日常使用mysql数据库遇到的一些问题,做下记录,会持续更新。
一、MySql Host is blocked because of many connection errors; unblock with 'mysqladmin flush-hosts' 解决方法
环境:linux,mysql5.6
错误:Host is blocked because of many connection errors; unblock with 'mysqladmin flush-hosts'
原因:
同一个ip在短时间内产生太多(超过mysql数据库max_connect_errors的最大值)中断的数据库连接而导致的阻塞;默认max_connect_errors是10
解决方法:
1、提高允许的max_connection_errors数量(治标不治本):
① 进入Mysql数据库查看max_connect_errors: show variables like '%max_connection_errors%';
② 修改max_connection_errors的数量为1000: set global max_connect_errors = 1000;
③ 查看是否修改成功:show variables like '%max_connection_errors%';
2、使用mysqladmin flush-hosts 命令清理一下hosts文件(不知道mysqladmin在哪个目录下可以使用命令查找:whereis mysqladmin);
① 在查找到的目录下使用命令修改:/usr/bin/mysqladmin flush-hosts -h192.168.1.1 -P3306 -uroot -prootpwd;
注意:
其中端口号,用户名,密码都可以根据需要来添加和修改;
配置有master/slave主从数据库的要把主库和从库都修改一遍的;
第二步也可以在数据库中进行,命令如下:flush hosts;
150422 14:10:01 [Warning] IP address '172.17.1.69' could not be resolved: Name or service not known 150422 14:10:01 [Warning] IP address '192.168.120.1' could not be resolved: Name or service not known 150422 14:10:02 [Warning] IP address '192.168.80.1' could not be resolved: Name or service not known
mysql> set global skip_name_resolve=ON; mysql> show variables like '%skip%'; +------------------------+-------+ | Variable_name | Value | +------------------------+-------+ | skip_external_locking | ON | | skip_name_resolve | ON | | skip_networking | OFF | | skip_show_database | OFF | | slave_skip_errors | OFF | | sql_slave_skip_counter | 0 | +------------------------+-------+ 6 rows in set (0.00 sec)
设置好变量值后,flush hosts;生效
mysql>flush hosts;
二、sql_mode=only_full_group_by问题,this is incompatible with sql_mode=only_full_group_by错误
错误:
在使用MySQL命令行进行分组时报错:
ERROR 1055 (42000): Expression #1 of SELECT list is not in GROUP BY clause and contains nonaggregated column 'database_tl.emp.id' which is not functionally dependent on columns in GROUP BY clause; this is incompatible with sql_mode=only_full_group_by
原因:
看一下group by的语法:
select 选取分组中的列+聚合函数 from 表名称 group by 分组的列
从语法格式来看,是先有分组,再确定检索的列,检索的列只能在参加分组的列中选。
解决:
查看mysql版本命令:select version();
查看sql_model参数命令:
SELECT @@GLOBAL.sql_mode;
SELECT @@SESSION.sql_mode;
发现:
ONLY_FULL_GROUP_BY,STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION
第一项默认开启ONLY_FULL_GROUP_BY,
解决方法:
1.只选择出现在group by后面的列,或者给列增加聚合函数;
2.命令行输入:
set sql_mode='STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION'; 如果上面设置完成后依然报错,这里执行下面的SQL,将全局设置更改,然后必须关闭现有的连接,重新打开连接后查询即可 set global sql_mode='STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION';
默认关掉ONLY_FULL_GROUP_BY!
3.直接运行下面的设置命令(我最常用的方式)
将ONLY_FULL_GROUP_BY设置为空
SET GLOBAL sql_mode=(SELECT REPLACE(@@sql_mode,'ONLY_FULL_GROUP_BY',''));
更改完之后可以查看sql_mode:
SELECT @@GLOBAL.sql_mode; SELECT @@SESSION.sql_mode;
注意:
这点在数据库服务进行迁移时尤其要注意,迁移后的数据库如果忘记设置会报错。
三、开启binlog后异常:impossible to write to binary log since BINLOG_FORMAT = STATEMENT
{ [Error: ER_BINLOG_STMT_MODE_AND_ROW_ENGINE: Cannot execute statement: impossible to write to binary log since BINLOG_FORMAT = STATEMENT and at least one table uses a storage engine limited to row-based logging. InnoDB is limited to row-logging when transaction isolation level is READ COMMITTED or READ UNCOMMITTED.]
code: 'ER_BINLOG_STMT_MODE_AND_ROW_ENGINE',
errno: 1665,
sqlState: 'HY000',
index: 0 }
原因:
mysql默认的binlog_format是STATEMENT。
从 MySQL 5.1.12 开始,可以用以下三种模式来实现:基于SQL语句的复制(statement-based replication, SBR),基于行的复制(row-based replication, RBR),混合模式复制(mixed-based replication, MBR)。相应地,binlog的格式也有三种:STATEMENT,ROW,MIXED。
如果你采用默认隔离级别REPEATABLE-READ,那么建议binlog_format=ROW。如果你是READ-COMMITTED隔离级别,binlog_format=MIXED和binlog_format=ROW效果是一样的,binlog记录的格式都是ROW,对主从复制来说是很安全的参数。
解决:
mysql> SET SESSION binlog_format = 'ROW'; mysql> SET GLOBAL binlog_format = 'ROW';
注意: 若手动修改linux下面/etc/my.cnf : binlog_format = row , 需要重启mysql,且是永久生效。
相关文档参考:


MySQL binlog_format (Mixed,Statement,Row) MySQL 5.5 中对于二进制日志 (binlog) 有 3 种不同的格式可选:Mixed,Statement,Row,默认格式是 Statement。总结一下这三种格式日志的优缺点。 MySQL Replication 复制可以是基于一条语句 (Statement Level) ,也可以是基于一条记录 (Row Level),可以在 MySQL 的配置参数中设定这个复制级别,不同复制级别的设置会影响到 Master 端的 bin-log 日志格式。 1. Row 日志中会记录成每一行数据被修改的形式,然后在 slave 端再对相同的数据进行修改。 优点:在 row 模式下,bin-log 中可以不记录执行的 SQL 语句的上下文相关的信息,仅仅只需要记录那一条记录被修改了,修改成什么样了。所以 row 的日志内容会非常清楚的记录下每一行数据修改的细节,非常容易理解。而且不会出现某些特定情况下的存储过程或 function ,以及 trigger 的调用和触发无法被正确复制的问题。 缺点:在 row 模式下,所有的执行的语句当记录到日志中的时候,都将以每行记录的修改来记录,这样可能会产生大量的日志内容,比如有这样一条 update 语句: 执行之后,日志中记录的不是这条 update 语句所对应的事件 (MySQL 以事件的形式来记录 bin-log 日志) ,而是这条语句所更新的每一条记录的变化情况,这样就记录成很多条记录被更新的很多个事件。自然,bin-log 日志的量就会很大。尤其是当执行 alter table 之类的语句的时候,产生的日志量是惊人的。因为 MySQL 对于 alter table 之类的表结构变更语句的处理方式是整个表的每一条记录都需要变动,实际上就是重建了整个表。那么该表的每一条记录都会被记录到日志中。 2. Statement 每一条会修改数据的 SQL 都会记录到 master 的 bin-log 中。slave 在复制的时候 SQL 进程会解析成和原来 master 端执行过的相同的 SQL 再次执行。 优点:在 statement 模式下,首先就是解决了 row 模式的缺点,不需要记录每一行数据的变化,减少了 bin-log 日志量,节省 I/O 以及存储资源,提高性能。因为他只需要记录在 master 上所执行的语句的细节,以及执行语句时候的上下文的信息。 缺点:在 statement 模式下,由于他是记录的执行语句,所以,为了让这些语句在 slave 端也能正确执行,那么他还必须记录每条语句在执行的时候的一些相关信息,也就是上下文信息,以保证所有语句在 slave 端杯执行的时候能够得到和在 master 端执行时候相同的结果。另外就是,由于 MySQL 现在发展比较快,很多的新功能不断的加入,使 MySQL 的复制遇到了不小的挑战,自然复制的时候涉及到越复杂的内容,bug 也就越容易出现。在 statement 中,目前已经发现的就有不少情况会造成 MySQL 的复制出现问题,主要是修改数据的时候使用了某些特定的函数或者功能的时候会出现,比如:sleep() 函数在有些版本中就不能被正确复制,在存储过程中使用了 last_insert_id() 函数,可能会使 slave 和 master 上得到不一致的 id 等等。由于 row 是基于每一行来记录的变化,所以不会出现类似的问题。 3. Mixed 从官方文档中看到,之前的 MySQL 一直都只有基于 statement 的复制模式,直到 5.1.5 版本的 MySQL 才开始支持 row 复制。从 5.0 开始,MySQL 的复制已经解决了大量老版本中出现的无法正确复制的问题。但是由于存储过程的出现,给 MySQL Replication 又带来了更大的新挑战。另外,看到官方文档说,从 5.1.8 版本开始,MySQL 提供了除 Statement 和 Row 之外的第三种复制模式:Mixed,实际上就是前两种模式的结合。在 Mixed 模式下,MySQL 会根据执行的每一条具体的 SQL 语句来区分对待记录的日志形式,也就是在 statement 和 row 之间选择一种。新版本中的 statment 还是和以前一样,仅仅记录执行的语句。而新版本的 MySQL 中对 row 模式也被做了优化,并不是所有的修改都会以 row 模式来记录,比如遇到表结构变更的时候就会以 statement 模式来记录,如果 SQL 语句确实就是 update 或者 delete 等修改数据的语句,那么还是会记录所有行的变更。 其他参考信息 除以下几种情况外,在运行时可以动态改变 binlog 的格式: . 存储流程或者触发器中间; . 启用了 NDB; . 当前会话使用 row 模式,并且已打开了临时表; 如果 binlog 采用了 Mixed 模式,那么在以下几种情况下会自动将 binlog 的模式由 statement 模式变为 row 模式: . 当 DML 语句更新一个 NDB 表时; . 当函数中包含 UUID() 时; . 2 个及以上包含 AUTO_INCREMENT 字段的表被更新时; . 执行 INSERT DELAYED 语句时; . 用 UDF 时; . 视图中必须要求运用 row 时,例如建立视图时使用了 UUID() 函数; 设定主从复制模式: 也可以在运行时动态修改 binlog 的格式。例如: 两种模式的对比: Statement 优点 历史悠久,技术成熟; 产生的 binlog 文件较小; binlog 中包含了所有数据库修改信息,可以据此来审核数据库的安全等情况; binlog 可以用于实时的还原,而不仅仅用于复制; 主从版本可以不一样,从服务器版本可以比主服务器版本高; Statement 缺点: 不是所有的 UPDATE 语句都能被复制,尤其是包含不确定操作的时候; 调用具有不确定因素的 UDF 时复制也可能出现问题; 运用以下函数的语句也不能被复制: * LOAD_FILE() * UUID() * USER() * FOUND_ROWS() * SYSDATE() (除非启动时启用了 –sysdate-is-now 选项) INSERT … SELECT 会产生比 RBR 更多的行级锁; 复制须要执行全表扫描 (WHERE 语句中没有运用到索引) 的 UPDATE 时,须要比 row 请求更多的行级锁; 对于有 AUTO_INCREMENT 字段的 InnoDB 表而言,INSERT 语句会阻塞其他 INSERT 语句; 对于一些复杂的语句,在从服务器上的耗资源情况会更严重,而 row 模式下,只会对那个发生变化的记录产生影响; 存储函数(不是存储流程 )在被调用的同时也会执行一次 NOW() 函数,这个可以说是坏事也可能是好事; 确定了的 UDF 也须要在从服务器上执行; 数据表必须几乎和主服务器保持一致才行,否则可能会导致复制出错; 执行复杂语句如果出错的话,会消耗更多资源; Row 优点 任何情况都可以被复制,这对复制来说是最安全可靠的; 和其他大多数数据库系统的复制技能一样; 多数情况下,从服务器上的表如果有主键的话,复制就会快了很多; 复制以下几种语句时的行锁更少: * INSERT … SELECT * 包含 AUTO_INCREMENT 字段的 INSERT * 没有附带条件或者并没有修改很多记录的 UPDATE 或 DELETE 语句 执行 INSERT,UPDATE,DELETE 语句时锁更少; 从服务器上采用多线程来执行复制成为可能; Row 缺点 生成的 binlog 日志体积大了很多; 复杂的回滚时 binlog 中会包含大量的数据; 主服务器上执行 UPDATE 语句时,所有发生变化的记录都会写到 binlog 中,而 statement 只会写一次,这会导致频繁发生 binlog 的写并发请求; UDF 产生的大 BLOB 值会导致复制变慢; 不能从 binlog 中看到都复制了写什么语句(加密过的); 当在非事务表上执行一段堆积的 SQL 语句时,最好采用 statement 模式,否则很容易导致主从服务器的数据不一致情况发生; 另外,针对系统库 MySQL 里面的表发生变化时的处理准则如下: 如果是采用 INSERT,UPDATE,DELETE 直接操作表的情况,则日志格式根据 binlog_format 的设定而记录; 如果是采用 GRANT,REVOKE,SET PASSWORD 等管理语句来做的话,那么无论如何都要使用 statement 模式记录; 使用 statement 模式后,能处理很多原先出现的主键重复问题;
四、mysql创建新记录时,id步增为2解释
这不算个bug,但是step为2感觉浪费id,呵呵~
查看auto_increment变量:
mysql> show variables like '%auto_inc%'; +------------------------------+-------+ | Variable_name | Value | +------------------------------+-------+ | auto_increment_increment | 2 | | auto_increment_offset | 2 | | wsrep_auto_increment_control | ON | +------------------------------+-------+ 3 rows in set (0.01 sec) mysql>
# 查看session变量 mysql> show session variables like '%auto_inc%'; +------------------------------+-------+ | Variable_name | Value | +------------------------------+-------+ | auto_increment_increment | 2 | | auto_increment_offset | 2 | | wsrep_auto_increment_control | ON | +------------------------------+-------+ 3 rows in set (0.01 sec) #查看全局变量 mysql> show global variables like '%auto_inc%'; +------------------------------+-------+ | Variable_name | Value | +------------------------------+-------+ | auto_increment_increment | 2 | | auto_increment_offset | 2 | | wsrep_auto_increment_control | ON | +------------------------------+-------+ 3 rows in set (0.00 sec)
可以看到auto_increment_increment的step是2,可以如下设置成1
#这两种方法等价,mysql重启可能不生效 SET @auto_increment_increment = 1 ; SET session auto_increment_increment=1; #修改全局 SET global auto_increment_increment=1;
那么什么时候会设置offset为2呢?
- auto_increment_offset表示自增长字段从那个数开始,他的取值范围是1 .. 65535
- auto_increment_increment表示自增长字段每次递增的量,其默认值是1,取值范围是1 .. 65535
五、mysql binlog无法自动删除导致磁盘满程序挂掉
最开始机器上的程序一并挂掉,以为是由于重启机器引起的,但是du -sh *发现系统盘大小使用率为100%,原来是磁盘空间不够了。du -sh *逐个从根目录往下查找,发现是/data/mysql/占了18个G
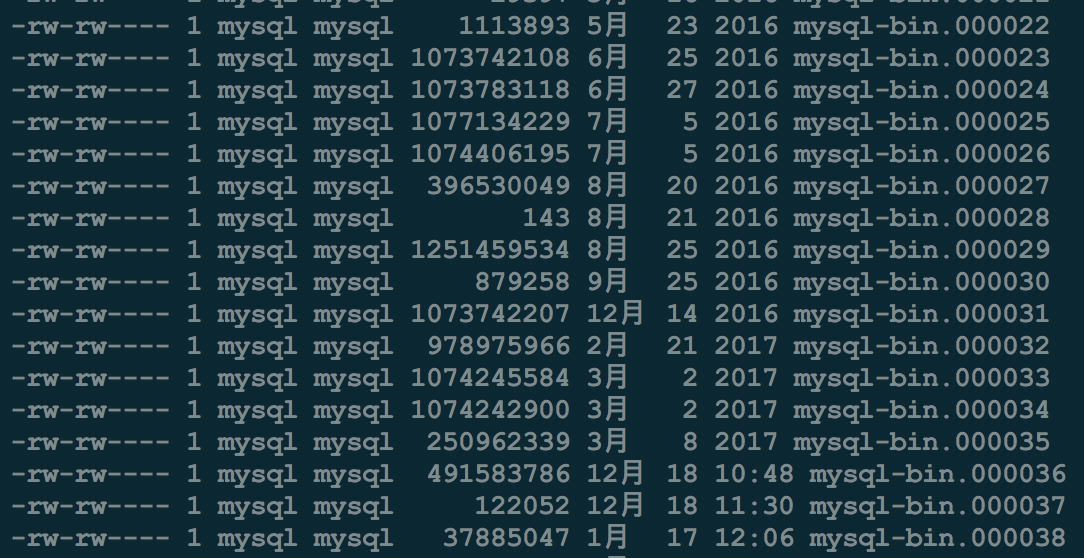
原来是mysql-binlog占用很大空间,删除几个程序恢复运行了。
解决方法:
当开启mysql数据库主从时,会产生大量如mysql-bin.00000* log的文件,这会大量耗费您的硬盘空间。
在/etc/my.cnf中设置expire_logs_days,默认为0,即不清理binlog
1.查看binlog过期时间:
show global variables like 'expire_logs_days'; +------------------+-------+ | Variable_name | Value | +------------------+-------+ | expire_logs_days | 0 | +------------------+-------+ 1 row in set (0.01 sec)
2.查看binlog最大值设置,大小为512M。
show variables like 'max_binlog_size'; +-----------------+-----------+ | Variable_name | Value | +-----------------+-----------+ | max_binlog_size | 536870912 | +-----------------+-----------+ 1 row in set (0.00 sec)
3.查看binlog文件
show binary logs; +------------------+------------+ | Log_name | File_size | +------------------+------------+ | mysql-bin.000004 | 536872787 | | mysql-bin.000005 | 536873559 | | mysql-bin.000006 | 536872037 | | mysql-bin.000007 | 536871022 | ....
sql的binlog自动删除发生在:
1.手工执行flush logs;
2.binlog文件大小超过max_binlog_size的设置大小;
3.重启mysql
手工删除binlog方法:
方法一:
purge binary logs to 'binlog.000058'; ----(删除mysql bin-log日志,删除binlog.000058之前的,不包括binlog.000058)
方法二:
PURGE binary LOGS BEFORE '2008-06-22 13:00:00'; //清除2008-06-22 13:00:00前binlog日志
PURGE binary LOGS BEFORE DATE_SUB( NOW( ), INTERVAL 3 DAY); //清除3天前binlog日志BEFORE,变量的date自变量可以为'YYYY-MM-DD hh:mm:ss'格式。
六、failed with error number 1065 Query was empty SQL
待更新..
参考:
https://blog.csdn.net/zengxuewen2045/article/details/52995916
