几周前,我读了一篇名为“ Good Code vs Go Code中的错误代码 ”的文章,作者指导我们逐步完成实际业务用例的重构。
本文的重点是将“坏代码”转变为“良好代码”:更具惯用性,更易读,利用go语言的细节。但它也坚持将性能作为项目的一个重要方面。这引发了我的好奇心:让我们深入挖掘!
该程序基本上读取一个输入文件,并解析每一行以填充内存中的对象。
$ go test -bench =。
因此,在我的机器上,“好代码”的速度提高了16%。我们能获得更多吗?
根据我的经验,代码质量和性能之间存在有趣的关联。当您成功地重构代码以使其更清晰且更加分离时,您通常最终会使其更快,因为它不会使之前执行的无关指令变得混乱,并且还因为一些可能的优化变得明显且易于实现。
另一方面,如果你进一步追求性能,你将不得不放弃简单并诉诸于黑客。你确实会刮掉几毫秒,但代码质量会受到影响,因为它会变得更难以阅读和推理,更脆弱,更不灵活。
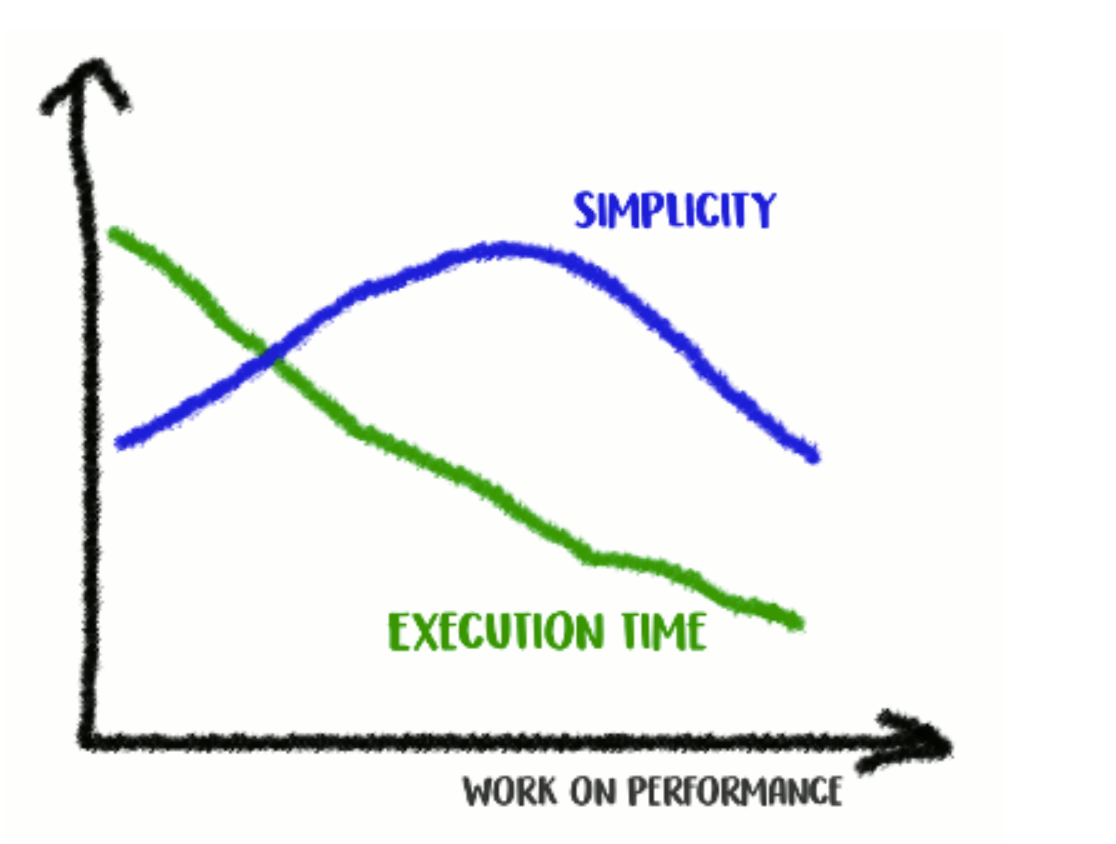
这是一个权衡:你愿意走多远?
为了正确确定您的绩效工作的优先顺序,最有价值的策略是确定您的瓶颈并专注于它们。要实现这一点,请使用分析工具!Pprof和Trace是你的朋友:
$ go test -bench =。-cpuprofile cpu.prof
$ go tool pprof -svg cpu.prof> cpu.svg
$ go test -bench =。-trace trace.out
$ go工具跟踪trace.out
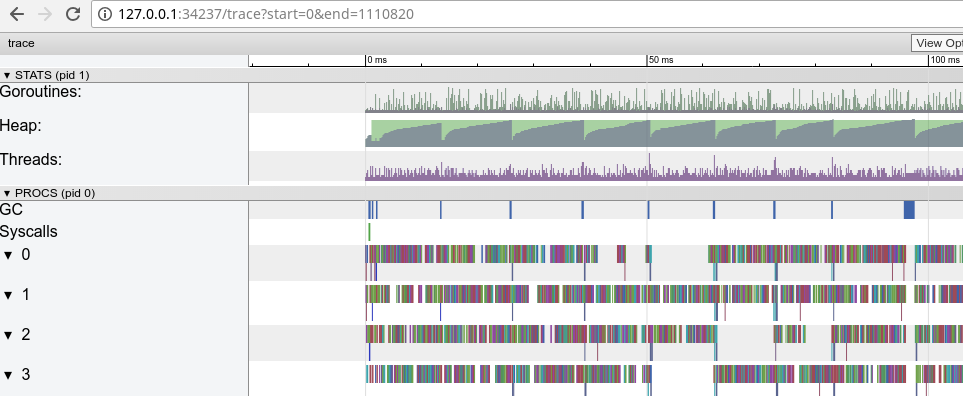
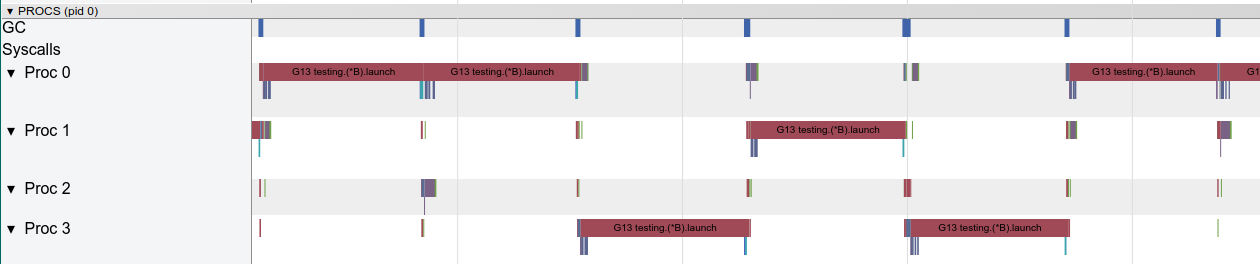
跟踪证明使用了所有CPU内核(底线0,1等),这在一开始看起来是件好事。但它显示了数千个小的彩色计算切片,以及一些空闲插槽,其中一些核心处于空闲状态。我们放大:

每个核心实际上花费大量时间闲置,并在微任务之间保持切换。看起来任务的粒度不是最优的,导致许多上下文切换以及由于同步而导致的争用。
让我们检查一下竞争检测器是否同步是正确的(如果没有,那么我们的问题比性能更大):
$ go test -race
PASS
是!!看起来是正确的,没有遇到数据争用情况。测试函数和基准函数是不同的(参见文档),但在这里他们调用相同的函数ParseAdexpMessage,我们可以使用-race。
“好”版本中的并发策略包括在其自己的goroutine中处理每行输入,以利用多个核心。这是一种合法的直觉,因为goroutines的声誉是轻量级和廉价的。我们多少得益于并发性?让我们与单个顺序goroutine中的相同代码进行比较(只需删除行解析函数调用之前的go关键字)

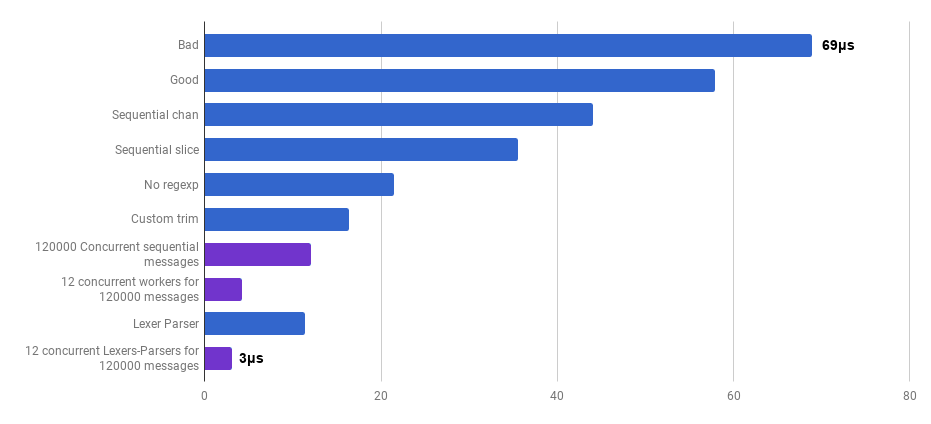
哎呀,没有任何并行性,它实际上更快。这意味着启动goroutine的(非零)开销超过了同时使用多个核心所节省的时间。
自然的下一步,因为我们现在顺序而不是同时处理行,是为了避免使用结果通道的(非零)开销:让我们用裸片替换它。
我们现在从“好”版本获得了大约40%的加速,只是简化了代码,删除了并发(差异)。
现在让我们看一下Pprof图中的热函数调用:
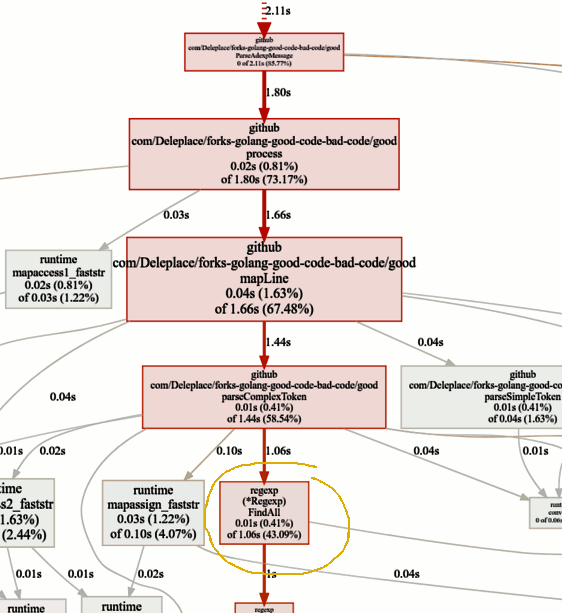
我们当前版本的基准(顺序,带切片)花费86%的时间实际解析消息,这很好。我们很快注意到,总时间的43%用于将正则表达式与(* Regexp).FindAll匹配 。
虽然regexp是从原始文本中提取数据的一种方便灵活的方法,但它们存在缺陷,包括内存和运行时的成本。它们很强大,但对于许多用例来说可能有点过分。
在我们的程序中,模式
patternSubfield =“ - 。[^ - ] *”
主要用于识别以短划线“ - ” 开头的“ 命令 ”,并且一行可能有多个命令。通过一些调整,可以使用bytes.Split完成。让我们调整代码(commit,commit)以使用Split替换regexp:
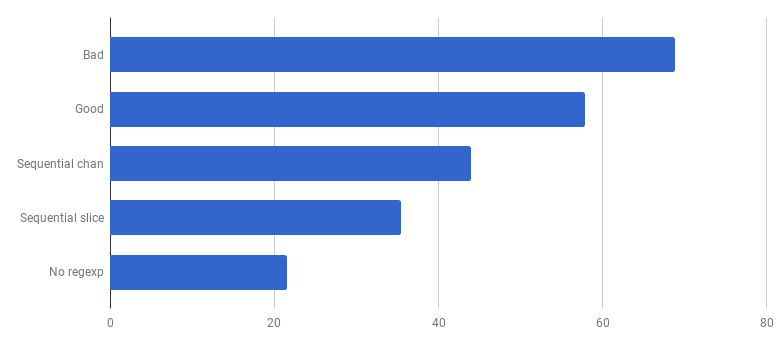
哇,这是40%的额外增益!
CPU图现在看起来像这样:
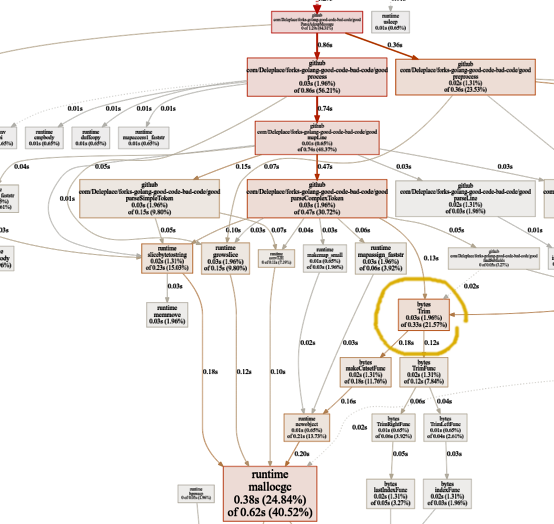
没有更多正则表达式的巨大成本。从5个不同的功能中分配内存花费了相当多的时间(40%)。有趣的是,总时间的21%现在由字节占.Trim 。

bytes.Trim期望一个“ cutset string”作为参数(对于要在左侧和右侧删除的字符),但我们仅使用单个空格字节作为cutset。这是一个例子,您可以通过引入一些复杂性来获得性能:实现您自己的自定义“trim”函数来代替标准库函数。在自定义的“微调”的交易,只有一个割集字节。

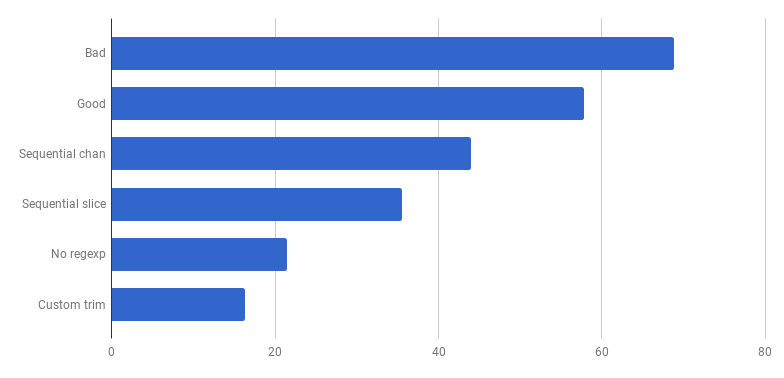
是的,另外20%被削减了。当前版本的速度是原始“坏”速度的4倍,而机器只使用1个CPU内核。相当实质!
之前我们放弃了在线处理级别的并发性,但是通过并发更新仍然存在改进的空间,并且具有更粗略的粒度。例如,在每个文件在其自己的goroutine中处理时,处理6,000个文件(6,000条消息)在我的工作站上更快:
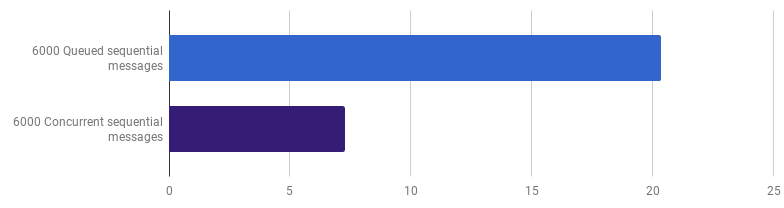
66%的胜利(即3倍的加速),这是好的但“不是那么多”,因为它利用了我所有的12个CPU内核!这可能意味着使用新的优化代码,处理整个文件仍然是一个“小任务”,goroutine和同步的开销不可忽略不计。
有趣的是,将消息数量从6,000增加到120,000对顺序版本的性能没有影响,并且降低了“每个消息的1个goroutine”版本的性能。这是因为启动大量的goroutine是可能的,有时是有用的,但它确实给go运行时调度程序带来了一些压力。
我们可以通过仅创建少数工作人员来减少执行时间(不是12倍因素,但仍然是这样),例如12个长期运行的goroutine,每个goroutine处理一部分消息:
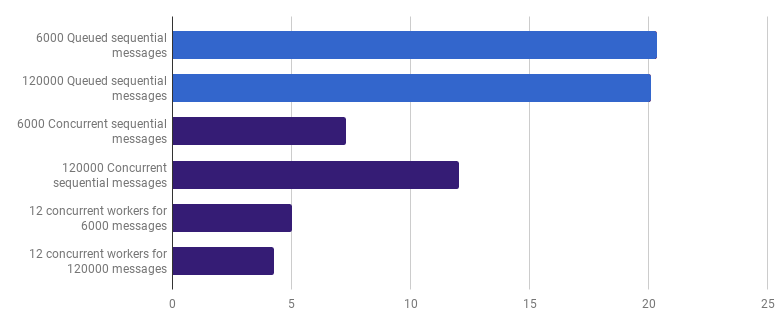
与顺序版本相比,大批消息的调优并发性删除了79%的执行时间。请注意,只有在确实要处理大量文件时,此策略才有意义。
所有CPU核心的最佳利用包括几个goroutine,每个goroutine处理相当数量的数据,在完成之前没有任何通信和同步。
选择与可用CPU核心数相等的多个进程(goroutine)是一种常见的启发式方法,但并不总是最佳:您的里程可能会根据任务的性质而有所不同。例如,如果您的任务从文件系统读取或发出网络请求,那么性能比CPU核心具有更多的goroutine是完全合理的。
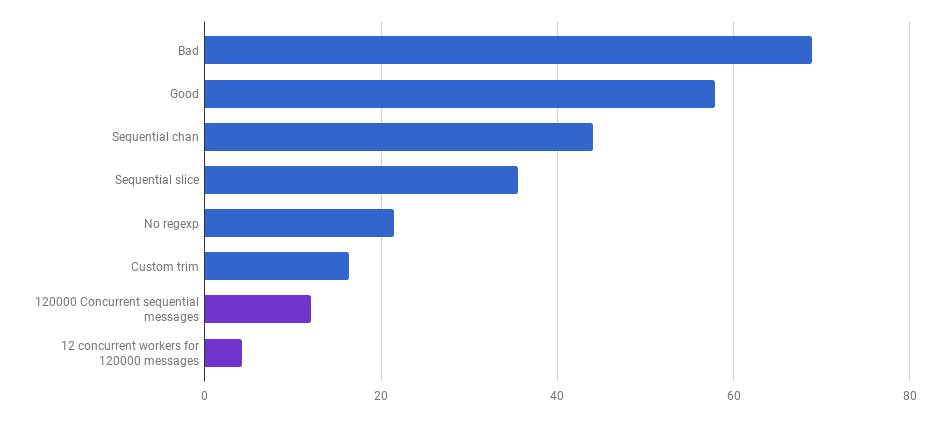
我们已经达到了这样的程度,即通过本地化增强很难提高解析代码的效率。现在,执行时间由小对象(例如Message结构)的分配和垃圾收集主导,这是有道理的,因为已知内存管理操作相对较慢。进一步优化分配策略......留给狡猾的读者练习。
这就是今天,我希望你喜欢这个旅程。以下是一些免责声明和外卖:
- 可以使用不同的技术在多个抽象级别上提高性能,并且增益是乘法的。
- 首先调整高级抽象:数据结构,算法,适当的解耦。稍后调整低级抽象:I / O,批处理,并发,stdlib使用,内存管理。
- Big-O分析是基础,但通常不是使给定程序运行得更快的相关工具。
- 基准测试很难。使用分析和基准来发现瓶颈并深入了解您的代码。请记住,基准测试结果并不是最终用户在生产中遇到的“真实”延迟,并且将这些数字与盐分相提并论。
- 幸运的是,工具(Bench,Pprof,Trace,Race detector,Cover)使性能探索变得平易近人且令人兴奋。
- 编写好的相关测试并非易事。但它们非常珍贵,可以帮助“保持正常”,即重构,同时保留原始的正确性和语义。
- 花一点时间问问自己“足够快”的速度有多快。不要浪费时间过度优化一次性脚本。考虑到优化伴随着成本:工程时间,复杂性,错误,技术债务。
- 在模糊代码之前要三思而后行。
- Ω(n²)及以上的算法通常很昂贵。
- O(n)或O(n log n)或更低的复杂度通常很好。
- 的隐性因素是不容忽视的!例如,文章中的所有改进都是通过降低这些因素来实现的,而不是通过改变算法的复杂性类来实现的。
- I / O通常是一个瓶颈:网络请求,数据库查询,文件系统。
- 正则表达式往往是比实际需要更昂贵的解决方案。
- 内存分配比计算更昂贵。
- 堆栈中的对象比堆中的对象便宜。
- 切片可用作替代昂贵的重新分配的替代方案。
- 字符串对于只读使用(包括重新设置)是有效的,但对于任何其他操作,[]字节更有效。
- 内存局部性很重要(CPU缓存友好性)。
- 并发和并行是很有用的,但要正确起来很棘手。
- 当挖掘更深层次和更低层次时,有一个“玻璃地板”,你真的不想在其中突破。如果你渴望asm指令,内在函数,SIMD ...也许你应该考虑去做原型,然后切换到低级语言来充分利用硬件和每纳秒!




