录用户操作日志、记录系统异常日志等;
3.涉及缓存操作类的设计,这点不用需求都应该当考虑,不管是小项目的内存缓存还是大项目中的Redis/Memcache等;
4.涉及二次开发模式简单的设计。因为多个客户需要同一个项目产品,但是客户之间对该产品的需求点又有些不一样。
本文先讲为了第1点需求而封装的数据库操作类,其它三点在接下来文章中也会介绍。
2.ORM框架Dapper介绍
Dapper是轻量级高效的框架,它高效原因是利用Emit技术+各种解析缓存+DataReader。
Dapper可以在所有Ado.net Providers下工作,包括SQL Server, Oracle, MySQL , SQLite, PostgreSQL, sqlce, firebird 等,这些数据库操作类都有实现IDbConnection接口。你看源码会发现,Dapper提供的public方法大都是对IDbConnection的扩展。
DapperExtensions是Dapper的第三方插件之一(NetDh框架是用Dapper+DapperExtensions的组合),Dapper常用的代码是 Query<T>(selectSql..)把数据库获取的记录转成实体类对象,而DapperExtensions是封装了Dapper,支持诸如 Get<T>(id)、Insert<T>、Update<T>等函数,可以让你不写sql就能简单操作数据库数据。
3.数据库操作类-在Dapper+DapperExtensions基础上封装
3.1.总体说明
如上图,NetDh框架是把Dapper(.net4.5.1)目前最新源码和DapperExtensions源码合并在同一个程序集,然后添加到解决方案。有源码就可以随便调试,深入了解Dapper和学习Dapper。
在NetDh.DbUtility程序集中,DbHandleBase是个抽象基类,它封装了“数据库常用的操作函数”,如下图:
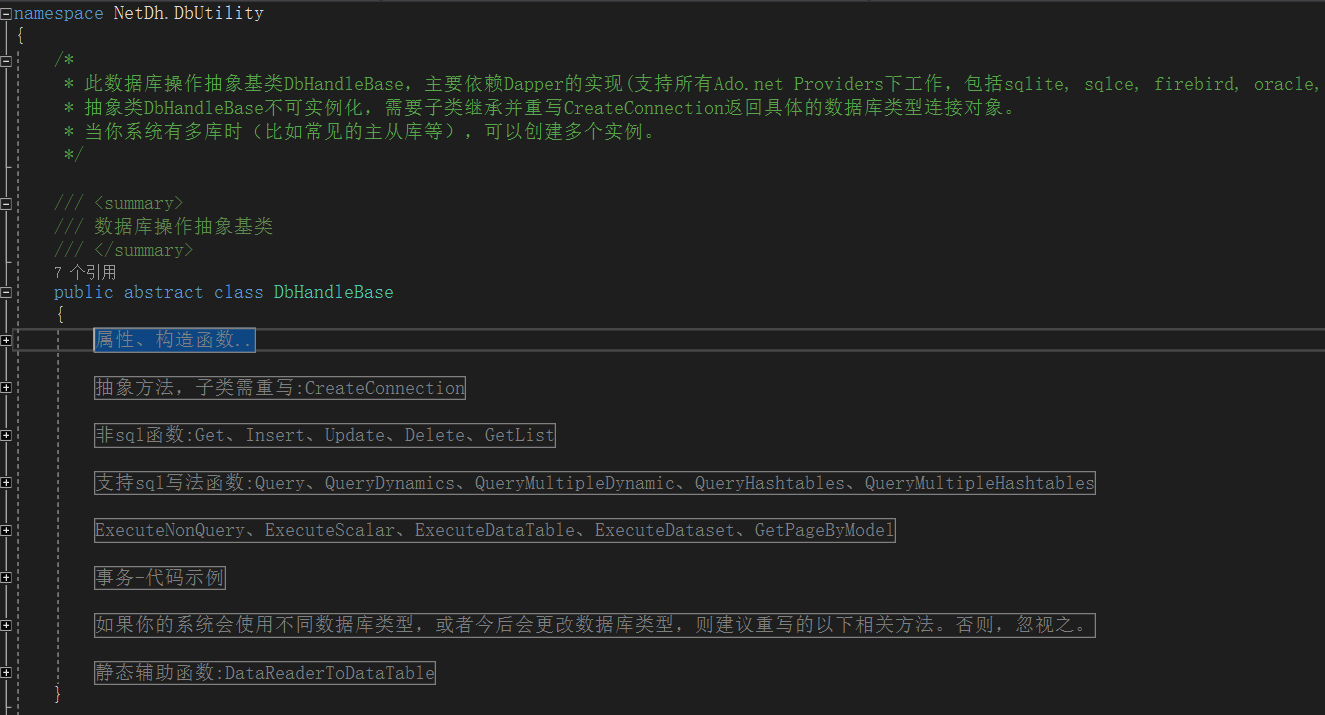
DbHandleBase基类封装了Dapper+DapperExtensions,如果要实现SqlServerHandle操作类,那么只要继承DbHandleBase,然后重写基类的CreateConnection抽象函数(为了获取连接对象),即可拥有这些“数据库常用的操作函数”。其它数据库类型也一样,很简单吧。其中,Oracle操作类不使用微软早期的OracleClient(微软已经不维护),而是使用Oracle官方ODP.NET(nuget下载 Oracle.ManagedDataAccess.dll),不用再安装OraInsClient和配置tnsnames.ora。
用了Dapper一般就是不用ExecuteDataTable和ExecuteDataset,为什么DbHandleBase还开放出来,原因:
(1)winform项目中的Grid经常要用到DataTable的DataView;
(2)sql的参数统一简单写法由dapper处理;
(3)Dapper做了各种解析缓存。
贴个DbHandleBase中的ExecuteDataTable的代码及其注释:
/* * 说明:winform中经常会用到DataTable的DataView,方便Grid展示与过滤,因此开放ExecuteDataTable和ExecuteDataset; * 如果是B/S系统,建议用以上的Query系列函数。 */ /// <summary> /// 执行sql语句,并返回DataTable(适用于Dapper支持的所有数据库类型) /// </summary> /// <param name="sql">sql语句</param> /// <param name="param">匿名对象的参数,可以简单写,比如 new {Name="user1"} 即可,会统一处理参数和参数的size</param> public virtual DataTable ExecuteDataTable(string sql, dynamic param = null, int? cmdTimeout = DEFAULTTIMEOUT, IDbTransaction tran = null, CommandType? cmdType = null) { sql = CheckSql(sql); var conn = CreateConnectionAndOpen(); try { //这边用Dapper的ExecuteReader,统一了函数参数写法,不用使用SqlParameter。 using (var reader = conn.ExecuteReader(sql, (object)param, tran, cmdTimeout, cmdType)) { var dataTable = DataReaderToDataTable(reader); return dataTable; } } finally { conn.CloseIfOpen(); } }
3.2.调用数据库操作类的示例代码
以SqlServer数据库为例,以下直接上代码,代码中的注释很详细也很有帮助。
值得一提的是:当取数条件比较复杂或者需要关联多表时,许多人还是不写sql而是喜欢用ORM的Linq表达式。建议简单的单表CRUD操作不用写sql,而比较复杂的业务逻辑建议是写sql,一是sql语法简单明了通用,每批技术员都看得懂;二是你可以对复杂的业务逻辑明确执行什么用的sql语句,怎么样的执行计划。如果你Linq写得复杂,都不知道ORM会给你生成什么样的sql出来。
/// <summary> /// NetDh模块使用示例代码 /// </summary> public class NetDhExample { #region 用全局静态变量实现单例。 /// <summary> /// 服务端使用数据库操作对象,前端不可直接使用 /// </summary> public static DbHandleBase DbHandle { get; set; } //说明:如果你有多库,比如读写分离中的只读库,则再定义一个数据库操作对象即可。 public static DbHandleBase ReadDbHandle { get; set; } #endregion /// <summary> /// 静态构造函数,只会初始化一次 /// </summary> static NetDhExample() { //初始化数据库操作对象 DbHandle = new SqlServerHandle(connStr); //如果有多库,可再new个对象 //ReadDbHandle = new SqlServerHandle(connStrForRead); } /// <summary> /// 模块使用的示例代码 /// </summary> public static void TestMain() { #region 数据库交互(sqlserver+Dapper+DapperExtension) //---------CRUD操作-------- //实体类中的第一个Id或者以Id结尾的字段,会被默认当作主键,Dapper不仅建议你的表主键为Id或以Id结尾的字段, //而且Dapper默认主键字段在数据库表里有默认值(比如有设置为自增长),关于为什么建议用自增长主键,可以翻一下我之前的博客文章《SQL Server索引原理解析》。 //如果表中的主键不符合此规定(比如表主键是MainKey字段),则需要自定义Map映射,参考以下的“DapperExtensions进阶” var user = DbHandle.Get<TbUser>(1);//这边1产生的是 where Id=1 的条件 //Get<TbUser>是DapperExtensions的功能,不是Dapper的功能。 //Get<TbUser>这种写法类似select *,并不是好作法,但是它写法方便,只取一笔影响不大。一般是select你要的字段,而不是select所有字段。具体问题具体分析。 user.Name = "new name"; DbHandle.Update(user); /* 注意如果用实体类去update,就算只更新一个字段,DapperExtension也会生成除了id主键之外的所有字段的更新。 * 多余的更新会增加数据库开销,尤其有非聚集索引字段。因此,建议如果要用此Update函数,则只用于基础表。 */ var lastInsertId = DbHandle.Insert(user);//返回lastInsertId。因为它生成的语句包含:SELECT CAST(SCOPE_IDENTITY() AS BIGINT) AS [Id] /* DbHandle.Insert(user);是不会报主键重复。以下是DbHandle.Insert产生的语法(来自SQL Server Profiler工具), * 不会生成主键Id的Insert。因为Dapper默认你的主键如果是整形则是KeyType.Identity类型(即默认主键字段在数据库表里有默认值,比如有设置为自增长), * DbHandle.Insert(user) DapperExtensions产生的sql语句: exec sp_executesql N'INSERT INTO [TbUser] ([TbUser].[Name], [TbUser].[Age], [TbUser].[Remark], [TbUser].[Department], [TbUser].[CreateTime]) VALUES (@Name, @Age, @Remark, @Department, @CreateTime); SELECT CAST(SCOPE_IDENTITY() AS BIGINT) AS [Id]',N'@CreateTime datetime,@Department nvarchar(200),@Age decimal(6,4),@Name nvarchar(200),@Remark nvarchar(4000)',@CreateTime='2018-06-07 20:05:33.630',@Department=N'D1',@Age=30,@Name=N'new name',@Remark=N'remark1' */ user.Id = 1001; DbHandle.Delete(user); //DbHandle.Delete(user);只和主键Id有关。产生的sql:exec sp_executesql N'DELETE FROM [TbUser] WHERE ([TbUser].[Id] = @Id_0)',N'@Id_0 int',@Id_0=1001 DbHandle.Delete(new TbUser() { Id = 1001 }); //--------------------- //1.使用DapperExtensions过滤条件取Id<100的TbUser降序数据列表 var filter = Predicates.Field<TbUser>(f => f.Id, Operator.Lt, 100); var sort = new List<ISort> { Predicates.Sort<TbUser>(f => f.Id, false) };//false降序 var users2 = DbHandle.GetList<TbUser>(filter, sort); //如果需要多个过滤条件需要用到PredicatesGroup嵌套,这是DapperExtensions的功能(不是Dapper原生功能)。 //复杂的sql建议用直接写sql(如下简洁版),直接写复杂sql的优点:select字段可选、sql执行计划可控。 //2.使用sql取Id<100的TbUser降序数据列表(简洁版)可以指定只取你要的字段Id,Name。简单明了通用。 var uses = DbHandle.Query<TbUser>("select Id,Name from TbUser where Id<@maxId order by Id desc", new { maxId = 100 }); //winform中经常会用到DataTable的DataView,方便Grid展示与过滤,因此开放ExecuteDataTable和ExecuteDataset var table = DbHandle.ExecuteDataTable("select Id,Name from TbUser where Id<100 order by Id desc"); //---------分页-------- //1.单表分页(第3页,一页10笔) DapperExtension支持单表 var pageUsers = DbHandle.GetPageByModel<TbUser>(null, sort, 2, 10);//参数startPageIndex第1页是从0开始 //2.sqlserver 自己sql分页(第3页,一页10笔),并且获取表记录总数 var pageSql = @" select top 10 * from( select (row_number() over(order by Id))as rowId,* from TbUser where Id<@maxId) as a where a.rowId >20 order by a.rowId; select count(1) from TbUser"; var dataset = DbHandle.ExecuteDataSet(pageSql, new { maxId = 1000 }); //3.封装的sql分页,为了支持不同数据库分页写法不同(第3页,一页10笔),并且获取表记录总数,适合较复杂的分页 var pageSql1 = DbHandle.GetPageSql("select * from TbUser A where A.Id<@maxId", "order by A.Id", 2, 10, "select count(1) from TbUser");//参数startPageIndex第1页是从0开始 dataset = DbHandle.ExecuteDataSet(pageSql1, new { maxId = 1000 }); //---------多表关联-------- //select的字段并没有对应的实体类时,可用QueryDynamics。DbHandle也支持返回IEnumerable<Hashtable>的QueryHashtables,方便转为json格式 var dyObj = DbHandle.QueryDynamics("select A.Name,B.Amount from TbUser A inner join TbOrder B on B.Uid=A.Id where A.Id=@Id", new { Id = 10 }); //---------使用存储过程-------- //执行存储过程就是把函数参数CommandType设置为CommandType.StoredProcedure即可,存储过程的参数传递直接 new {@p=value} #endregion #region DapperExtensions进阶--自定义Map映射。 /*项目起初,规范好表设计,一般是不会用到自定义Map映射。如果是现有项目,可酌情考虑*/ //自定义Map,具体参考TbUser.cs里的代码说明 //以下这句是初始化,告诉DapperExtensions DapperExtensions.DapperExtensions.SetMappingAssemblies(new[] { typeof(TbUserMapper).Assembly }); //DapperExtensions.DapperExtensions.SqlDialect = new DapperExtensions.Sql.SqlServerDialect();//DapperExtensions默认就是SqlServerDialect #endregion } }
3.3.DapperExtensions进阶--自定义Map映射
比如你的实体类名是TbUser,而对应的数据库表名是UserTable,或者实体类的某个属性名和数据库表字段名不一样,则需要Map映射,映射支持以下几种情况,看代码和注释:
#region 如果需要自定义Map映射,可参考: public class TbUserMapper : ClassMapper<TbUser> { public TbUserMapper() { //1.use different table name Table("UserTable");//把实体类的数据库表名指定为UserTable //2.use a custom schema //Schema("not_dbo_schema"); //3.have a custom primary key //KeyType.Assigned说明主键在数据库表无默认值(比如是非自增长的主键) //KeyType.Identity说明主键在数据库表有默认值(比如是自增长的主键) //Map(x => x.MainKey).Key(KeyType.Assigned); //4.Use a different name property from database column //Map(x => x.Remark).Column("Bar");//把实体类的Remark属性指定为数据库表Bar字段 //5.Ignore this property entirely //Map(x => x.SecretDataMan).Ignore();//忽略实体类中的SecretDataMan字段,即它不是数据库表字段。 //optional, map all other columns AutoMap(); } //启动程序时,执行以下定义: //DapperExtensions.DapperExtensions.SetMappingAssemblies(new[] { typeof(TbUserMapper).Assembly }); //当你有很多个Model类都有自定义Map时,而且这些自定Map都在同一个程序集,那么只要上面那一句就可以了。它会检索整个Assemble去查找出所有继承ClassMapper的类。 } #endregion
怎么让你自定义的映射生效呢,上面代码最后一段就是:
//启动程序时,执行以下定义:
DapperExtensions.DapperExtensions.SetMappingAssemblies(new[] { typeof(TbUserMapper).Assembly });
3.4.源码
国外有github,国内有码云,在国内使用码云速度非常快。NetDh框架源码放在码云上:
分享、互相交流学习