大数据这个词也许几年前你听着还会觉得陌生,但我相信你现在听到hadoop这个词的时候你应该都会觉得“熟悉”!越来越发现身边从事hadoop开发或者是正在学习hadoop的人变多了。作为一个hadoop入门级的新手,你会觉得哪些地方很难呢?运行环境的搭建恐怕就已经足够让新手头疼。如果每一个发行版hadoop都可以做到像大快DKHadoop那样把各种环境搭建集成到一起,一次安装搞定所有,那对于新手来说将是件多么美妙的事情!
闲话扯得稍微多了点,回归整体。这篇准备给大家hadoop新入门的朋友分享一些hadoop的基础知识——hadoop家族产品。通过对hadoop家族产品的认识,进一步帮助大家学习好hadoop!同时,也欢迎大家提出宝贵意见!
一、Hadoop定义
Hadoop是一个大家族,是一个开源的生态系统,是一个分布式运行系统,是基于Java编程语言的架构。不过它最高明的技术还是HDFS和MapReduce,使得它可以分布式处理海量数据。
二、Hadoop产品
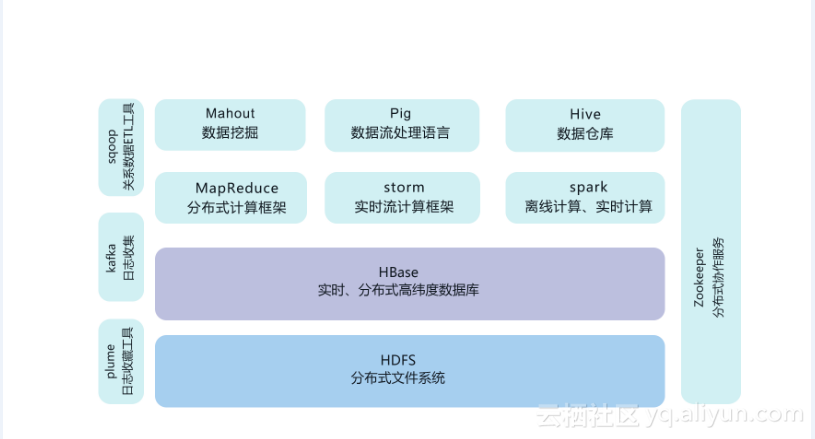
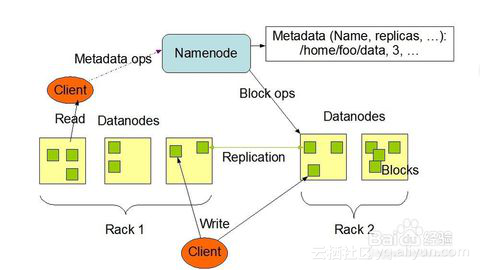
HDFS(分布式文件系统):
它与现存的文件系统不同的特性有很多,比如高度容错(即使中途出错,也能继续运行),支持多媒体数据和流媒体数据访问,高效率访问大型数据集合,数据保持严谨一致,部署成本降低,部署效率提高等,如图是HDFS的基础架构。
MapReduce/Spark/Storm(并行计算架构):
1、数据处理方式来说分离线计算和在线计算:
| 角色 |
描述 |
| MapReduce |
MapReduce常用于离线的复杂的大数据计算 |
| Storm |
Storm用于在线的实时的大数据计算,Storm的实时主要是一条一条数据处理; |
| Spark |
可以用于离线的也可用于在线的实时的大数据计算,Spark的实时主要是处理一个个时间区域的数据,所以说Spark比较灵活。 |
2、数据存储位置来说分磁盘计算和内存计算:
| 角色 |
描述 |
| MapReduce |
数据存在磁盘中 |
| Spark和Strom |
数据存在内存中 |
Pig/Hive(Hadoop编程):
| 角色 |
描述 |
| Pig |
是一种高级编程语言,在处理半结构化数据上拥有非常高的性能,可以帮助我们缩短开发周期。 |
| Hive |
是数据分析查询工具,尤其在使用类SQL查询分析时显示出极高的性能。可以在分分钟完成ETL要一晚上才能完成的事情,这就是优势,占了先机! |
HBase/Sqoop/Flume(数据导入与导出):
| 角色 |
描述 |
| HBase |
是运行在HDFS架构上的列存储数据库,并且已经与Pig/Hive很好地集成。通过Java API可以近无缝地使用HBase。 |
| Sqoop |
设计的目的是方便从传统数据库导入数据到Hadoop数据集合(HDFS/Hive)。 |
| Flume |
设计的目的是便捷地从日志文件系统直接把数据导入到Hadoop数据集合(HDFS)中。 |
以上这些数据转移工具都极大地方便了使用的人,提高了工作效率,把精力专注在业务分析上。
ZooKeeper/Oozie(系统管理架构):
| 角色 |
描述 |
| ZooKeeper |
是一个系统管理协调架构,用于管理分布式架构的基本配置。它提供了很多接口,使得配置管理任务简单化。 |
| Oozie |
Oozie服务是用于管理工作流。用于调度不同工作流,使得每个工作都有始有终。这些架构帮助我们轻量化地管理大数据分布式计算架构。 |
Ambari/Whirr(系统部署管理):
| 角色 |
描述 |
| Ambari |
帮助相关人员快捷地部署搭建整个大数据分析架构,并且实时监控系统的运行状况。 |
| Whirr |
Whirr的主要作用是帮助快速地进行云计算开发。 |
Mahout(机器学习):
Mahout旨在帮助我们快速地完成高智商的系统。其中已经实现了部分机器学习的逻辑。这个架构可以让我们快速地集成更多机器学习的智能。


