1.1为什么是ML策略
(1)当对一个实际的应用系统进行优化时,可能有很多想法:如提高数据量,提高网络深度,正则化等等,一个错误的选择可能浪费非常多的时间,本课就是让你在面对很多选择时做出正确的选择,这就是ML策略。提高效率,让你的深度学习系统更快投入使用。
1.2正交化
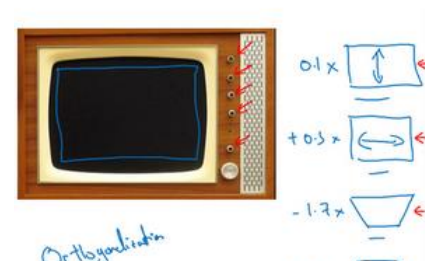
(1)使用以下的老式电视机来说明什么是正交化,即一个按钮只调节宽度(不会对其他造成影响),一个只调节高度,一个只调节角度,这样就可以很容易的讲画面调节到正中央,如果一个按钮既影响高度有影响角度,那么将非常难调整。
(2)同样在机器学习系统中,可能出现测试集效果好,验证集效果不好,这时如果有一个策略可以改善这个,同时不影响其他的东西,那就是正交化;又比如为什么不推荐使用early stopping,因为它一方面改善了过拟合,但是会使得训练集拟合变得不那么好,所以这个策略不是正交化。下图是深度学习系统各阶段可能出现的问题,应该找到一可以改善它而不影响其他性能的策略(即正交化的策略)。

1.3单一数字评价指标
(1)F1分数公式:2(RP)/(R+P);其中P是查准率,R是查全率。
1.4满足和优化指标
(1)当有N个指标时,选出其中一个最想优化的指标来最小化,其余N-1个指标作为满足指标,即在满足满足指标的前提下(如运算速度要小于100ms),选择优化指标最好的模型。
1.5训练、开发和测试集划分
(1)记住一点:务必让开发集和测试集是同分布,否则训练好的网络其实没什么用。
(2)设置好单一评估的开发集,就像是一个靶心,优化的过程就是去瞄准靶心,然后瞄的很准之后,测试集和开发集不同分布就相当于把靶心换到其他位置了,所以效果会非常的差。如下图所示(靶心变了)。

1.6开发集和测试集的大小
(1)在大数据时代,70/30、60/20/20的分法已经不再适用了,现在流行把大把数据拿去训练,只要留有足够的开发集和测试集就行。这里开发集足够的标准是可以判断出哪个模型好,然后这里测试集足够的标准是可以准确评估最终的成本偏差。
1.7什么时候该改变开发/测试集和指标
(1)总体方针:如果你当前的指标和当前用来评估的数据和你真正关心必须做好的事情关系不大是,这时候就应该更改你的指标或者你的开发集了,让它们能更好的反应你的算法需要处理好的数据。
(2)案例1:A、B模型的误差分别为3%、5%,根据指标看A更好,但是在使用过程中发现A会把情色照片推送给用户,B不会,显然这种情况下其实B是更好的算法,这时说明需要修改评价标准如修改代价函数:
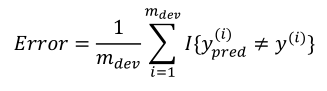
改成:
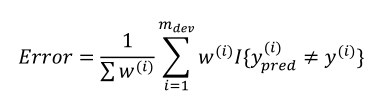
当把色情照片推送给用户时给予很大的权重,这样根据新的指标可以选出B算法是更好的,这样就与实际符合了。
(3)案例2:开发集、测试集都是使用网上的高清猫的照片,A、B模型的误差分别为3%、5%,根据指标A更好,而实际需要分类的是来自普通用户拍摄的低像素模糊的照片,这时B算法表现的更好,出现这种情况说明要更改开发集、测试集了,使其与实际中的照片更加接近。
(4)在上面提到的各种方法中,其实已经不自觉的使用了正交化,即每种修改只影响一个方面,对其他不造成影响。
1.8为什么是人的表现
(1)当性能低于人类的表现时可以提高的很快,但是超过人类的表现之后,性能的提升将会变慢。如下图所示
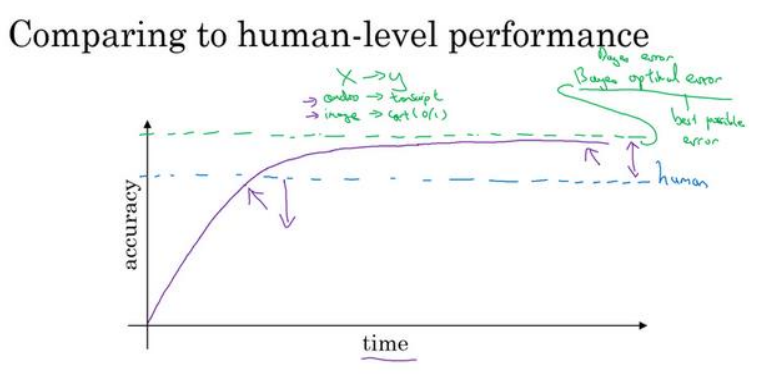
(2)把性能的极限(即模型可能达到的最高性能)称为贝叶斯最优错误率(Bayes optimal error)。
(3)超过人类表现之后性能提高变慢主要有两个原因:首先因为超过人类之后说明已经快接近贝叶斯极限了,进步的空间本身就小了;其次是因为超过人类之后,很多的工具将不再能起作用,如低于人类表现时人类还可以帮忙做误差分析。
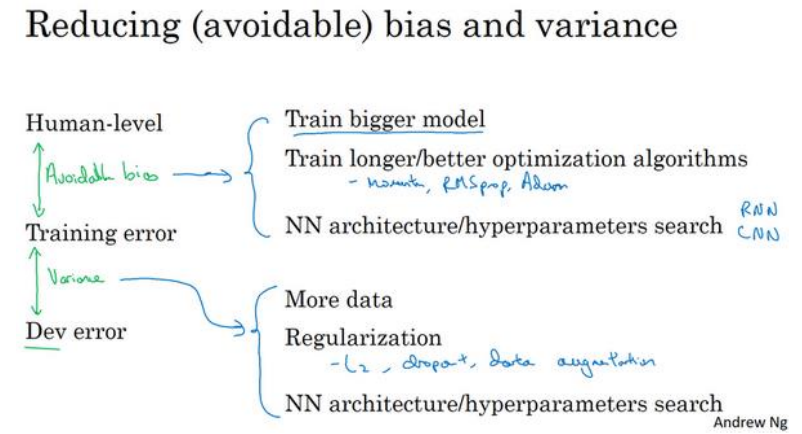
1.9可避免的偏差
(1)在计算机视觉中,人类是非常擅长的,人类的表现和贝叶斯最优误差相差不大,可把前者当做后者。
(2)把测试集误差减去人类的误差称为可避免误差,这是可以提高的部分,下如图:同样的训练误差和开发集误差,但是根据人类的表现不同,需优先优化的也不同,左边应先降低偏差,右边应该先降低方差(因为8%-7.5%已经很小了):

(3)开发集误差减去训练集误差叫可避免方差。
1.10理解人的表现
(1)案例:医学图像分类,普通人3%错误率,……,专家组讨论结果能达到0.5%,这时应该把最好的表现来当做人类的表现。

(2)在实际应用中,不一定要达到人类的最高水平才能投入使用,比如一个系统超过了普通放射科医生的水平,这时这个系统就应该可以投入使用;所以这也说明不同情况下,定义人类的水平错误率时,要弄清楚目标在哪里(不一定是最高的人类水平),超过这个目标就应该可以拿来用。
1.11超过人类的表现
(1)在结构化问题上,如电影推荐等,机器远超人类水平。
(2)在计算机视觉,语音识别等也达到和超过人类的水平。
(3)在自然感知方面还有待加强。
1.12改善你模型的表现
(1)降低偏差和方差的策略如下图所示:
降低偏差:更大更深的模型,更长的训练,其他的优化方法,更换网络结构
降低方差:更多的数据、正则化、dropout、数据增强、提前终止(不推荐使用)、更换网络