基本简介
哈夫曼编码举例
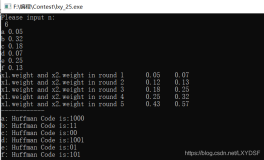
以
哈夫曼树─即最优二叉树,带权路径长度最小的二叉树,经常应用于数据压缩。 在计算机信息处理中,“哈夫曼编码”是一种一致性编码法(又称"熵编码法"),用于数据的无损耗压缩。这一术语是指使用一张特殊的编码表将源字符(例如某文件中的一个符号)进行编码。这张编码表的特殊之处在于,它是根据每一个源字符出现的估算概率而建立起来的(出现概率高的字符使用较短的编码,反之出现概率低的则使用较长的编码,这便使编码之后的字符串的平均期望长度降低,从而达到无损压缩数据的目的)。这种方法是由David.A.Huffman发展起来的。 例如,在英文中,e的出现概率很高,而z的出现概率则最低。当利用哈夫曼编码对一篇英文进行压缩时,e极有可能用一个位(bit)来表示,而z则可能花去25个位(不是26)。用普通的表示方法时,每个英文字母均占用一个字节(byte),即8个位。二者相比,e使用了一般编码的1/8的长度,z则使用了3倍多。倘若我们能实现对于英文中各个字母出现概率的较准确的估算,就可以大幅度提高无损压缩的比例。 本文描述在网上能够找到的最简单,最快速的哈夫曼编码。本方法不使用任何扩展动态库,比如STL或者组件。只使用简单的C函数,比如:memset,memmove,qsort,malloc,realloc和memcpy。 因此,大家都会发现,理解甚至修改这个编码都是很容易的。
背景 哈夫曼压缩是个无损的压缩算法,一般用来压缩文本和程序文件。哈夫曼压缩属于可变代码长度算法一族。意思是个体符号(例如,文本文件中的字符)用一个特定长度的位序列替代。因此,在文件中出现频率高的符号,使用短的位序列,而那些很少出现的符号,则用较长的位序列。
编码使用 我用简单的C函数写这个编码是为了让它在任何地方使用都会比较方便。你可以将他们放到类中,或者直接使用这个函数。并且我使用了简单的格式,仅仅输入输出缓冲区,而不象其它文章中那样,输入输出文件。 bool CompressHuffman(BYTE *pSrc, int nSrcLen, BYTE *&pDes, int &nDesLen); bool DecompressHuffman(BYTE *pSrc, int nSrcLen, BYTE *&pDes, int &nDesLen);
要点说明
速度
为了让它(huffman.cpp)快速运行,我花了很长时间。同时,我没有使用任何动态库,比如STL或者MFC。它压缩1M数据少于100ms(P3处理器,主频1G)。
压缩
压缩代码非常简单,首先用ASCII值初始化511个哈夫曼节点: CHuffmanNode nodes[511]; for(int nCount = 0; nCount < 256; nCount++) nodes[nCount].byAscii = nCount; 然后,计算在输入缓冲区数据中,每个ASCII码出现的频率: for(nCount = 0; nCount < nSrcLen; nCount++) nodes[pSrc[nCount]].nFrequency++; 然后,根据频率进行排序: qsort(nodes, 256, sizeof(CHuffmanNode), frequencyCompare); 现在,构造哈夫曼树,获取每个ASCII码对应的位序列: int nNodeCount = GetHuffmanTree(nodes);
构造哈夫曼树
构造哈夫曼树非常简单,将所有的节点放到一个队列中,用一个节点替换两个频率最低的节点,新节点的频率就是这两个节点的频率之和。这样,新节点就是两个被替换节点的父节点了。如此循环,直到队列中只剩一个节点(树根)。 // parent node pNode = &nodes[nParentNode++]; // pop first child pNode->pLeft = PopNode(pNodes, nBackNode--, false); // pop second child pNode->pRight = PopNode(pNodes, nBackNode--, true); // adjust parent of the two poped nodes pNode->pLeft->pParent = pNode->pRight->pParent = pNode; // adjust parent frequency pNode->nFrequency = pNode->pLeft->nFrequency + pNode->pRight->nFrequency;
构造哈夫曼树注意事项
这里我用了一个好的诀窍来避免使用任何队列组件。我先前就直到ASCII码只有256个,但我分配了511个(CHuffmanNode nodes[511]),前255个记录ASCII码,而用后255个记录哈夫曼树中的父节点。并且在构造树的时候只使用一个指针数组(ChuffmanNode *pNodes[256])来指向这些节点。同样使用两个变量来操作队列索引(int nParentNode = nNodeCount;nBackNode = nNodeCount –1)。 接着,压缩的最后一步是将每个ASCII编码写入输出缓冲区中: int nDesIndex = 0; // loop to write codes for(nCount = 0; nCount < nSrcLen; nCount++) { *(DWORD*)(pDesPtr+(nDesIndex>>3)) |= nodes[pSrc[nCount]].dwCode << (nDesIndex&7); nDesIndex += nodes[pSrc[nCount]].nCodeLength; } (nDesIndex>>3): >>3 以8位为界限右移后到达右边字节的前面 (nDesIndex&7): &7 得到最高位.
注意:
在压缩缓冲区中,我们必须保存哈夫曼树的节点以及位序列,这样我们才能在解压缩时重新构造哈夫曼树(只需保存ASCII值和对应的位序列)。
解压缩
解压缩比构造哈夫曼树要简单的多,将输入缓冲区中的每个编码用对应的ASCII码逐个替换就可以了。只要记住,这里的输入缓冲区是一个包含每个ASCII值的编码的位流。因此,为了用ASCII值替换编码,我们必须用位流搜索哈夫曼树,直到发现一个叶节点,然后将它的ASCII值添加到输出缓冲区中: int nDesIndex = 0; DWORD nCode; while(nDesIndex < nDesLen) { nCode = (*(DWORD*)(pSrc+(nSrcIndex>>3)))>>(nSrcIndex&7); pNode = pRoot; while(pNode->pLeft) { pNode = (nCode&1) ? pNode->pRight : pNode->pLeft; nCode >>= 1; nSrcIndex++; } pDes[nDesIndex++] = pNode->byAscii; } 过程 #include <stdio.h> #include<stdlib.h> #include<string.h> #include<malloc.h> #include<math.h> #define M 10 typedef struct Fano_Node { char ch; float weight; }FanoNode[M]; typedef struct node { int start; int end; struct node *next; }LinkQueueNode; typedef struct { LinkQueueNode *front; LinkQueueNode *rear; }LinkQueue; void EnterQueue(LinkQueue *q,int s,int e) { LinkQueueNode *NewNode; NewNode=(LinkQueueNode *)malloc(sizeof(LinkQueueNode)); if(NewNode!=NULL) { NewNode->start=s; NewNode->end=e; NewNode->next=NULL; q->rear->next=NewNode; q->rear=NewNode; } else printf("Error!"); } //***按权分组***// void Divide(FanoNode f,int s,int *m,int e) { int i; float sum,sum1; sum=0; for(i=s;i<=e;i++) sum+=f.weight; *m=s; sum1=0; for(i=s;i<e;i++) { sum1+=f.weight; *m=fabs(sum-2*sum1)>fabs(sum-2*sum1-2*f.weight)?(i+1):*m; if(*m==i) break; } } main() { int i,j,n,max,m,h[M]; int sta,mid,end; float w; char c,fc[M][M]; FanoNode FN; LinkQueueNode *p; LinkQueue *Q; //***初始化队Q***// Q->front=(LinkQueueNode *)malloc(sizeof(LinkQueueNode)); Q->rear=Q->front; Q->front->next=NULL; printf("/t***FanoCoding***/n"); printf("Please input the number of node:"); /*输入信息*/ scanf("%d",&n); i=1; while(i<=n) { printf("%d weight and node:",i); scanf("%f %c",&FN.weight,&FN.ch); for(j=1;j<i;j++) { if(FN.ch==FN[j].ch) { printf("Same node!!!/n"); break; } } if(i==j) i++; } for(i=1;i<=n;i++) /*排序*/ { max=i+1; for(j=max;j<=n;j++) max=FN[max].weight<FN[j].weight?j:max; if(FN.weight<FN[max].weight) { w=FN.weight; FN.weight=FN[max].weight; FN[max].weight=w; c=FN.ch; FN.ch=FN[max].ch; FN[max].ch=c; } } for(i=1;i<=n;i++) /*初始化h*/ h=0; EnterQueue(Q,1,n); /*1和n进队*/ while(Q->front->next!=NULL) { p=Q->front->next; /*出队*/ Q->front->next=p->next; if(p==Q->rear) Q->rear=Q->front; sta=p->start; end=p->end; free(p); Divide(FN,sta,&m,end); /*按权分组*/ for(i=sta;i<=m;i++) { fc[h]='0'; h++; } if(sta!=m) EnterQueue(Q,sta,m); else fc[sta][h[sta]]='/0'; for(i=m+1;i<=end;i++) { fc[h]='1'; h++; } if(m==sta&&(m+1)==end) //如果分组后首元素的下标与中间元素的相等, { //并且和最后元素的下标相差为1,则编码码字字符串结束 fc[m][h[m]]='/0'; fc[end][h[end]]='/0'; } else EnterQueue(Q,m+1,end); } for(i=1;i<=n;i++) /*打印编码信息*/ { printf("%c:",FN.ch); printf("%s/n",fc); } system("pause"); } #include<stdio.h> #include<stdlib.h> #include<malloc.h> #include<string.h> #define N 100 #define M 2*N-1 typedef char * HuffmanCode[2*M]; typedef struct { char weight; int parent; int LChild; int RChild; }HTNode,Huffman[M+1]; typedef struct Node { int weight; /*叶子结点的权值*/ char c; /*叶子结点*/ int num; /*叶子结点的二进制码的长度*/ }WNode,WeightNode[N]; /***产生叶子结点的字符和权值***/ void CreateWeight(char ch[],int *s,WeightNode *CW,int *p) { int i,j,k; int tag; *p=0; for(i=0;ch!='/0';i++) { tag=1; for(j=0;j<i;j++) if(ch[j]==ch) { tag=0; break; } if(tag) { (*CW)[++*p].c=ch; (*CW)[*p].weight=1; for(k=i+1;ch[k]!='/0';k++) if(ch==ch[k]) (*CW)[*p].weight++; } } *s=i; } /********创建HuffmanTree********/ void CreateHuffmanTree(Huffman *ht,WeightNode w,int n) { int i,j; int s1,s2; for(i=1;i<=n;i++) { (*ht).weight =w.weight; (*ht).parent=0; (*ht).LChild=0; (*ht).RChild=0; } for(i=n+1;i<=2*n-1;i++) { (*ht).weight=0; (*ht).parent=0; (*ht).LChild=0; (*ht).parent=0; } for(i=n+1;i<=2*n-1;i++) { for(j=1;j<=i-1;j++) if(!(*ht)[j].parent) break; s1=j; /*找到第一个双亲不为零的结点*/ for(;j<=i-1;j++) if(!(*ht)[j].parent) s1=(*ht)[s1].weight>(*ht)[j].weight?j:s1; (*ht)[s1].parent=i; (*ht).LChild=s1; for(j=1;j<=i-1;j++) if(!(*ht)[j].parent) break; s2=j; /*找到第一个双亲不为零的结点*/ for(;j<=i-1;j++) if(!(*ht)[j].parent) s2=(*ht)[s2].weight>(*ht)[j].weight?j:s2; (*ht)[s2].parent=i; (*ht).RChild=s2; (*ht).weight=(*ht)[s1].weight+(*ht)[s2].weight; } } /***********叶子结点的编码***********/ void CrtHuffmanNodeCode(Huffman ht,char ch[],HuffmanCode *h,WeightNode *weight,int m,int n) { int i,j,k,c,p,start; char *cd; cd=(char *)malloc(n*sizeof(char)); cd[n-1]='/0'; for(i=1;i<=n;i++) { start=n-1; c=i; p=ht.parent; while(p) { start--; if(ht[p].LChild==c) cd[start]='0'; else cd[start]='1'; c=p; p=ht[p].parent; } (*weight).num=n-start; (*h)=(char *)malloc((n-start)*sizeof(char)); p=-1; strcpy((*h),&cd[start]); } system("pause"); } /*********所有字符的编码*********/ void CrtHuffmanCode(char ch[],HuffmanCode h,HuffmanCode *hc,WeightNode weight,int n,int m) { int i,j,k; for(i=0;i<m;i++) { for(k=1;k<=n;k++) /*从(*weight)[k].c中查找与ch相等的下标K*/ if(ch==weight[k].c) break; (*hc)=(char *)malloc((weight[k].num+1)*sizeof(char)); for(j=0;j<=weight[k].num;j++) (*hc)[j]=h[k][j]; } } /*****解码*****/ void TrsHuffmanTree(Huffman ht,WeightNode w,HuffmanCode hc,int n,int m) { int i=0,j,p; printf("***StringInformation***/n"); while(i<m) { p=2*n-1; for(j=0;hc[j]!='/0';j++) { if(hc[j]=='0') p=ht[p].LChild; else p=ht[p].RChild; } printf("%c",w[p].c); /*打印原信息*/ i++; } } main() { int i,n,m,s1,s2,j; /*n为叶子结点的个数*/ char ch[N],w[N]; /*ch[N]存放输入的字符串*/ Huffman ht; /*二叉数 */ HuffmanCode h,hc; /* h存放叶子结点的编码,hc 存放所有结点的编码*/ WeightNode weight; /*存放叶子结点的信息*/ printf("/t***HuffmanCoding***/n"); printf("please input information :"); gets(ch); /*输入字符串*/ CreateWeight(ch,&m,&weight,&n); /*产生叶子结点信息,m为字符串ch[]的长度*/ printf("***WeightInformation***/n Node "); /*输出叶子结点的字符与权值*/ for(i=1;i<=n;i++) printf("%c ",weight.c); printf("/nWeight "); for(i=1;i<=n;i++) printf("%d ",weight.weight); CreateHuffmanTree(&ht,weight,n); /*产生Huffman树*/ printf("/n***HuffamnTreeInformation***/n"); for(i=1;i<=2*n-1;i++) /*打印Huffman树的信息*/ printf("/t%d %d %d %d/n",i,ht.weight,ht.parent,ht.LChild,ht.RChild); CrtHuffmanNodeCode(ht,ch,&h,&weight,m,n); /*叶子结点的编码*/ printf(" ***NodeCode***/n"); /*打印叶子结点的编码*/ for(i=1;i<=n;i++) { printf("/t%c:",weight.c); printf("%s/n",h); } CrtHuffmanCode(ch,h,&hc,weight,n,m); /*所有字符的编码*/ printf("***StringCode***/n"); /*打印字符串的编码*/ for(i=0;i<m;i++) printf("%s",hc); system("pause"); TrsHuffmanTree(ht,weight,hc,n,m); /*解码*/ system("pause"); } Matlab 中简易实现Huffman编译码: n=input('Please input the total number: '); hf=zeros(2*n-1,5); hq=[]; for ki=1:n hf(ki,1)=ki; hf(ki,2)=input('Please input the frequency: '); hq=[hq,hf(ki,2)]; end for ki=n+1:2*n-1 hf(ki,1)=ki; mhq1=min(hq); m=size(hq); m=m(:,2); k=1; while k<=m%del min1 if hq(:,k)==mhq1 hq=[hq(:,1:(k-1)) hq(:,(k+1):m)]; m=m-1; break else k=k+1; end end k=1; while hf(k,2)~=mhq1|hf(k,5)==1%find min1 location k=k+1; end hf(k,5)=1; k1=k; mhq2=min(hq); k=1; while k<=m%del min2 if hq(:,k)==mhq2 hq=[hq(:,1:(k-1)) hq(:,(k+1):m)]; m=m-1; break else k=k+1; end end k=1; while hf(k,2)~=mhq2|hf(k,5)==1%find min2 location k=k+1; end hf(k,5)=1; k2=k; hf(ki,2)=mhq1+mhq2; hf(ki,3)=k1; hf(ki,4)=k2; hq=[hq hf(ki,2)]; end clc choose=input('Please choose what you want:/n1: Encoding/n2: Decoding/n3:.Exit/n'); while choose==1|choose==2 if choose==1 a=input('Please input the letter you want to Encoding: '); k=1; while hf(k,2)~=a k=k+1; if k>=n display('Error! You did not input this number.'); break end end if k>=n break end r=[]; while hf(k,5)==1 kc=n+1; while hf(kc,3)~=k&hf(kc,4)~=k kc=kc+1; end if hf(kc,3)==k r=[0 r]; else r=[1 r]; end k=kc; end r else a=input('Please input the metrix you want to Decoding: '); sa=size(a); sa=sa(:,2); k=2*n-1; while sa~=0 if a(:,1)==0 k=hf(k,3); else k=hf(k,4); end a=a(:,2:sa); sa=sa-1; if k==0 display('Error! The metrix you entered is a wrong one.'); break end end if k==0 break end r=hf(k,2); end choose=input('Please choose what you want:/n1: Encoding/n2: Decoding/n3:.Exit/n'); clc; end if choose~=1&choose~=2 clc; end